前言
本章导图:
2.1 Netfilter的文件结构
Netfilter是第三代Linux防火墙,在它之前有Ipfwadm和Ip chains,但Netfilter与Linux本身是两个相互独立的组织。
Netfilter以模块形式存在于Linux内核中:
+-------------------------+
| Application |
+-------------------------+
| Kernel |
| +-> (Netfilter) ->-+ |
+--|------------------|---+
| | Hardware | |
| eth0 eth1 |
+--|------------------|---+
in | | out
-->+ +--->
在2.6.14版本的内核之前,针对IPv4和IPv6的模块被分别放在以下路径:
/lib/modules/`uname -r`/kernel/net/ipv4/netfilter
/lib/modules/`uname -r`/kernel/net/ipv6/netfilter
从2.6.14开始,它们被逐渐整合成协议无关的模块,并放在以下路径:
/lib/modules/`uname -r`/kernel/net/netfilter
模块举例如下:
ls /lib/modules/`uname -r`/kernel/net/netfilter
ipset nft_log.ko.xz xt_LED.ko.xz
ipvs nft_masq.ko.xz xt_length.ko.xz
nf_conntrack_amanda.ko.xz nft_meta.ko.xz xt_limit.ko.xz
nf_conntrack_broadcast.ko.xz nft_nat.ko.xz xt_LOG.ko.xz
nf_conntrack_ftp.ko.xz nft_queue.ko.xz xt_mac.ko.xz
...
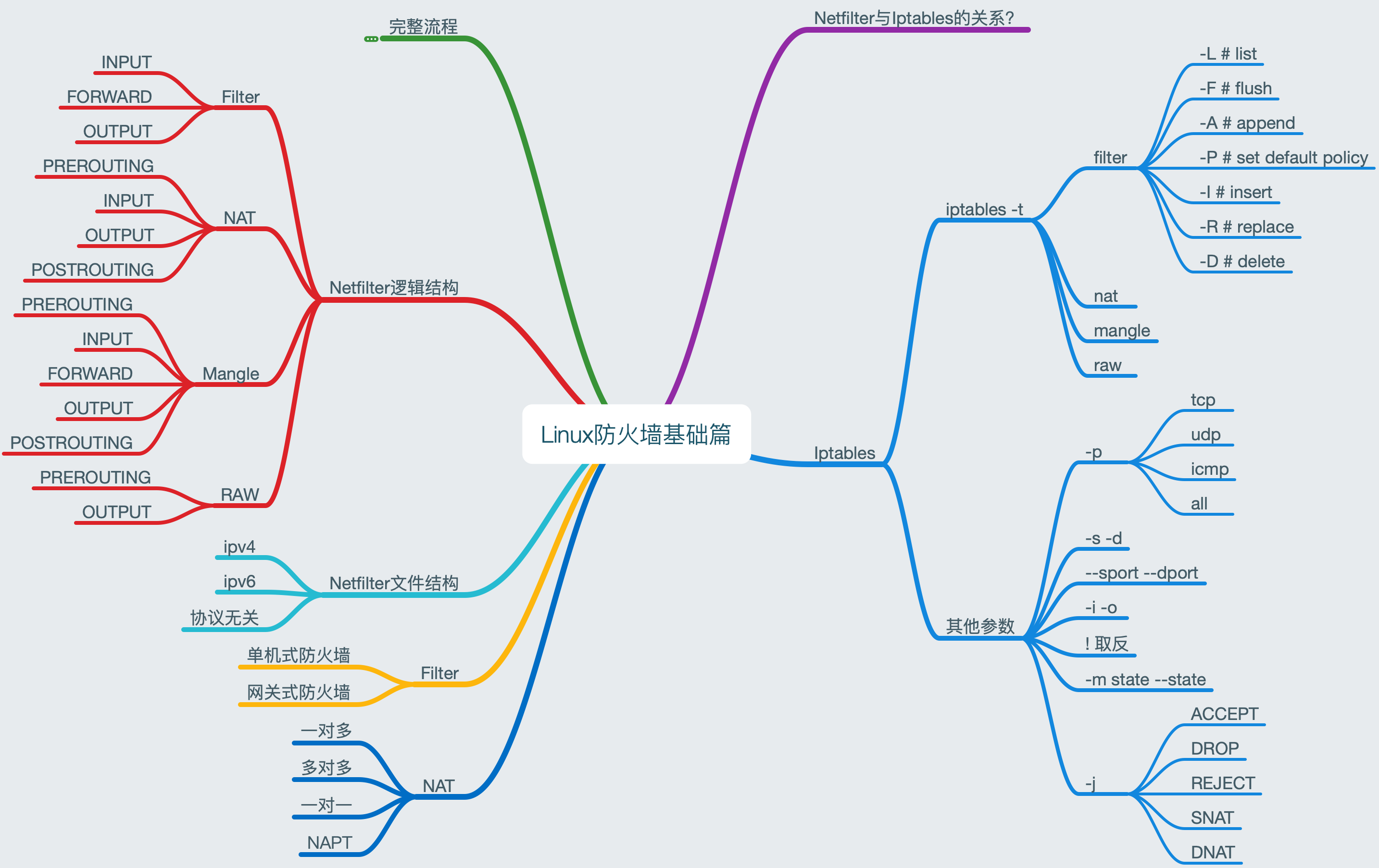
2.2 Netfilter的逻辑结构
上面讲到的不同模块将会提供不同的匹配过滤功能,但具体要不要过滤、怎么过滤,需要我们为Netfilter制定符合目的的规则(与用户交互并接受规则的是iptables,后面会讲到)。这些规则会被装填到一块结构性内存中四个不同的表内:Filter、NAT、Mangle和RAW(每个表有不同的规则链),这正是Netfilter提供的四大功能:
它们的用途简述如下:
- Filter:封包过滤
- NAT:顾名思义
- Mangle:修改封包内容
- RAW:为封包穿越防火墙加速,提升防火墙性能
2.3 Netfilter的Filter机制
毋庸置疑,Filter是Netfilter最重要的功能。该机制对于封包有如下分类:
- INPUT类:指网络上其他主机发给本机进程的封包
- OUTPUT类:指本机进程发给其他主机的封包
- FORWARD类:指网络上其他主机发给其他主机的封包,本机在其中扮演路由器角色
Filter表包含与分类同名的三条规则链,其中的规则将作用于对应类型的封包:

而规则本身正是需要我们去设计的。举例来说,如果我们要限制本机访问外部的Web服务,那么可以向OUTPUT链中写入一条”丢弃本机进程产生的、目的地为XXX-URL、协议为TCP且端口为80的封包“。
Filter机制的逻辑流程如下:
Packet-IN ---> ROUTING-TABLE ---> FORWARD-CHAIN --+
| |
V |
INPUT-CHAIN +-> ROUTING-TABLE |
| | | |
V | V |
LOCAL-PROCESS -+ OUTPUT-CHAIN |
| |
V |
Packet-OUT <--------------------------------------+
上图中的ROUTING-TABLE实际上是同一个。对上述流程做如下解释:
- 进入的封包先由路由表判断是INPUT还是FORWARD类型,接着被分派给不同的规则链处理。若INPUT链放行,则封包被交给本机进程,否则丢弃;若FOWARD链放行,则封包从另一个网络接口被送出,否则丢弃
- 本机发出的封包会先经过路由表决定路由,然后被OUTPUT链处理,若放行则从路由表指定的接口被送出,否则丢弃
那么,具体的规则匹配方式是怎样的呢?
