1. 前言
本文是《Python深度学习(第2版)》一书第三、四章的学习笔记。
2. Keras和TensorFlow入门
TensorFlow是基于Python的开源机器学习框架,目前的最新稳定版本是v2.12.0。注意,TensorFlow v2.x版本的API与v1.x版本的有很多不同之处。Keras则是构建于TensorFlow上的开源机器学习API库。
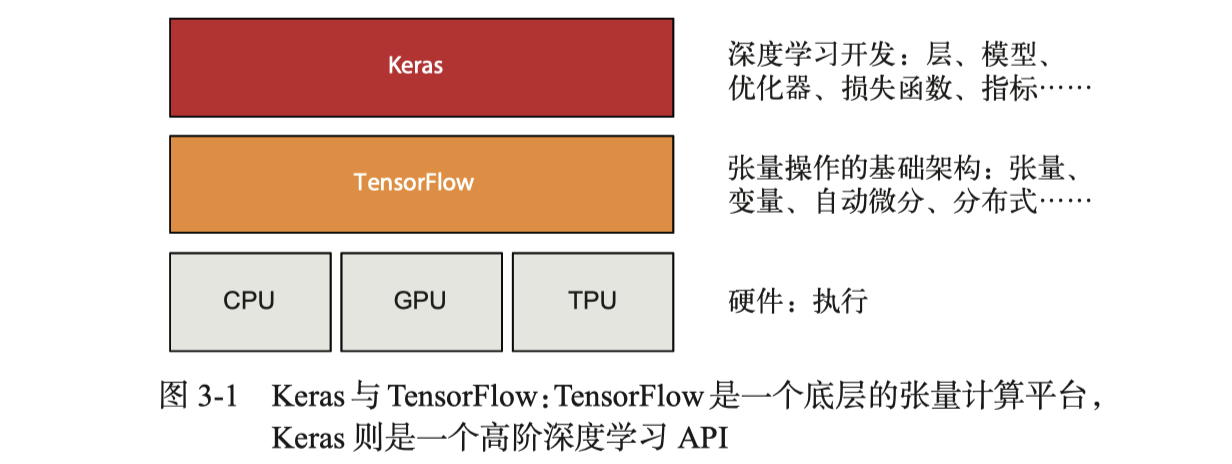
张量操作通常对应着TensorFlow API,如张量运算、反向传播等;深度学习概念则通常对应着Keras API,如层、损失函数、优化器、指标、训练循环等。
下面是TensorFlow中全1张量、全0张量和随机张量地创建方法:
>>> tf.ones(shape=(2, 1))
<tf.Tensor: shape=(2, 1), dtype=float32, numpy=
array([[1.],
[1.]], dtype=float32)>
>>> tf.zeros(shape=(2, 1))
<tf.Tensor: shape=(2, 1), dtype=float32, numpy=
array([[0.],
[0.]], dtype=float32)>
>>> tf.random.normal(shape=(3, 1), mean=0., stddev=1.)
<tf.Tensor: shape=(3, 1), dtype=float32, numpy=
array([[1.2883002],
[1.359465 ],
[1.1576971]], dtype=float32)>
注意,TensorFlow张量是不可赋值的常量,与NumPy数组不同。如果想要修改张量的值,我们可以创建变量:
>>> x = np.ones(shape=(2, 2))
>>> x[0, 0] = 0.
>>> y = tf.ones(shape=(2, 2))
>>> y[0, 0] = 0.
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tensorflow.python.framework.ops.EagerTensor' object does not support item assignment
>>> v = tf.Variable(initial_value=tf.random.normal(shape=(3, 1)))
>>> v[0, 0].assign(3.)
<tf.Variable 'UnreadVariable' shape=(3, 1) dtype=float32, numpy=
array([[ 3. ],
[-0.6722511 ],
[-0.09299621]], dtype=float32)>
tf.square用于求平方,tf.sqrt用于求平方根,星号用于两个张量逐元素的积运算,tf.matmul则是点积运算。这些简单运算都是急切执行(eager execution)的运算。从TensorFlow 2.0起,急切执行默认开启。
2.1 用TensorFlow编写线性分类器
接下来是一个简单的实践——用Tensorflow写一个线性分类器。首先我们生成一些线性可分的数据及它们对应的标签:
# generate data
num_samples_per_class = 1000
negative_samples = np.random.multivariate_normal(mean=[0, 3], cov=[[1, 0.5], [0.5, 1]], size=num_samples_per_class)
positive_samples = np.random.multivariate_normal(mean=[3, 0], cov=[[1, 0.5], [0.5, 1]], size=num_samples_per_class)
# generate input data
inputs = np.vstack((negative_samples, positive_samples)).astype(np.float32)
