Introduction
This post is a brief note for the chapter 1 in the book Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 3rd Edition by Aurélien Géron. The code examples in this book can be found on GitHub.
Three production-ready Python frameworks, scikit-learn, TensorFlow, and Keras, are used in this book to build machine learning systems. Jupyter notebooks are widely used for interactive programming and debugging. Google Colab provides an online environment to run your notebooks easily. In addition, three popular scientific libraries in Python, NumPy, Pandas, and Matplotlib, are used to manipulate and illustrate the data.
BTW, The deep learning technique is proposed in a paper published in 2006 by Geoffrey Hinton et al.
What Is Machine Learning?
The general definition by Arthur Samuel in 1959:
[Machine learning is the] field of study that gives computers the ability to learn without being explicitly programmed.
The engineering-oriented definition by Tom Mitchell in 1997:
A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
Let’s take the spam filter program (based on machine learning) for example to explain some terms in this field:
- Training set: the spam examples that the program uses to learn.
- Training instance: each training example in the training set.
- Model: the part of a machine learning system that learns and makes predictions, e.g., neural networks and random forests.
- Accuracy: the performance measure which is often used in classification tasks.
For the spam filter case, the task T is to flag spam for new emails, the experience E is the training data (training set), and the performance measure P could be the ratio of correctly classified emails (accuracy).
Why Use Machine Learning?
The traditional approach for spam filter is to maintain a long list of complex rules, which is hard and prone to errors. In contrast, a spam filter based on machine learning can automatically learn the patterns, which is easier to maintain and more accurate.
Another area where machine learning shines is for problems that either are too complex for traditional approaches or have no known algorithm, e.g., speech recognition. Additionally, machine learning can help humans learn.
To summarize, machine learning is great for four typical scenarios:
- Problems for which existing solutions require a lot of fine-tuning or long lists of rules.
- Complex problems for which no good solution exists yet.
- The problem environment fluctuates.
- To get insights about complex problems and big data.
Types of Machine Learning Systems
Generally speaking, the machine learning systems can be classified based on how they are supervised during training, whether they can learn incrementally on the fly, and whether they work by comparing new data to known data or by building a predictive model.
These criteria are not exclusive and you can combine them in any way. Here is an overview for your convenience:

Note that this diagram is just for demonstration, which means that the relationships among different types (especially in the same criteria) may not be precise. For example, the logistic regression is commonly used for classification.
Some tips for machine learning systems:
- The words target and label are generally treated as synonyms in supervised learning, but target is more common in regression tasks and label is more common in classification tasks.
- Features are sometimes called predictors or attributes.
- The goal of dimensionality reduction is to simplify the data without losing too much information. One way to do this is to merge several correlated features into one, which is called feature extraction as well.
- Most semi-supervised learning algorithms are combinations of unsupervised and supervised algorithms.
- A model’s performance tends to decay slowly over time, which is often called model rot or data drift.
- Reinforcement learning is a process where a system, known as an agent, learns to choose the best actions, guided by a strategy called a policy, to earn maximum rewards over time by interacting with its environment and receiving feedback in the form of rewards or penalties.
- Online learning algorithms can be used to train models on huge datasets that cannot fit in one machine’s main memory, which is called out-of-core learning. Learning rate is used to describe how fast the online learning systems adapt to changing data.
- Out-of-core learning is usually done offline, so online learning can be a confusing name. Think of it as incremental learning.
- Instance-based learning systems learn the examples by heart, then generalize to new cases by using a similarity measure to compare them to the learned examples.
- Model-based learning is to build a model of examples and then use that model to make predictions.
- To find out what makes your model work best, you need a way to measure its performance. This can be done by using a utility function (or fitness function) to see how good it is, or a cost function to see how bad it is. For example, in linear regression, a common cost function measures how far off the model’s predictions are from the actual data, and the goal is to make this distance as small as possible.
- Training a model is the process of using an algorithm to find the best settings that make the model match the training data well and ideally predict new data accurately.
Main Challenges of Machine Learning
Two challenges in machine learning are bad model and bad data.
Usually, there are four cases of bad data:
- Insufficient quantity of training data.
- Nonrepresentative training data.
- If the sample is too small, you will have sampling noise.
- But even large samples can be nonrepresentative if the sampling method is flawed (sampling bias).
- Poor-quality data. You can clean up the training data in some ways:
- Discard or fix outliers.
- If some data points are missing certain features, you need to choose if you want to disregard these features entirely, skip these data points, fill in the gaps, or make two models - one with the feature and one without it.
- Irrelevant features. You can conduct feature engineering to get a good set of features:
- Feature extraction: combine existing features to produce a more useful one.
- Feature selection: select the most useful features to train on among existing features.
- Creating new features by gathering new data.
And two cases of bad model:
- Overfitting the training data. And here are some possible solutions:
- Simplify the model by selecting one with fewer parameters, by reducing the number of attributes in the training data, or by constraining the model (regularization).
- Gather more training data.
- Reduce the noise in the training data.
- Underfitting the training data. Some possible solutions are:
- Select a more powerful model, with more parameters.
- Feed better features to the learning algorithm (feature engineering).
- Reduce the constraints on the model (e.g., by reducing the regularization hyperparameter).