举例来说,当我们向INPUT链添加规则时,先添加规则被放在前面,后添加规则被放在后面(队列结构)。Netfilter采用优先匹配原则,从链头到链尾依次对封包应用规则,一旦某规则生效,不再进行后续匹配。如果我们添加的所有规则都没能匹配成功,则链尾的Default Policy将作用于封包。该缺省规则永远位于链尾,不同链的缺省规则相互独立。缺省规则可以是两个值之一:ACCEPT或DROP。
2.4 Netfilter与Iptables
前面有提到Iptables。准确来说,它是“规则编辑工具”,用来对内存中的规则进行增删改查。针对IPv4和IPv6,分别有iptables和ip6tables两个工具。
Linux防火墙的完整称呼应该是“Netfilter/Iptables”。与Netfilter类似,Iptables也是模块化存储的。在我的环境中,模块存储路径为/usr/lib64/xtables:
ls /usr/lib64/xtables
libip6t_ah.so libipt_unclean.so libxt_nfacct.so
libip6t_DNAT.so libxt_addrtype.so libxt_NFLOG.so
libip6t_DNPT.so libxt_AUDIT.so libxt_NFQUEUE.so
libip6t_dst.so libxt_bpf.so libxt_NOTRACK.so
libip6t_eui64.so libxt_cgroup.so libxt_osf.so
libip6t_frag.so libxt_CHECKSUM.so libxt_owner.so
...
Iptables的模块与Netfilter的模块往往是一对一地存在。例如,在Netfilter模块目录中有xt_string.ko.xz,对应地,在Iptables路径下则有libxt_string.so。当我们下达与xt_string.ko有关的规则时,Iptables将依赖libxt_string.so去检查语法正确性,并加载xt_string.ko模块,最后写入规则到内存。因此,应该同时升级Netfilter与Iptables。
Netfilter官方网站对两者的描述如下:
netfilter is a set of hooks inside the Linux kernel that allows kernel modules to register callback functions with the network stack. A registered callback function is then called back for every packet that traverses the respective hook within the network stack.
iptables is a generic table structure for the definition of rulesets. Each rule within an IP table consists of a number of classifiers (iptables matches) and one connected action (iptables target).
netfilter, ip_tables, connection tracking (ip_conntrack, nf_conntrack) and the NAT subsystem together build the major parts of the framework.
2.5 Iptables的使用方法
我们来分析一下Iptables的命令结构。输入iptables -h,得到:
iptables v1.4.21
Usage: iptables -[ACD] chain rule-specification [options]
iptables -I chain [rulenum] rule-specification [options]
...
Commands:
Either long or short options are allowed.
--append -A chain Append to chain
...
Options:
--ipv4 -4 Nothing (line is ignored by ip6tables-restore)
--table -t table table to manipulate (default: `filter')
...