# generate labels
targets = np.vstack((np.zeros((num_samples_per_class, 1), dtype="float32"), np.ones((num_samples_per_class, 1), dtype="float32")))
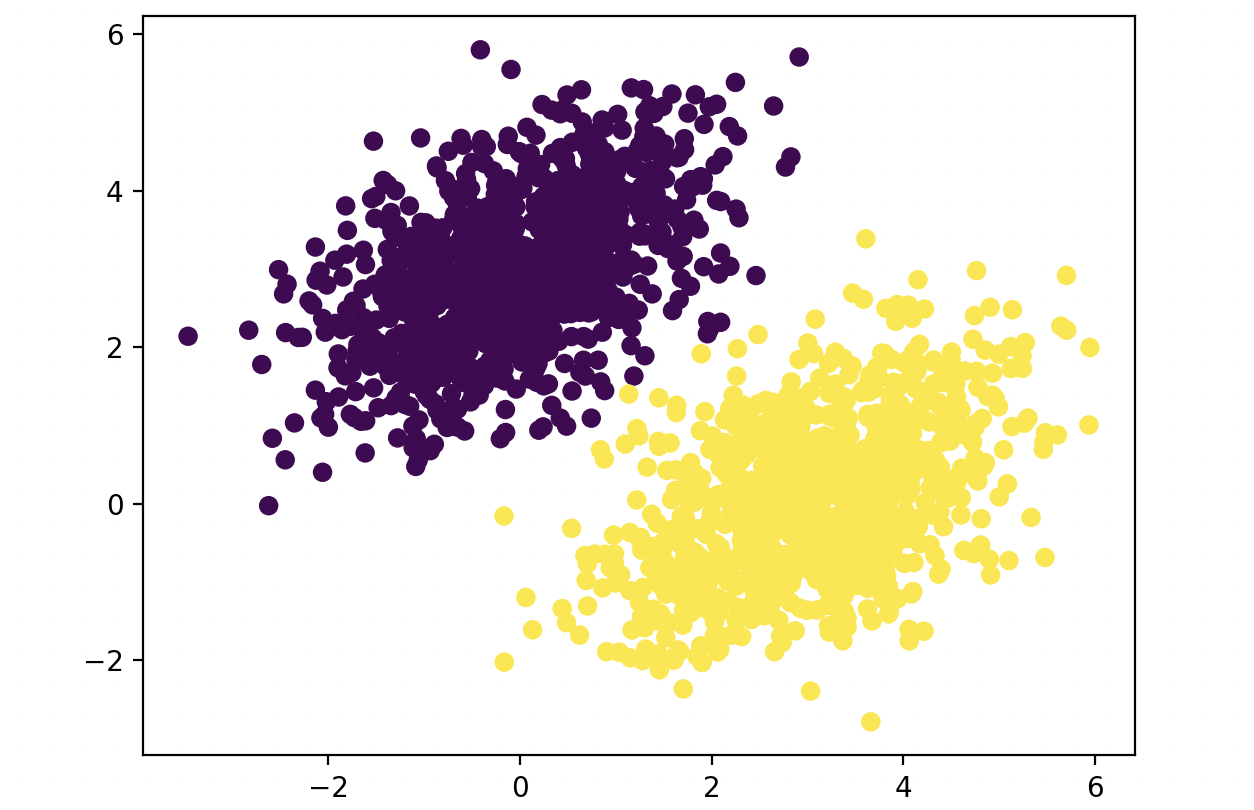
在坐标系中观察一下这些数据是否满足要求:
plt.scatter(inputs[:, 0], inputs[:, 1], c=targets[:, 0])
plt.show()
生成的数据来自特定协方差矩阵和特定均值的随机分布,两类数据(点云)的协方差矩阵相同,均值不同,非常直观:
接下来创建一个基于仿射变换的线性分类器,并定义前向传播函数和均方误差损失函数:
input_dim = 2
output_dim = 1
W = tf.Variable(initial_value=tf.random.uniform(shape=(input_dim, output_dim)))
b = tf.Variable(initial_value=tf.zeros(shape=(output_dim,)))
def model(inputs): # forward propagation
return tf.matmul(inputs, W) + b
def square_loss(targets, predictions): # loss function
per_sample_losses = tf.square(targets - predictions)
return tf.reduce_mean(per_sample_losses)
然后编写训练步骤函数,并进行批量训练:
# training step
learning_rate = 0.1
def training_step(inputs, targets):
with tf.GradientTape() as tape:
predictions = model(inputs)
loss = square_loss(targets, predictions)
grad_loss_wrt_W, grad_loss_wrt_b = tape.gradient(loss, [W, b])
W.assign_sub(grad_loss_wrt_W * learning_rate)
b.assign_sub(grad_loss_wrt_b * learning_rate)
return loss
for step in range(40): # training
loss = training_step(inputs, targets)
print(f"Loss at step {step}: {loss:.4f}")
注意,这里不是“小批量训练”,因为每次训练都使用了所有的训练数据,每次梯度更新都包含所有训练样本的信息。相对来说,批量训练需要的迭代次数更少。
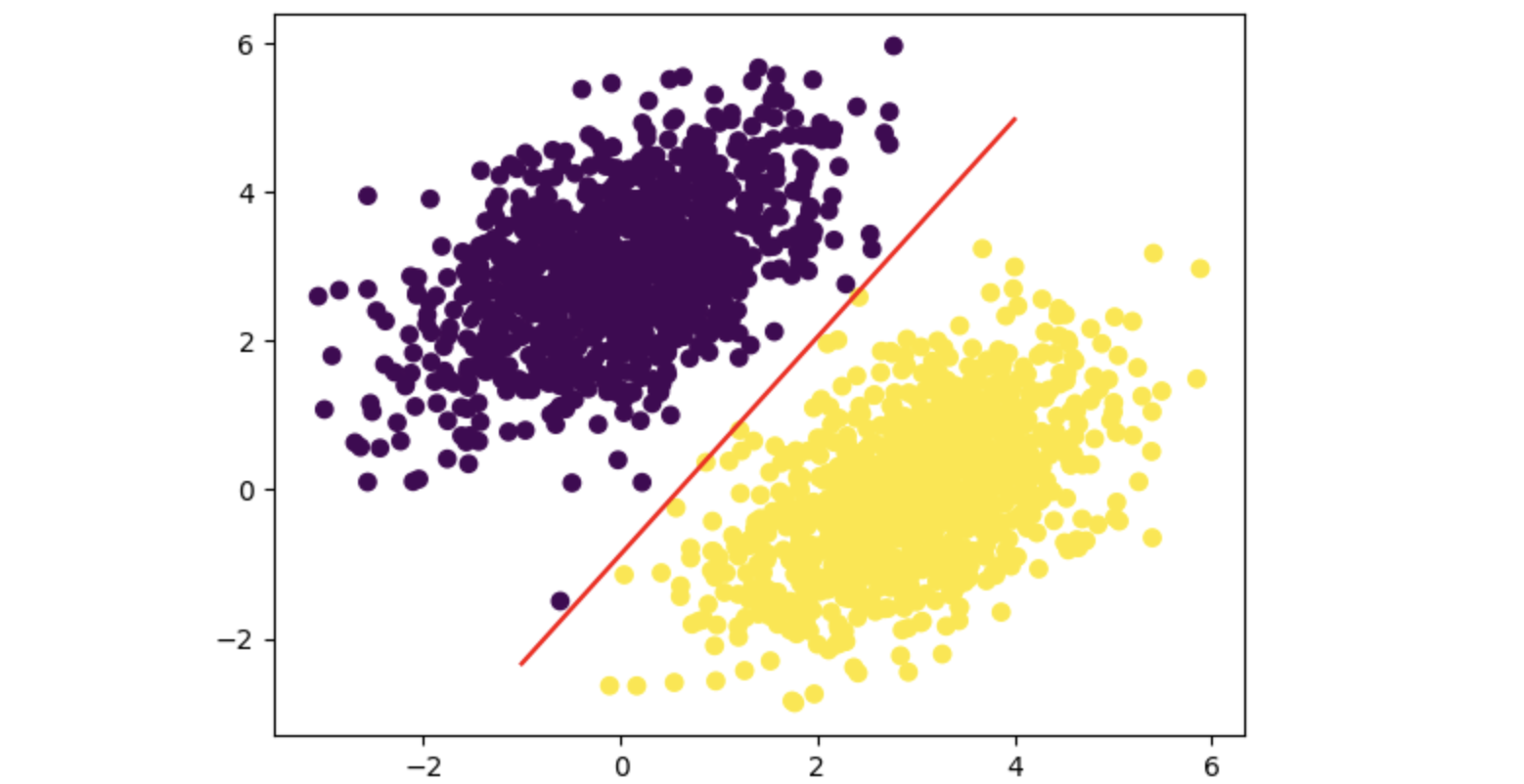
40轮迭代结束后,我们看一下模型的分类能力如何:
# visualization
predictions = model(inputs)
x = np.linspace(-1, 4, 100)
y = - W[0] / W[1] * x + (0.5 - b) / W[1]
plt.plot(x, y, "-r")
plt.scatter(inputs[:, 0], inputs[:, 1], c=predictions[:, 0] > 0.5)
plt.show()
结果显示,我们的模型(图中的红线)能够较好地将两个点云分开:
2.2 了解核心Keras API
前面我们用TensorFlow实现了一个简单的模型。接下来,我们深入了解一下Keras API。
2.2.1 层:深度学习的基础模块
神经网络的核心组件是“层”,它是一个数据处理模块,接收张量作为输入,并输出张量。层可以是无状态的,但大多数层是有状态的,即包含权重。Keras将层具像化,包括全连接层(Dense)、卷积层(Conv2D)等。