Testing and Validating
It is useful to split the data into two sets: training set and test set. We can train the model on the training set and test it against the test set. The error rate on new cases is called the generalization error, or out-of-sample error. Usually, it is proper to keep 80% of the data as training set and the rest 20% for testing.
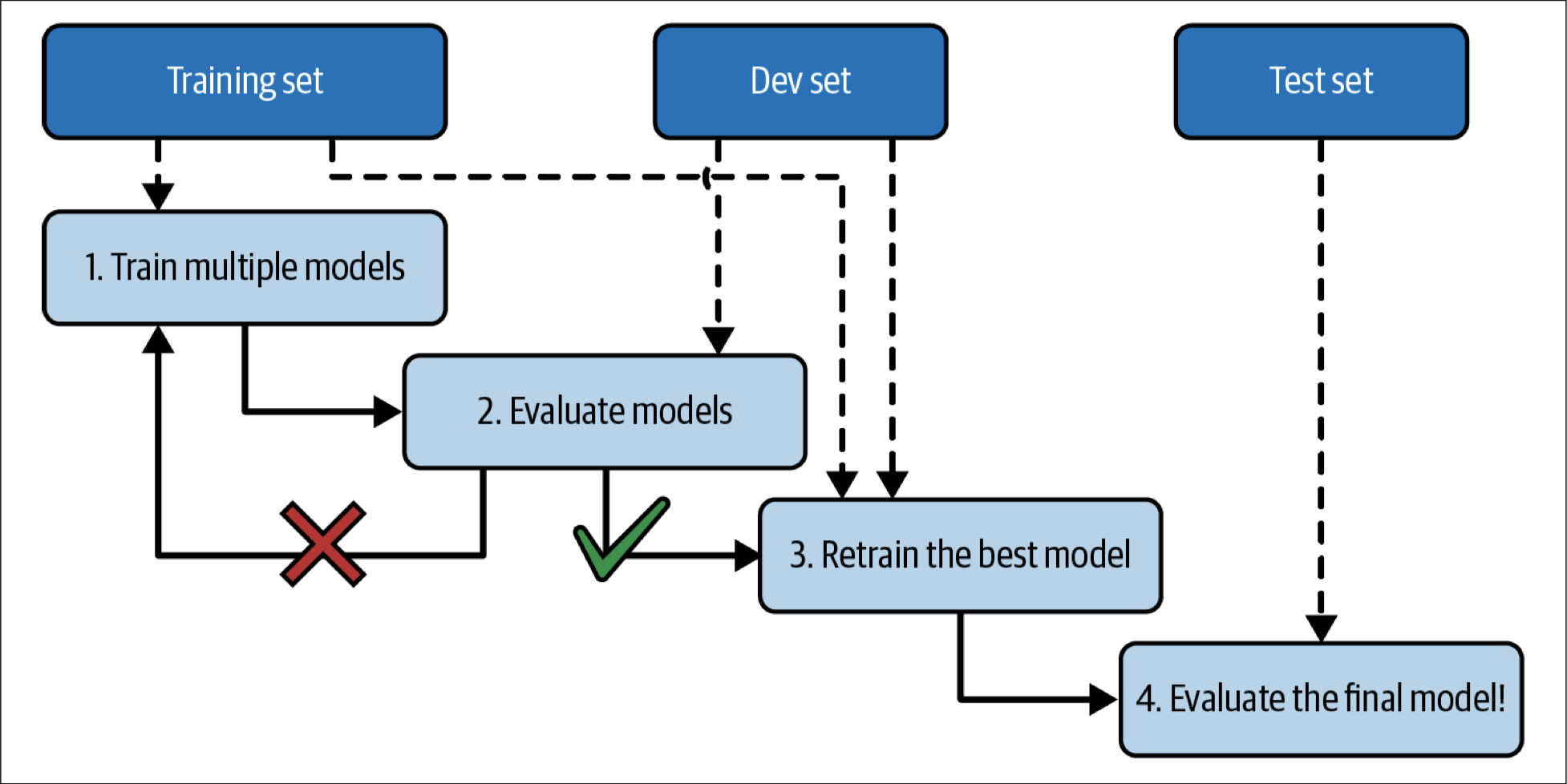
There is always a problem in machine learning that you measured the generalization error multiple times on the test set, and you adapted the model and hyperparameters to produce the best model for that particular set. Holdout validation and cross-validation are two popular solutions. The figure below clearly illustrates the holdout validation progress:
Summary
This blog post serves as a concise summary of chapter 1 from Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 3rd Edition by Aurélien Géron.
The author discusses machine learning’s definition, its advantages, the types of machine learning systems, their challenges, and the importance of testing and validating. The author references Python frameworks like scikit-learn, TensorFlow, and Keras and also uses Jupyter notebooks and Google Colab for interactive programming and debugging.
Machine learning’s potential to simplify complex problems and adapt to fluctuating environments is highlighted. It excels in situations where traditional solutions require extensive fine-tuning or where no known algorithm exists.
Note that a model is a simplified representation of the data. There is a No Free Lunch (NFL) theorem in machine learning, that if you make absolutely no assumption about the data, then there is no reason to prefer one model over any other.