可以发现,Iptables命令基本由“Command”与“Option”两部分构成。
我们可以借助思维导图来整理重要参数:
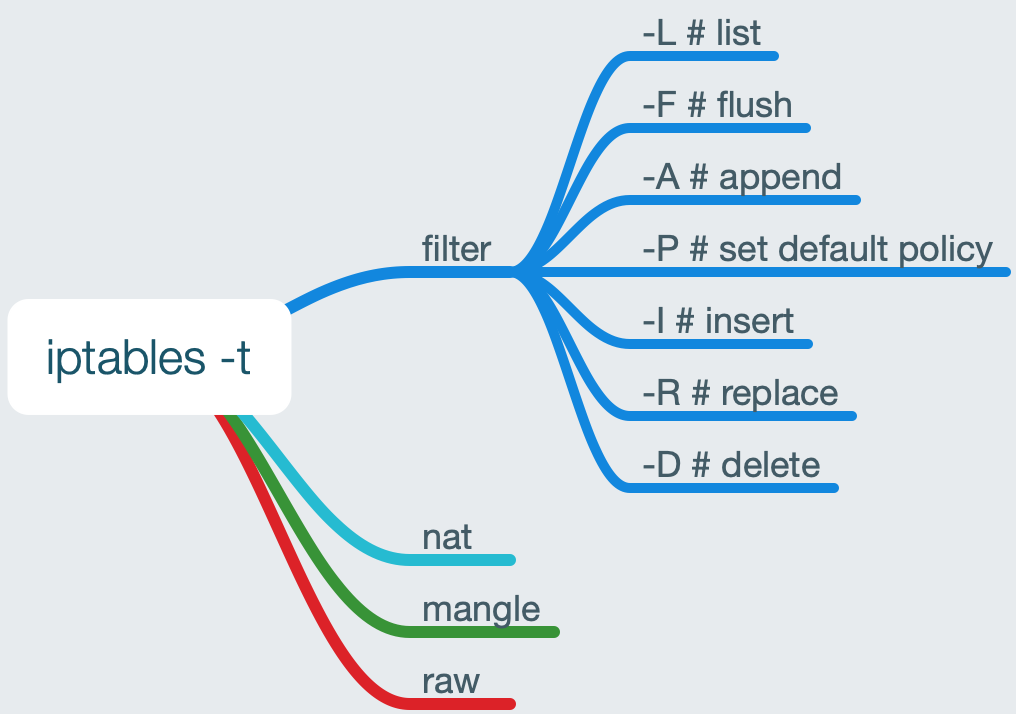
一些参数具有缺省值,如-t的缺省值为filter。而右上方的操作,无外乎增删改查。
另外,我们先给出三个规则示例,以方便测试。暂不去理会其内涵,后面再详述:
-p tcp -j ACCEPT
-p udp -j ACCEPT
-p icmp -j ACCEPT
现在,我们整合上述信息,执行一些iptables操作:
iptables -t filter -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
ACCEPT icmp -- anywhere anywhere
ACCEPT all -- anywhere anywhere
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
Chain FORWARD (policy ACCEPT)
target prot opt source destination
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
iptables -t filter -L FORWARD
Chain FORWARD (policy ACCEPT)
target prot opt source destination
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
上述规则都很好理解。
来做一次清空操作,并添加一个新的INPUT规则:
iptables -t filter -F
iptables -t filter -A INPUT -p icmp -j ACCEPT
iptables -t filter -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT icmp -- anywhere anywhere
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
将FORWARD的缺省规则设为DROP:
iptables -t filter -P FORWARD DROP
iptables -t filter -L FORWARD
Chain FORWARD (policy DROP)
target prot opt source destination
注意,-F删除操作不会影响缺省规则。
其他参数可以自行组合尝试,很简单:
iptables -t filter -I INPUT 2 -p tcp -j ACCEPT
iptables -t filter -R INPUT 2 -p tcp -j ACCEPT
iptables -t filter -D INPUT 2
我们可以将所学迁移到别的表中:
iptables -t nat -L
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
2.6 Iptables的语法
在简单尝试后,我们来看一下iptables的语法。它可以分为“基本语法”与“高级语法”,区别为是否使用了基本模块iptable_filter.ko之外的模块的功能(在我的环境中,这个基本模块目前还是位于IPv4的目录:net/ipv4/netfilter/iptable_filter.ko.xz)。
下面分别是一个基本语法和一个高级语法的例子:
iptables -t filter -A INPUT -p icmp -j DROP
iptables -t filter -A INPUT -m mac --mac-source 00:E0:18:00:7C:A4 -j DROP
不同模块的语法会有一些差异。本章后面通过示例介绍基本语法。对于容易理解的语法,将不再介绍其内涵。
例1:实验
iptables -A INPUT -p icmp -s 172.16.56.1 -j DROP
我们先清空规则表,然后让172.16.56.1去不中断地ping它,再执行上述命令,发现ping发生变化:
ping 172.16.56.138
PING 172.16.56.138 (172.16.56.138): 56 data bytes
64 bytes from 172.16.56.138: icmp_seq=0 ttl=64 time=0.726 ms
...
64 bytes from 172.16.56.138: icmp_seq=15 ttl=64 time=0.528 ms
64 bytes from 172.16.56.138: icmp_seq=16 ttl=64 time=0.601 ms
64 bytes from 172.16.56.138: icmp_seq=17 ttl=64 time=0.321 ms
64 bytes from 172.16.56.138: icmp_seq=18 ttl=64 time=0.608 ms
Request timeout for icmp_seq 19
Request timeout for icmp_seq 20
Request timeout for icmp_seq 21
^C
--- 172.16.56.138 ping statistics ---
23 packets transmitted, 19 packets received, 17.4% packet loss
round-trip min/avg/max/stddev = 0.321/0.593/0.827/0.138 ms
例1:延伸
-p icmp-p tcp-p udp-p all-s 172.16.56.0/24-d www.baidu.com-j ACCEPT-j DROP(丢弃封包且不给src回应)-j REJECT(丢弃封包并返回dst不可达的ICMP报文给src)
使用REJECT的效果:
ping 172.16.56.138
PING 172.16.56.138 (172.16.56.138): 56 data bytes
92 bytes from 172.16.56.138: Destination Port Unreachable
Vr HL TOS Len ID Flg off TTL Pro cks Src Dst
4 5 00 5400 9ca7 0 0000 40 01 1556 172.16.56.1 172.16.56.138
例2:实验
iptables -A INPUT -p udp -s 172.16.56.1 --dport 10000 -j REJECT
先清空规则列表,然后在138上监听:
nc -u -l 10000
去尝试通信,接着输入规则,结果如下:
ncat -u 172.16.56.138 10000
hello
hello
Ncat: Connection refused.