Keras的核心概念是Layer类,它是封装了状态(权重,在build()方法中定义或在构造函数中创建)和计算(一次前向传播,在call()方法中定义)的对象。Keras中的其他东西要么是Layer,要么与Layer密切交互。我们可以基于它设计自己的层。下面是一个全连接层的实现:
class SimpleDense(keras.layers.Layer):
def __init__(self, units, activation=None):
super().__init__()
self.units = units
self.activation = activation
def build(self, input_shape):
input_dim = input_shape[-1]
self.W = self.add_weight(shape=(input_dim, self.units),
initializer="random_normal")
self.b = self.add_weight(shape=(self.units,),
initializer="zeros")
def call(self, inputs):
y = tf.matmul(inputs, self.W) + self.b
if self.activation is not None:
y = self.activation(y)
return y
接着就可以实例化这个类,并调用它:
my_dense = SimpleDense(units=32, activation=tf.nn.relu)
input_tensor = tf.ones(shape=(2, 784))
output_tensor = my_dense(input_tensor)
在堆叠层时,Keras能够自动推断形状并调用build()方法动态构建层,我们无需为模型中添加的每一层都指定输入输出的形状,例如:
from tensorflow.keras import models
model = keras.Sequential([
SimpleDense(32, activation="relu"),
SimpleDense(64, activation="relu"),
SimpleDense(32, activation="relu"),
SimpleDense(10, activation="softmax")
])
第一次调用层时,Layer类的__call__()方法会自动调用我们定义的方法,相关代码大致如下:
def __call__(self, inputs):
if not self.built:
self.build(inputs.shape)
self.built = True
return self.call(inputs)
2.2.2 从层到模型
深度学习模型是由层构成的图,在Keras中是Model类。我们前面见过的Sequential模型只是层的简单堆叠,其他常见的网络拓扑包括双分支网络、多头网络、残差链接等。
在Keras中构建模型通常有两种方法:直接作为Model类的子类和使用函数式API。
模型的拓扑结构定义了一个假设空间。要从数据中学习,我们必须对数据进行假设,这些假设定义了可学习的内容。假设空间的结构(模型结构)非常重要,它编码了你对问题所做的假设,也就是先验知识。例如,如果你使用一个没有激活函数的Dense层作为模型去解决一个二分类问题,那么你假设了这两个类别是线性可分的。选择正确的网络架构是一个艺术。
2.2.3 编译步骤:配置学习过程
确定模型架构后,我们还需要确定模型的损失函数(目标函数)、优化器和指标。上一篇文章已经介绍过这些概念,不再赘述。Keras中我们使用模型的compile()方法来指定这些参数,例如:
model = keras.Sequential([
layers.Dense(512, activation="relu"),
layers.Dense(10, activation="softmax")
])
