夜阑风静縠纹平。小舟从此逝,江海寄余生。
实验说明
Rootkit的一种经典形式是通过Hook系统调用实现。在本次实验中,我们将实现简单的系统调用挂钩方案,并且基于这个方案实现最基本的文件监视工具,同时加深对LKM的理解。
实验环境
uname -a:
Linux kali 4.6.0-kali1-amd64 #1 SMP Debian 4.6.4-1kali1 (2016-07-21) x86_64 GNU/Linux
GCC version:6.1.1
上述环境搭建于虚拟机,另外在没有特殊说明的情况下,均以root权限执行。
注:后面实验参考的是4.11的源码,可以在线阅览。
实验过程
一 基于修改sys_call_table的系统调用挂钩
Linux内核在内存中维护了一份系统调用向量表,它是一个元素为函数指针的一维数组,定义见arch/x86/entry/syscall_64.c:
asmlinkage const sys_call_ptr_t sys_call_table[__NR_syscall_max+1] = {
/*
* Smells like a compiler bug -- it doesn't work
* when the & below is removed.
*/
[0 ... __NR_syscall_max] = &sys_ni_syscall,
#include <asm/syscalls_64.h>
};
所以最直接的思路就是修改这张表,把对应的系统调用地址更换为我们的函数地址。问题转化为三个子问题:
- 找到这张表在内存中的地址
- 这张表所在内存有写保护,我们要关掉写保护
- 修改这张表(之后要开启写保护)
接下来按这个步骤进行实验。
1 寻找sys_call_table内存地址
寻找系统调用表的地址的方法不止一种。这里先介绍一种,并为其他方法留坑。
要注意的一点是,只有内核中导出的函数和变量符号才能被我们直接引用,没有导出的那些对我们是透明的。参考网友的评论可知,在2.6内核后sys_call_table是不可见的。
① 暴力搜索
原理:内核内存空间的起始地址PAGE_OFFSET变量和sys_close系统调用对我们是可见的(sys_open/sys_read等并未导出);系统调用号(即sys_call_table中的元素下标)在同一ABI(x86与x64属于不同ABI)中是高度后向兼容的;这个系统调用号我们也是可以直接引用的(如__NR_close)。所以我们可以从内核空间起始地址开始,把每一个指针大小的内存假设成sys_call_table的地址,并用__NR_close索引去访问它的成员,如果这个值与sys_close的地址相同的话,就可以认为找到了sys_call_table的地址(但是师傅说这种方法可能被欺骗)。
我们先简单看一下PAGE_OFFSET的定义(x64):
#define PAGE_OFFSET ((unsigned long)__PAGE_OFFSET)
#define __PAGE_OFFSET page_offset_base
unsigned long page_offset_base = __PAGE_OFFSET_BASE;
EXPORT_SYMBOL(page_offset_base);
#define __PAGE_OFFSET_BASE _AC(0xffff880000000000, UL)
接下来看我们的搜索函数:
unsigned long **get_sys_call_table(void)
{
unsigned long **entry = (unsigned long **)PAGE_OFFSET;
for(; (unsigned long)entry < ULONG_MAX; entry += 1){
if(entry[__NR_close] == (unsigned long *)sys_close)
return entry;
}
return NULL;
}
测试用LKM模块代码如下(后面将在此模块上添加代码):
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/syscalls.h>
unsigned long **real_sys_call_table;
int init_module(void)
{
printk("%s\n", "Greetings the world!\n");
real_sys_call_table = get_sys_call_table();
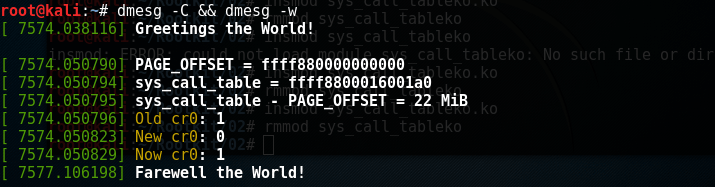
printk("PAGE_OFFSET = %lx\n", PAGE_OFFSET);
printk("sys_call_table = %p\n", real_sys_call_table);
printk("sys_call_table - PAGE_OFFSET = %lu MiB\n",\
((unsigned long)real_sys_call_table - \
(unsigned long)PAGE_OFFSET) / 1024 / 1024);
return 0;
}
void cleanup_module(void)
{
printk("%s\n", "Farewell the World!");
return;
}
Makefile:
TARGET = sys_call_table
obj-m := ${TARGET}ko.o
${TARGET}ko-objs := ${TARGET}.o
default:
${MAKE} modules \
--directory "/lib/modules/$(shell uname --release)/build" \
M="$(shell pwd)"
clean:
${MAKE} clean \
--directory "/lib/modules/$(shell uname --release)/build" \
M="$(shell pwd)"
我们没有使用第一次实验中的module_init和module_exit两个宏去指定入口函数和出口函数,那样也是可以的,这里只是使用了默认的入口函数名和出口函数名。
测验结果如下:

② 从/boot/System.map提取
暂略,见【拓展阅读】3。
③ 使用未导出函数机器码搜索
暂略,见【拓展阅读】4。
2 关掉写保护
找到地方了,下面要关闭写保护。CR0寄存器从0数的第16比特控制了对只读内存的写保护是否开启,详见【已参考】3。巧的是,我们可以用内核自己的read_cr0/write_cr0去读写CR0,并用它提供的clear_bit/set_bit接口去做位运算。我们把它们封装一下:
void disable_write_protection(void)