例2:延伸
--dport--sport(指定端口前要-p指定协议)
例3
iptables -A INPUT -p tcp -s 172.16.56.1 --dport 23 -j ACCEPT
iptables -A INPUT -p all -s 172.16.56.0/24 -d 172.16.56.138 -j ACCEPT
iptables -A INPUT -p tcp -i ens33 --dport 22 -j ACCEPT
例3:延伸
-i-o匹配封包出入口
例4:实验
借助!来对限制条件取反:
iptables -A OUTPUT -o ens33 -p tcp ! -d www.hao123.com --dport 80 -j REJECT
执行后,可以看一下结果:
wget www.hao123.com &> log.dat
cat log.dat | grep "awaiting response" | tail -n 1
HTTP request sent, awaiting response... 200 OK
wget www.baidu.com &> log.dat
cat log.dat
--2018-12-19 16:41:53-- http://www.baidu.com/
Resolving www.baidu.com (www.baidu.com)... 115.239.210.27, 115.239.211.112
Connecting to www.baidu.com (www.baidu.com)|115.239.210.27|:80... failed: Connection refused.
Connecting to www.baidu.com (www.baidu.com)|115.239.211.112|:80... failed: Connection refused.
将上例稍稍改变一下,就可以作为网关,限制内网主机访问外部其他网站:
iptables -A FORWARD -i eth1 -o ens33 -p tcp ! -d www.hao123.com --dport 80 -j REJECT
例4:延伸
!放在哪是个有趣的问题。一开始我和书中一样,放在-d与www.hao123.com之间,但这样会报错
2.7 借助Filter机制构建单机式防火墙
从本节开始,我们来尝试给出规则去构建一系列的防火墙。
构建防火墙的步骤:
- 列出所有要求
- 根据要求生成规则
构建防火墙的原则:
“先拒绝所有的连接,再逐一开放对外提供的服务。”
网络拓扑如下:
Net: 172.16.56.0/24
PC1: 172.16.56.1
PC2: 172.16.56.164
PC3: 172.16.56.138
在PC3上构建单机防火墙,要求:
- 网段下任何主机都可访问PC3上除SSH以外的服务
- 网段下只有PC1可访问PC3上的所有服务(25/80/110端口)
按照前述的原则与要求,我们构建以下规则:
iptables -P INPUT DROP
iptables -A INPUT -p tcp -s 172.16.56.0/24 -d 172.16.56.138 --dport 25 -j ACCEPT
iptables -A INPUT -p tcp -s 172.16.56.0/24 -d 172.16.56.138 --dport 80 -j ACCEPT
iptables -A INPUT -p tcp -s 172.16.56.0/24 -d 172.16.56.138 --dport 110 -j ACCEPT
iptables -A INPUT -p tcp -s 172.16.56.1 -d 172.16.56.138 --dport 22 -j ACCEPT
现在我们看一下执行结果:
iptables -L INPUT
Chain INPUT (policy DROP)
target prot opt source destination
ACCEPT tcp -- 172.16.56.0/24 localhost.localdomain tcp dpt:smtp
ACCEPT tcp -- 172.16.56.0/24 localhost.localdomain tcp dpt:http
ACCEPT tcp -- 172.16.56.0/24 localhost.localdomain tcp dpt:pop3
ACCEPT tcp -- 172.16.56.1 localhost.localdomain tcp dpt:ssh
测试一下:
# 172.16.56.1
ssh centos@172.16.56.138 -o ConnectTimeout=5
centos@172.16.56.138's password:
Last login: Thu Dec 20 10:31:00 2018 from 172.16.56.1
[centos@localhost ~]$
# 172.16.56.164
ssh centos@172.16.56.138 -o ConnectTimeout=5
ssh: connect to host 172.16.56.138 port 22: Connection timed out
注意,上面的测试是不完全的。真正在部署防火墙时,要基于逻辑来对所有条件分支进行覆盖性测试。
现在来讨论四个问题:
一、为什么iptables -L有时会变得很慢?
这是因为iptables默认会对IP和端口进行反向解析。可以通过iptables -L -n禁止解析来加快显示。
二、PC1用SSH连接PC3时,虽然连接成功,但耗时比过去长不少,这是为什么?
该问题涉及到TCP的连接状态,我将在下一个问题中解答。
三、在现有规则下,PC3能够用SSH去连接其他主机的SSH服务吗?