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
上面的例子里,我们使用字符串来指定参数,实际上这是一种访问Python对象的快捷方式。我们也可以正式指定参数,如
optimizer=keras.optimizers.RMSprop(learning_rate=1e-4)
2.2.4 选择损失函数
损失函数的选择有一些简单的指导原则:对于二分类问题,可使用二元交叉熵损失函数;对于多分类问题,可以使用分类交叉熵损失函数。
2.2.5 理解fit()方法
fit()方法将开始执行训练循环,接收的参数有:训练数据(输入和目标)、训练轮数、批量大小等:
history = model.fit(inputs, targets, epochs=5, batch_size=128)
返回的History对象的history字段是一个字典,包含指标在每轮训练中的变化情况。我们通常可以基于此绘图来观察训练过程。
2.2.6 监控验证数据上的损失和指标
机器学习的目标是得到总体上表现良好的模型,尤其是在模型未见过的数据上,而不是仅仅在训练集上。
一般来说,我们最好保留训练数据的一个子集作为验证数据(validation data),我们用这部分数据来计算损失值和指标值。我们可以在fit()方法中传入验证数据:
indices_permutation = np.random.permutation(len(inputs))
shuffled_inputs = inputs[indices_permutation]
shuffled_targets = targets[indices_permutation]
num_validation_samples = int(0.3 * len(inputs))
val_inputs = shuffled_inputs[:num_validation_samples]
val_targets = shuffled_targets[:num_validation_samples]
training_inputs = shuffled_inputs[num_validation_samples:]
training_targets = shuffled_targets[num_validation_samples:]
model.fit(
training_inputs,
training_targets,
epochs=5,
batch_size=16,
validation_data=(val_inputs, val_targets)
)
注意区别“训练损失”和“验证损失”。前者是训练过程中的,后者是验证过程的。必须将训练数据和验证数据严格区分开,否则验证损失就会不准确。
我们也可以在训练完成后再计算验证损失和指标:
loss_and_metrics = model.evaluate(val_inputs, val_targets, batch_size=128)
2.2.7 推断:在训练后使用模型
最后,我们可以使用训练好的模型进行预测(推断,inference):
predictions = model.predict(val_inputs, batch_size=128)
3. 神经网络入门:分类与回归
本章将使用前两章学到的知识完成三个新任务:影评分类(二分类问题)、新闻主题分类(多分类问题)和房价预测(标量回归问题)。
3.1 影评分类:二分类问题示例
3.1.1 IMDB数据集
本节使用IMDB数据集,包含来自IMDB的50000条两极化评论。我们将数据划分为25000条训练数据和25000条测试数据,训练集和测试集均各包含50%的正面和负面评论。
from tensorflow.keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
Keras中内置的IMDB数据集已经经过预处理——单词序列被转换为整数序列,每个整数对应字典中的某个单词。num_words用来指定仅保留训练数据中前10000个最常出现的单词,从而避免向量数据过大。
我们可以借助索引字典将整数序列重新还原为文本:
word_index = imdb.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
decoded_review = " ".join([reverse_word_index.get(i - 3, "?") for i in train_data[0]])
3.1.2 准备数据
整数序列表示的评论长度各不相同,我们需要先将其转换为长度相同的序列,从而用张量表示。常用的转换方法有两种:
- 填充列表,使长度相等,再将列表转换为
(samples, max_length)形状的整数张量。模型第一层使用Embedding层来处理这种张量。 - 对列表进行multi-hot编码,转换成由0和1组成的10000维向量,原整数序列中的元素指示该向量中对应索引处为1,其余为0。模型第一层使用Dense层。
我们采用multi-hot方法来处理数据:
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
for j in sequence:
results[i, j] = 1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
y_train = np.asarray(train_labels).astype("float32")
y_test = np.asarray(test_labels).astype("float32")
观察一下转换后的数据形状:
>>> print(x_train.shape, x_test.shape, y_train.shape, y_test.shape)
(25000, 10000) (25000, 10000) (25000,) (25000,)
3.1.3 构建模型
带relu激活函数的全连接层简单堆叠模型在“输入数据是向量,标签是标量”的问题上表现很好。我们使用两个16单元的中间层加一个输出层作为模型的架构:
model = keras.Sequential([
layers.Dense(16, activation="relu"),
layers.Dense(16, activation="relu"),
layers.Dense(1, activation="sigmoid")
])
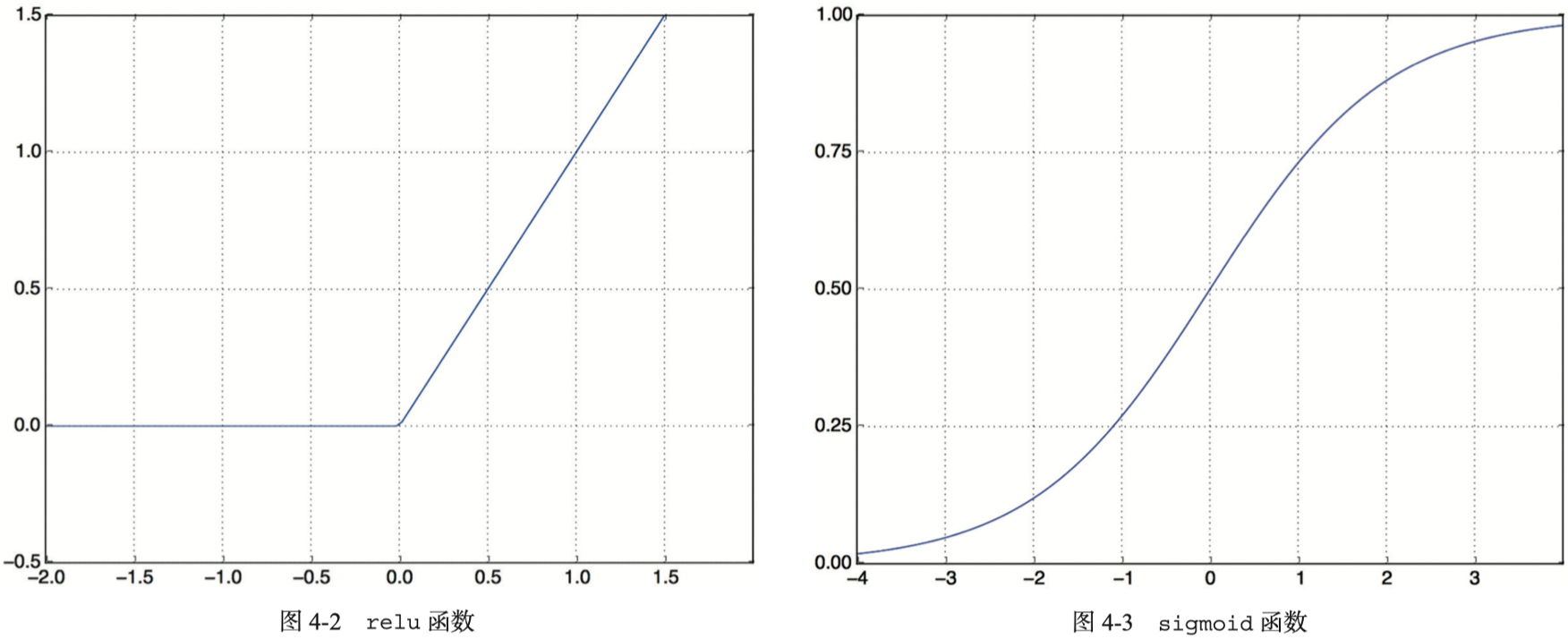
简单来说,relu函数将所有负值归零,sigmoid函数将任意值压缩到[0, 1]区间内,其输出可以视为概率值:
我们提到过,一个完全由没有激活函数的Dense层构成的多层神经网络在数学上等同于一个Dense层,假设空间是线性变换集合,非常有限。
如前所述,对于这个二分类问题,我们选择二元交叉熵作为损失函数。对于输出概率值的模型,交叉熵通常是最佳选择,用于衡量概率分布之间的距离。优化器则是rmsprop——它对于几乎所有问题都是很好的默认选择:
model.compile(optimizer="rmsprop", loss="binary_crossentropy", metrics=["accuracy"])
3.1.4 验证方法
接下来,从训练数据中留出10000个样本作为验证集,并训练模型:
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
训练完成,我们观察一下训练和验证过程中监控的指标:
import matplotlib.pyplot as plt
history_dict = history.history
loss_values = history_dict["loss"]
val_loss_values = history_dict["val_loss"]
epochs = range(1, len(loss_values) + 1)
plt.plot(epochs, loss_values, "bo", label="Training loss")
plt.plot(epochs, val_loss_values, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