{
unsigned long cr0 = read_cr0();
clear_bit(16, &cr0);
write_cr0(cr0);
}
void enable_write_protection(void)
{
unsigned long cr0 = read_cr0();
set_bit(16, &cr0);
write_cr0(cr0);
}
接着在入口函数中添加一些测试代码:
unsigned long cr0;
cr0 = read_cr0();
printk("Old: %d\n", test_bit(X86_CR0_WP_BIT, &cr0));
disable_write_protection();
cr0 = read_cr0();
printk("New: %d\n", test_bit(X86_CR0_WP_BIT, &cr0));
enable_write_protection();
cr0 = read_cr0();
printk("Now: %d\n", test_bit(X86_CR0_WP_BIT, &cr0));
测试结果如下:
3 修改sys_call_table
至此,修改就很简单了。配合后面第二部分文件监视,我们将修改三个系统调用:sys_open/sys_unlink/sys_unlinkat。我们的思路是,在入口函数中先备份原始的系统调用,然后修改成我们自己的。在出口函数中恢复原始的系统调用。
修改
disable_write_protection();
real_open = (void *)real_sys_call_table[__NR_open];
real_sys_call_table[__NR_open] = (unsigned long*)fake_open;
real_unlink = (void *)real_sys_call_table[__NR_unlink];
real_sys_call_table[__NR_unlink] = (unsigned long*)fake_unlink;
real_unlinkat = (void *)real_sys_call_table[__NR_unlinkat];
real_sys_call_table[__NR_unlinkat] = (unsigned long*)fake_unlinkat;
enable_write_protection();
恢复
disable_write_protection();
real_sys_call_table[__NR_open] = (unsigned long*)real_open;
real_sys_call_table[__NR_unlink] = (unsigned long*)real_unlink;
real_sys_call_table[__NR_unlinkat] = (unsigned long*)real_unlinkat;
enable_write_protection();
至此,系统调用挂钩就完成了。缺少的函数定义和声明在下一部分加上,同时在下一部分一并演示。
二 基于系统调用挂钩的初级文件监视
这里补上缺少的函数定义:
asmlinkage long (*real_open)(const char __user *, int, umode_t);
asmlinkage long fake_open(const char __user *filename, int flags, umode_t mode)
{
if((flags & O_CREAT) && strcmp(filename, "/dev/null") != 0){
printk(KERN_ALERT "open: %s\n", filename);
}
return real_open(filename, flags, mode);
}
asmlinkage long (*real_unlink)(const char __user *);
asmlinkage long *fake_unlink(const char __user *pathname)
{
printk(KERN_ALERT "unlink: %s\n", pathname);
return real_unlink(pathname);
}
asmlinkage long (*real_unlinkat)(int, const char __user *, int);
asmlinkage long *fake_unlinkat(int dfd, const char __user *pathname, int flag){
printk(KERN_ALERT "unlinkat: %s\n", pathname);
return real_unlinkat(dfd, pathname, flag);
}
编译加载模块,测试结果如下:

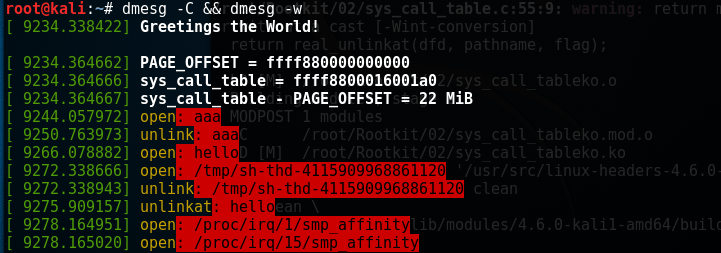
中间多出来的/tmp/sh-thd-那两行是我在rm hello时按了tab进行文件名补全才出现的,应该是补全功能产生的临时文件。
unlink和unlinkat几乎相同,关于差异可man unlinkat。
注意在测试结束后卸载模块,恢复默认系统调用。
实验问题
【问题一】
KERN_ALERT是干嘛的?
【问题二】
前面说暴力搜索系统调用表的方法可能被欺骗,具体是怎样的欺骗方法?
实验总结与思考
配合着源码在线阅览,边做边能查到内核代码的感觉非常棒。
本次实验中的dmesg -C && dmesg -w比第一次实验中的grep要方便许多。
实验过程中深感自己学识浅薄,静水流深呐。一个朋友在FreeBuf文章下评论说:“写得不错。但获取sys_call_table的地址对hook这一大目标并没有起到多大作用,甚至是多余的。”后来他又说:“回复有所歧义,说不需要知道sys_call_table的地址是针对2.6以前的内核版本,之前的版本可以直接引用sys_call_table变量,多谢提醒!另外除了利用system.map获取table的地址外,可以读取IDT的值,之后找到int $0×80的入口点,后三个字节的值就是table的地址,还没验证。”另一个朋友会说:“这就是Windows的SSDT HOOK在Linux核上的翻版啊。”作者回复说:“是的,眼力不错。都是基于修改系统调用表的系统调用挂钩。Linux的系统调用表叫sys_call_table / ia32_sys_call_table,Windows的系统调用表大家通常叫SSDT。显然,从学习、实践与理解的角度看,Linux更适合用来起步。”
他们的讨论让我学到了知识。社区需要的正是这种讨论,正是这种学习的氛围。谢谢各位师傅的分享。