不可以。例如,我们尝试访问PC2上的sshd:
ssh seed@172.16.56.164 -o ConnectTimeout=5
ssh: connect to host 172.16.56.164 port 22: Connection timed out
其实道理很简单,发出的包经过OUTPUT的缺省规则ACCEPT,能够抵达PC2,但PC2返回的包却被挡在防火墙外。我们可以借助xt_state.ko模块(该模块在iptables中名为state)提供的“连接追踪”功能,在不设置新的放行规则的条件下达到上述目的。
下面,我们先对state模块做简要了解。
在标准TCP/IP描述中,连接状态分为12种,而state模块的描述只有4种(当然,它们是完全不相干的两种定义方式):
- ESTABLISHED
- TCP:第一个发出的封包为服务请求封包,如果该封包能够顺利通过防火墙,那么后续的所有来往封包均为此状态
- UDP:与TCP情况类似
- ICMP:与TCP情况类似
- NEW:与协议无关,描述每一条连接中的第一个封包
- RELATED:描述被动产生的响应封包,它不属于现有任何链接;路由器在收到
traceroute发出的TTL刚好减为0的封包时,将返回一个Time to live exceeded封包,它就是RELATED状态(同样与协议无关,只要回应回来的封包是因为本机先送出一个封包导致另一连接的产生,那么这一条新连接上的所有封包都属于RELATED状态封包) - INVALID:描述不属于其他三个状态的封包
为了安全起见,我们应该将下面这条规则放在链首:
iptables -A INPUT -p all -m state --state INVALID -j DROP
现在我们来回答问题二。当PC1连接PC3时,PC3的sshd服务将PC1的IP发给DNS服务器做反向解析,然而从DNS服务器发回的返回包将遇到问题三同样的情况,所以sshd无法得到DNS响应,将不断重试,直到timeout。因此问题二与问题三的实质相同,都可以借助state模块去判别ESTABLISHED状态来解决。
开始实验:
iptables -A INPUT -m state --state ESTABLISHED -j ACCEPT
我们再次用PC3去SSH连接PC2,成功:
ssh seed@172.16.56.164 -o ConnectTimeout=5
The authenticity of host '172.16.56.164 (172.16.56.164)' can't be established.
ECDSA key fingerprint is SHA256:p1zAio6c1bI+8HDp5xa+eKRi561aFDaPE1/xq1eYzCI.
ECDSA key fingerprint is MD5:37:61:b8:e9:07:af:1c:f1:6a:49:94:ea:de:19:cf:b4.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '172.16.56.164' (ECDSA) to the list of known hosts.
seed@172.16.56.164's password:
Welcome to Ubuntu 16.04.2 LTS (GNU/Linux 4.8.0-36-generic i686)
Last login: Wed Dec 19 22:48:53 2018 from 172.16.56.1
[12/20/18]seed@VM:~$
事实上,该规则加到规则链第几行也是有讲究的。这里先加到最后就好,后面章节再详细介绍。
四、该如何管理这些规则?
我们通过命令行制定的规则在系统重启后会消失。可以借助命令来保存规则:
service iptables save
但为了后期维护方便,我们最好不要用这种方式。可以将规则写成Shell脚本,配置正确的读写执行权限,然后加入开机启动就好。下面是一个例子:
#!/bin/bash
# Set Variable
IPT=/sbin/iptables
SERVER=172.16.56.138
PARTNER=172.16.56.1
NETWORK=172.16.56.0/24
# Clear Original Rule
iptables -t filter -F
# Set INPUT Rule
$IPT -P INPUT DROP
$IPT -A INPUT -p all -m state --state INVALID -j DROP
$IPT -A INPUT -p tcp -s $NETWORK -d $SERVER --dport 25 -j ACCEPT
$IPT -A INPUT -p tcp -s $NETWORK -d $SERVER --dport 80 -j ACCEPT
$IPT -A INPUT -p tcp -s $NETWORK -d $SERVER --dport 110 -j ACCEPT
$IPT -A INPUT -p tcp -s $PARTNER -d $SERVER --dport 22 -j ACCEPT
$IPT -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
2.8 借助Filter机制构建网关式防火墙
下面分别给出网络拓扑、防火墙要求和防火墙脚本,由于尚未介绍NAT机制,我们假设内网IP为公网IP而不必做NAT转换。
网络拓扑:
NET1: 192.168.0.0/24
Router/Firewall:
eth0: 10.0.1.200
eth1: 192.168.0.1
PC1: 192.168.0.200
PC2: 192.168.0.100
PC3: 10.0.1.100
防火墙要求:
- PC1只能访问PC3的SMTP与POP3服务
- NET1网段内其他主机只能访问Internet的DNS/SMTP/POP3/HTTP/HTTPS服务
- Internet主机不得访问NET1内任何主机
防火墙脚本:
#!/bin/bash
# Set Variable
IPT=/sbin/iptables
MAIL_SRV=10.0.1.100
MAIL_PORT=25,110
INTERNET_TCP_PORT=25,110,80,443
INTERNET_UDP_PORT=53
ACC_PC=192.168.0.200
# Clear Original Rule
iptables -t filter -F
# Set Default Policy
$IPT -P INPUT DROP
$IPT -P FORWARD DROP
# Set INPUT Rule
$IPT -A INPUT -p all -m state --state INVALID -j DROP
$IPT -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
# Set Forward Rule
$IPT -A FORWARD -i eth0 -o eth1 -m state --state INVALID -j DROP
$IPT -A FORWARD -i eth0 -o eth1 -m state --state \
ESTABLISHED,RELATED -j ACCEPT
$IPT -A FORWARD -i eth1 -o eth0 -m multiport \
-p tcp -s $ACC_PC -d $MAIL_SRV --dport $MAIL_PORT -j ACCEPT
$IPT -A FORWARD -i eth1 -o eth0 -p all -s $ACC_PC -j DROP
$IPT -A FORWARD -i eth1 -o eth0 -m multiport \
-p tcp --dport $INTERNET_TCP_PORT -j ACCEPT
$IPT -A FORWARD -i eth1 -o eth0 -m multiport \
-p udp --dport $INTERNET_UDP_PORT -j ACCEPT
看一下结果:
Chain INPUT (policy DROP)
target prot opt source destination
DROP all -- anywhere anywhere state INVALID
ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
Chain FORWARD (policy DROP)
target prot opt source destination
DROP all -- anywhere anywhere state INVALID
ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
ACCEPT tcp -- 192.168.0.200 10.0.1.100 multiport dports smtp,pop3
DROP all -- 192.168.0.200 anywhere
ACCEPT tcp -- anywhere anywhere multiport dports smtp,pop3,http,https
ACCEPT udp -- anywhere anywhere multiport dports domain
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
我们在上述脚本中使用了multiport模块来指定不连续的多个端口,因为默认不使用模块的情况下我们只能以类似于25:110的形式指定从25到110的连续端口。
2.9 Netfilter的NAT机制
NAT可以应用在C端和S端,作用分别是“保护C端主机/节约公网IP”和“保护S端主机”。另外,根据拓扑结构可以将其分为四种:一对多、多对多、一对一及NAPT。本节我们对这一重要的机制进行研究学习。
由于IPv4地址资源枯竭,我们往往采用多个内网IP对应一个公网IP的网络架构。“不使用NAT、只是简单地将公网IP配置给网关路由”的方案不可行:内网发出的封包经过路由器到达公网,其src依然为私有IP;由于公网路由器通常不检查src,只检查dst,所以该封包可以抵达目的主机;但目的主机返回给私有IP的封包将被公网路由器丢弃。
广为人知的NAT解决方案是,路由器在向外转发封包时将src改为公网IP,并记录一个对应关系;在向内转发封包时将dst改为记录中的私有IP。其中,修改src的步骤称为SNAT,修改dst的步骤称为DNAT。
书上第92页关于NAT流程的讲解似乎有误,我从Netfilter官网的Linux 2.4 NAT HOWTO找了一些资料:
Source NAT is always done post-routing, just before the packet goes out onto the wire.