plt.clf()
acc = history_dict["accuracy"]
val_acc = history_dict["val_accuracy"]
plt.plot(epochs, acc, "bo", label="Training acc")
plt.plot(epochs, val_acc, "b", label="Validation acc")
plt.title("Training and validation accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
可以看到,虽然训练指标都在不断变好,验证指标却不是这样——后者似乎在第4轮左右达到峰值,再往后就是过拟合现象:
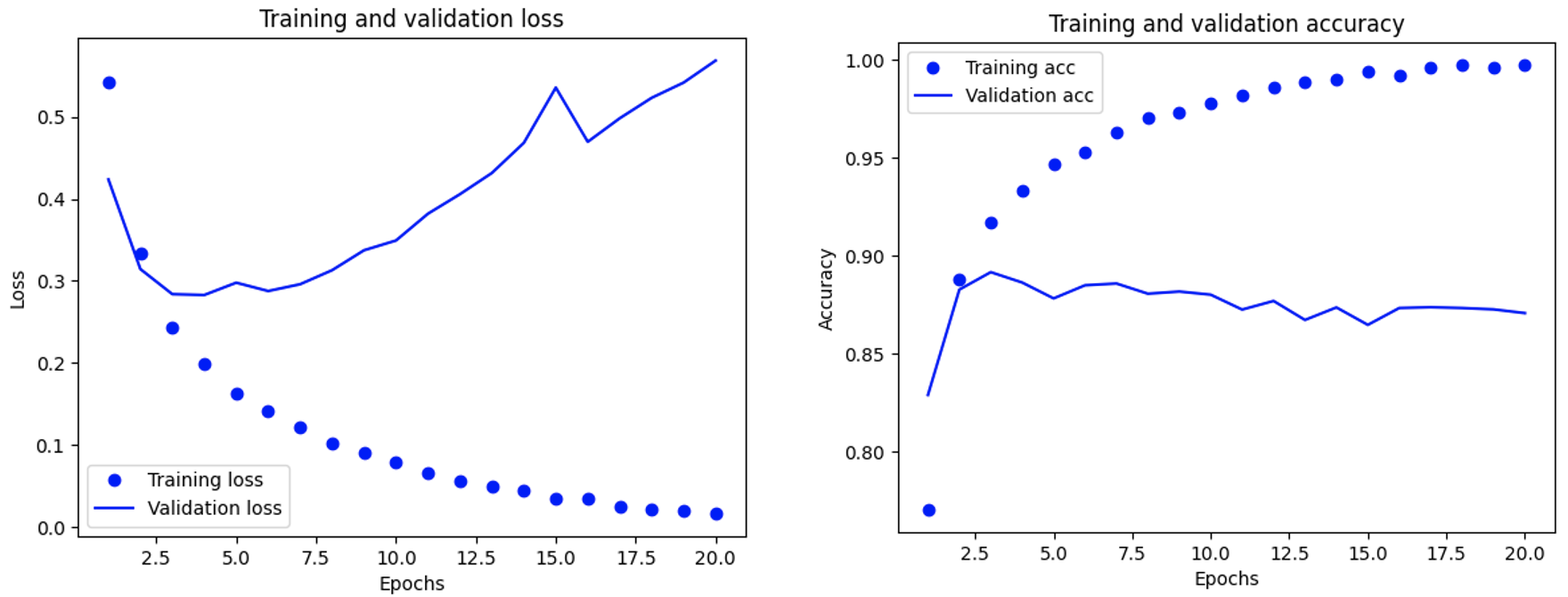
我们将训练轮数设置为4,重新训练,然后在测试集上评估模型:
model.fit(x_train, y_train, epochs=4, batch_size=512)
results = model.evaluate(x_test, y_test)
# results: [0.28500404953956604, 0.885919988155365]
可以看到,最终模型的测试精度大约为88.33%。最后,我们可以使用这个模型来对新数据进行预测,例如:
model.predict(x_test)
3.2 新闻分类:多分类问题示例
3.2.1 路透社数据集
本节的任务是构建一个模型,将路透社新闻划分到46个互斥的主题中。很明显,这是一个单标签、多分类问题。
首先加载数据集,这些数据包括46个主题,每个主题至少有10个样本:
from tensorflow.keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
至此,我们可以得到8982个训练样本和2246个测试样本。
3.2.2 准备数据
我们继续使用multi-hot方法将数据向量化:
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
标签向量化也有两种方法:
- 将标签列表转换为一个整数张量。
- One-hot编码(也叫分类编码,categorical encoding),与multi-hot类似,将每个标签表示为全零向量,只有标签索引位置的元素为1。
下面是one-hot编码的实现:
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
y_train = to_one_hot(train_labels)
y_test = to_one_hot(test_labels)
我们也可以直接使用Keras的内置方法进行one-hot编码:
from tensorflow.keras.utils import to_categorical
y_train = to_categorical(train_labels)
y_test = to_categorical(test_labels)
3.2.3 构建模型
上一个示例中的Dense层堆叠架构的局限性在于,每一层只能访问上一层输出的信息。如果上一层丢失了与分类相关的信息,后面的层永远无法恢复这些信息。因此,每一层都可能成为信息瓶颈。对于现在的示例来说,16维空间太小了,无法有效区分46个类别,我们需要使用维度更大的层:
model = keras.Sequential([
layers.Dense(64, activation="relu"),
layers.Dense(64, activation="relu"),
layers.Dense(46, activation="softmax")
])
注意,我们在最后一层使用了softmax激活函数,它将输出一个46维的向量,向量中的每个元素表示当前样本属于该类别的概率,总和为1。另外,对于这个例子来说,最好的损失函数是分类交叉熵:
model.compile(optimizer="rmsprop", loss="categorical_crossentropy", metrics=["accuracy"])
3.2.4 验证方法
从训练数据中留出1000个样本作为验证集,并训练模型:
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
训练完成,我们观察一下训练和验证过程中监控的指标:
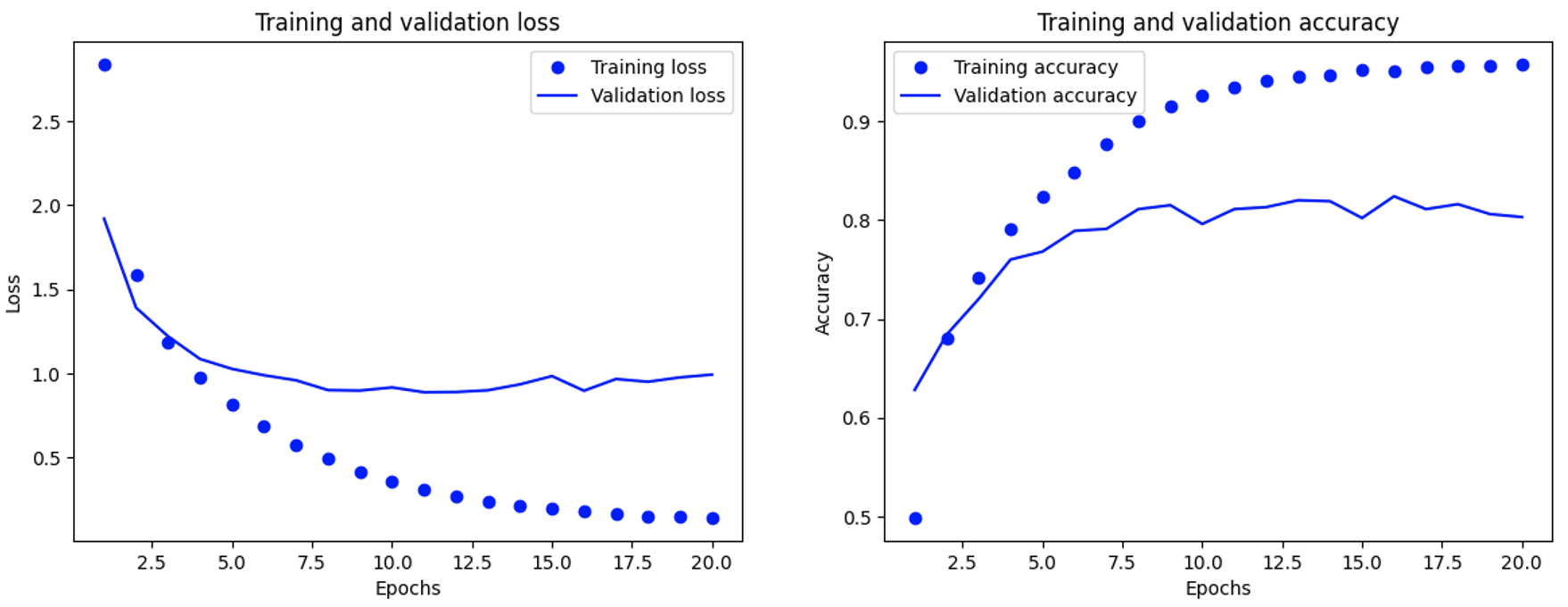
图像显示,模型在第9轮左右开始过拟合。我们将训练轮数设置为9,重新训练,然后在测试集上评估模型。结果显示测试精度大约为78.41%。
最后,我们可以使用这个模型来对新数据进行预测,向量的最大元素就是预测类别:
>>> predictions = model.predict(x_test)
>>> np.argmax(predictions[0])
3
3.2.5 处理标签和损失的另一种方法
我们也可以直接将标签列表转换为整数张量,作为标签使用。这种情况下,我们应该使用稀疏分类交叉熵作为损失函数:
y_train = np.array(train_labels)
y_test = np.array(test_labels)
model.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
3.2.6 拥有足够大的中间层的重要性
让我们减小中间层的维度,重新构建模型并训练:
model = keras.Sequential([
layers.Dense(64, activation="relu"),
layers.Dense(4, activation="relu"),
layers.Dense(46, activation="softmax")
])
这种情况下,模型的验证精度只有70.70%左右,比之前的78.41%下降不少。由此可见,中间层单元不应少于最终输出类别数,否则就会造成信息瓶颈。
3.3 房价预测:标量回归问题示例
这个示例是一个回归问题,预测的是连续值,而不是离散标签。另外注意,logistic回归不是回归算法,而是分类算法。
3.3.1 波士顿房价数据集
本节的任务是构建一个模型,根据20世纪70年代中期波士顿郊区的犯罪率、地方房产税率等数据预测房价中位数。数据集包含506个样本,其中有404个训练样本和102个测试样本:
from tensorflow.keras.datasets import boston_housing
(train_data, train_targets), (test_data, test_targets) = boston_housing.load_data()
数据集形状如下:
>>> train_data.shape
(404, 13)
>>> test_data.shape
(102, 13)
3.3.2 准备数据
样本的每个特征都有不同的取值范围,因此我们需要将它们标准化。常见的最佳处理方法是将每个特征减去其特征平均值,再除以标准差。这样得到的特征平均值为0,标准差为1。我们可以利用NumPy实现数据标准化:
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
test_data -= mean
test_data /= std
注意,对测试数据进行标准化时使用的平均值和标准差都来自训练数据。我们不能使用来自测试数据中的任何计算结果。
3.3.3 构建模型
样本数量少,因此我们构建一个小模型,以降低过拟合:
def build_model():
model = keras.Sequential([
layers.Dense(64, activation="relu"),
layers.Dense(64, activation="relu"),
layers.Dense(1)
])
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
return model