Destination NAT is always done before routing, when the packet first comes off the wire.
从2.2节我们知道,NAT表有4条链,事实上,IPNUT链是后来加入的,可以参考iptables: built-in INPUT chain in nat table?、What do input and output chains in NAT table do?和相关的commit。
结合以上所有信息,我尝试画出封包流经NAT机制的过程:
Packet-IN ---> PREROUTING(DNAT) ---> ROUTING-TABLE ---------------------+
| |
V |
INPUT +----> OUTPUT |
| | | |
V | V |
LOCAL-PROCESS -+ ROUTING-TABLE |
| |
V |
Packet-OUT <--- POSTROUTING(SNAT) --------------------------------------+
上图中的ROUTING-TABLE实际上是同一个。对上述流程做如下解释:
- NAT机制中的INPUT/OUTPUT链与Filter机制中的同名链没有关系
- NAT机制中的INPUT/OUTPUT链的存在是为了满足以下需求:本地进程产生的封包送离本机前,希望做一次DNAT(以前会直接进入POSTROUTING做SNAT,没有DNAT的机会);网络上发给本机进程的封包在抵达进程前,希望做一次SNAT(同样地,以前会直接进入PREROUTING做DNAT,没有SNAT的机会)。现在,我们可以把这些规则放在INPUT/OUTPUT链中
- 上述流程与封包流向无关
下面介绍本节开头提到的四种不同拓扑结构的NAT。
一对多NAT
即目前IPv4资源枯竭情况下广泛使用的局域网方案。
假设有一NAT主机,其eth0连接公网,IP为10.0.1.200,eth1连接172.16.56.0/24的内网,为了让内网机器通过NAT机制访问公网,配置方法如下:
iptables -t nat -A POSTROUTING -o eth0 -s 172.16.56.0/24 -j SNAT --to 10.0.1.200
当我们给出了一个方向(SNAT或DNAT)的规则后,Netfilter会自动判别另一个方向的响应封包。因此我们只需要给出上述一条命令即可。
如果公网IP是通过DHCP等方式动态分配的,需要将上述命令稍作修改:
iptables -t nat -A POSTROUTING -o eth0 -s 172.16.56.0/24 -j MASQUERADE
MASQUERADE意为使用外出网卡上的IP来作为源IP。
多对多NAT
与一对多NAT类似,但要求NAT主机的对外网卡具有多个连续公网IP:
iptables -t nat -A POSTROUTING -o eth0 -s 172.16.56.0/24 -j SNAT --to 10.0.1.200-10.0.1.205
一对一NAT
在第一章对防火墙类型的介绍中我们提到,将服务器放在内网中能够提高安全性。在下图所示的拓扑结构中,我们希望192.168.0.1/192.168.0.2能够分别与10.0.1.201/10.0.1.202进行一对一NAT转换:
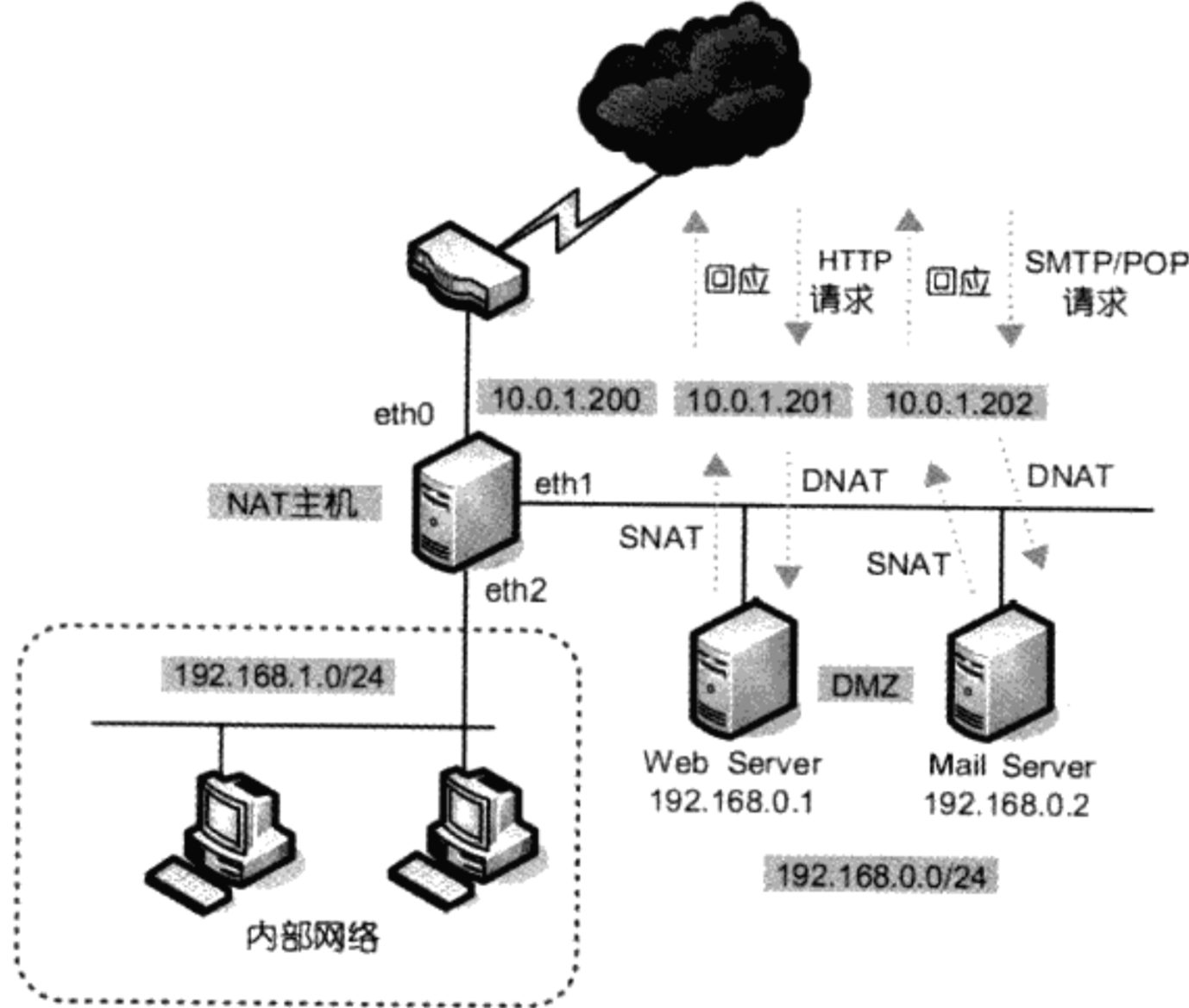
以Web Server为例,为了让外网客户能够访问到Web服务,我们添加如下规则:
iptables -t nat -A PREROUTING -i eth0 -d 10.0.1.201 -j DNAT --to 192.168.0.1
当然,如果我们希望Web服务器能够去访问外网的其他服务,那么还需要添加以下规则:
iptables -t nat -A POSTROUTING -o eth0 -s 192.168.0.1 -j SNAT --to 10.0.1.201
NAPT
NAPT即Network Address Port Translation,使用场景与上面介绍的一对一NAT类似,区别是我们只拥有一个公网IP:
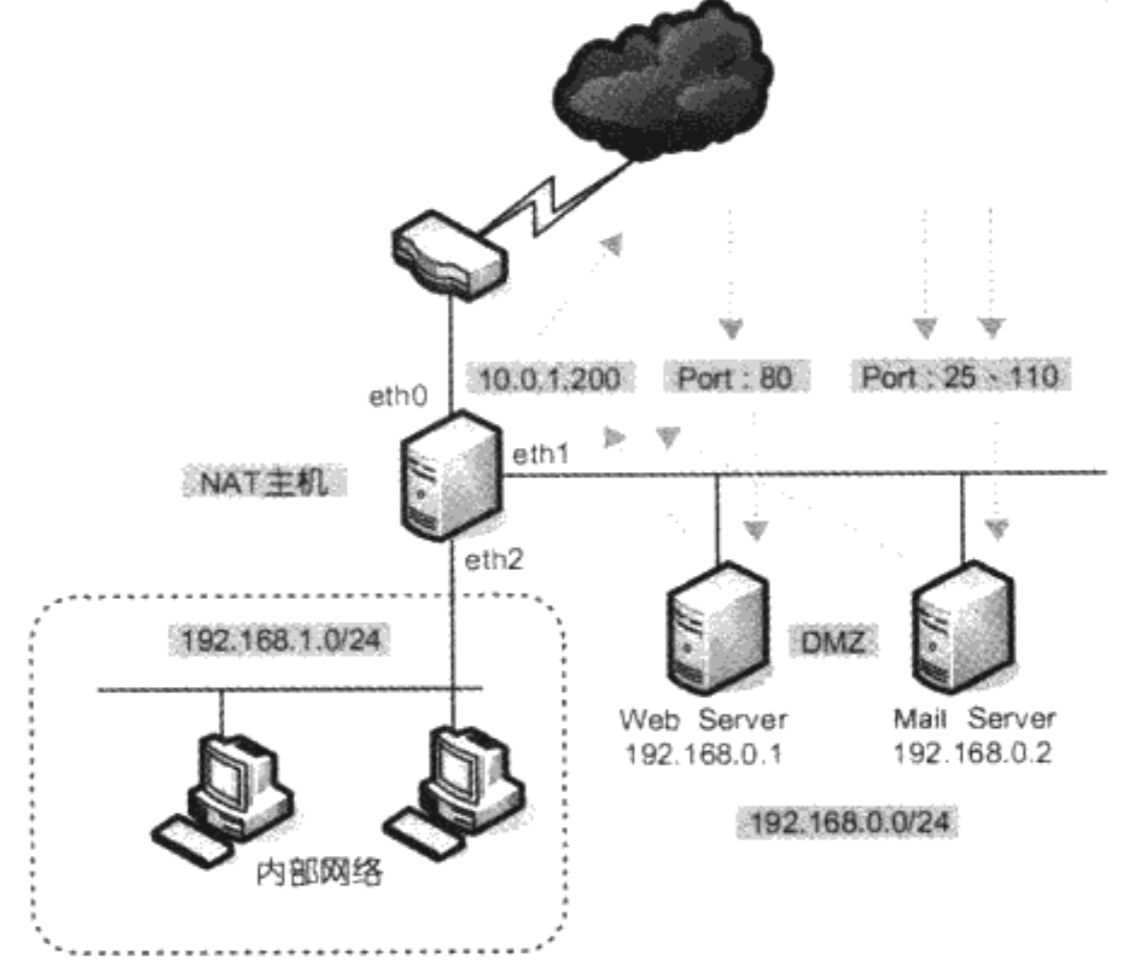
所以,我们变通一下,将一对一IP映射的需求降为一对一端口映射。具体如下:
iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 80 -j DNAT --to 192.168.0.1:80
iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 443 -j DNAT --to 192.168.0.1:443
iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 25 -j DNAT --to 192.168.0.2:25
iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 110 -j DNAT --to 192.168.0.2:110
2.10 Netfilter的Mangle机制
Mangle机制可以修改封包内容。例如,修改IP包头的TTL值,从而欺骗依据ping来判断目标操作系统类型的扫描器。它的结构与NAT类似:
Packet-IN ---> PREROUTING ---> ROUTING-TABLE ---> FORWARD ---------+
| |
V |
INPUT +----> OUTPUT |
| | | |
V | V |
LOCAL-PROCESS -+ ROUTING-TABLE |
| |
V |
Packet-OUT <--- POSTROUTING ---------------------------------------+
2.11 Netfilter的完整结构
从网上找到一张对封包流经Netfilter过程介绍较为完整的图片:
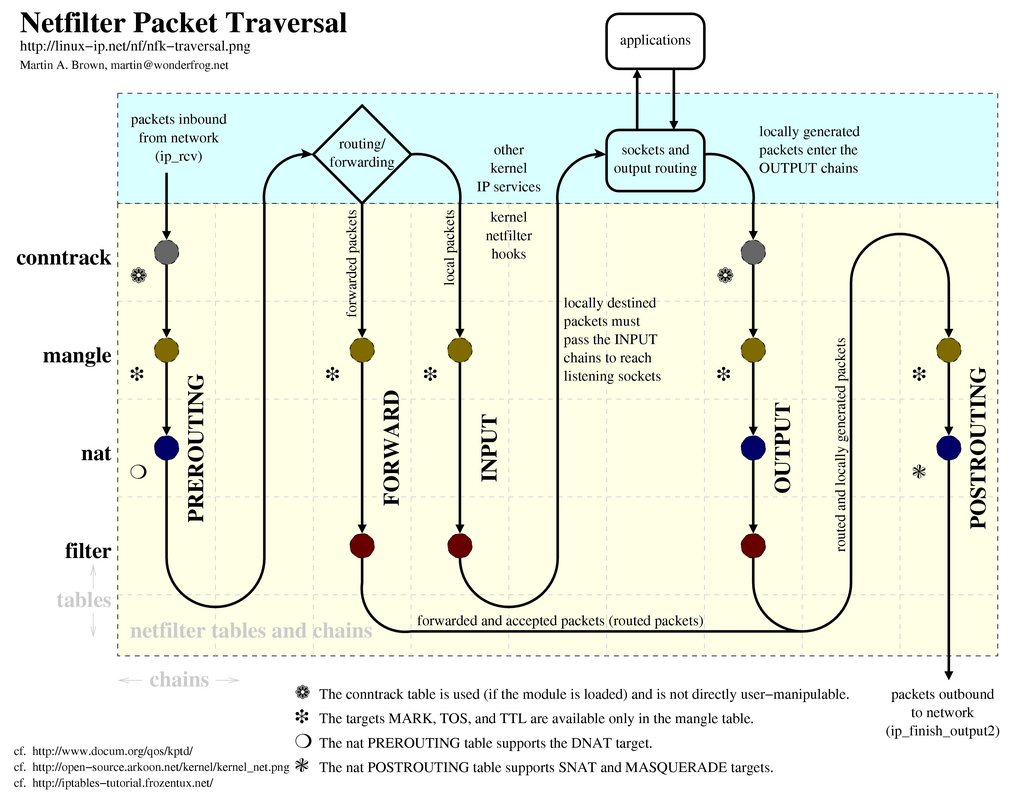
上图中不同颜色的圆点代表不同的规则表。
事实上,将NAT机制与Filter机制结合使用才能使服务器得到更高安全性(在实际应用时一定要注意上图中不同机制不同环节的先后顺序对src/dst等的影响)。
总结
到目前为止,我们已经学习了除RAW外的所有机制。RAW与“连接追踪”机制有关,因此,在后面学习过该机制后,我们再来学习RAW。
这本书让我想起了王爽老师的《汇编语言》,这样的书籍能够让你在阅读中从点到面,逐步形成一个知识体系,而不是像一般的手册那样,让你觉得所有知识散落在那里,一团乱麻。