可以看到,模型的最后一层只有一个单元且无激活函数,是一个线性层。这是标量回归(预测单一连续值的回归)的典型设置。我们使用均方误差(mean squared error)作为损失函数,这是回归问题常用的损失函数。另外,我们还监控平均绝对误差(mean absolute error),即预测值与目标值之差的绝对值。
3.3.4 利用K折交叉验证来验证方法
由于样本少,验证集会非常小,这可能会导致验证分数有很大波动(验证分数对于验证集的划分方式有很大的方差)。这种情况下,最佳做法是进行K折交叉验证:
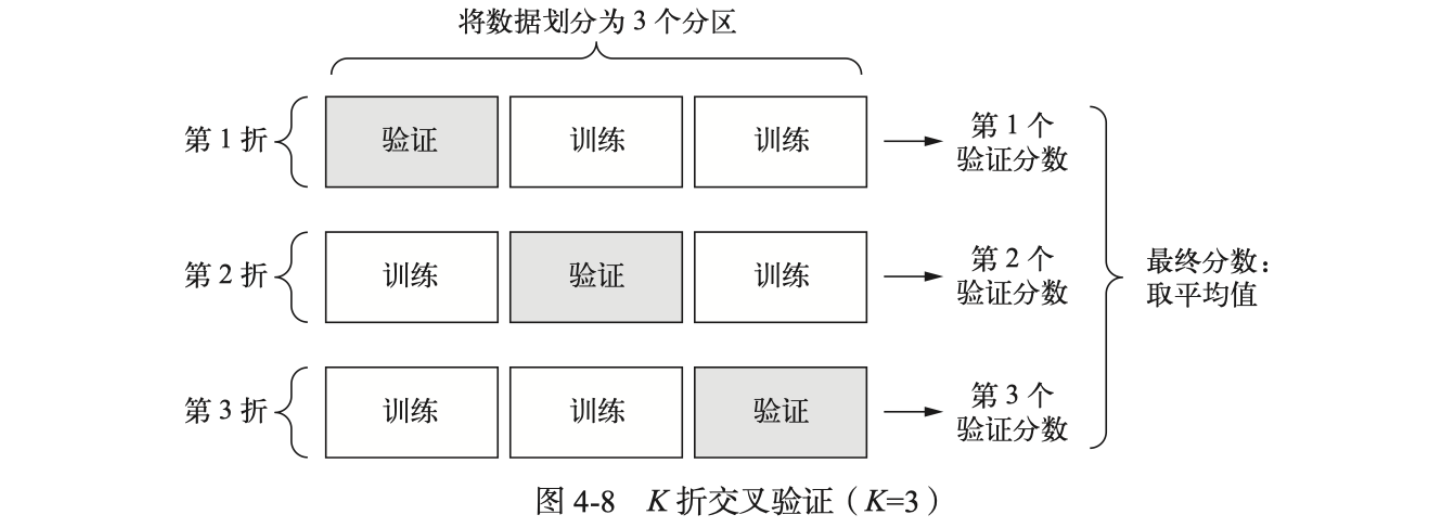
具体训练过程如下:
k = 4
num_val_samples = len(train_data) // k
num_epochs = 100
all_scores = []
for i in range(k):
print(f"Processing fold #{i}")
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
partial_train_data = np.concatenate(
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i + 1) * num_val_samples:]],
axis=0)
model = build_model()
model.fit(partial_train_data, partial_train_targets,
epochs=num_epochs, batch_size=16, verbose=0)
val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0)
all_scores.append(val_mae)
结果显示,预测房价与实际房价平均大约相差2362元:
>>> all_scores
[2.045789957046509, 2.4252355098724365, 2.456112861633301, 2.522847890853882]
>>> np.mean(all_scores)
2.362496554851532
最后,我们可以保存一下每次训练的验证分数:
num_epochs = 500
all_mae_histories = []
for i in range(k):
# ...
history = model.fit(partial_train_data, partial_train_targets, validation_data=(val_data, val_targets), epochs=num_epochs, batch_size=16, verbose=0)
mae_history = history.history["val_mae"]
all_mae_histories.append(mae_history)
# 计算每轮训练的K折验证分数平均值
average_mae_history = [np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)]
绘图展示一下验证MAE曲线变化情况:
# for left subgraph below
plt.plot(range(1, len(average_mae_history) + 1), average_mae_history)
plt.xlabel("Epochs")
plt.ylabel("Validation MAE")
plt.show()
# for right subgraph below
truncated_mae_history = average_mae_history[10:]
plt.plot(range(1, len(truncated_mae_history) + 1), truncated_mae_history)
plt.xlabel("Epochs")
plt.ylabel("Validation MAE")
plt.show()
由于前几轮的验证MAE远大于后面的轮次,我们很难看清这张图(下图左子图)的规律。因此,我们可以忽略前10个数据点,重新绘制图片(下图右子图):
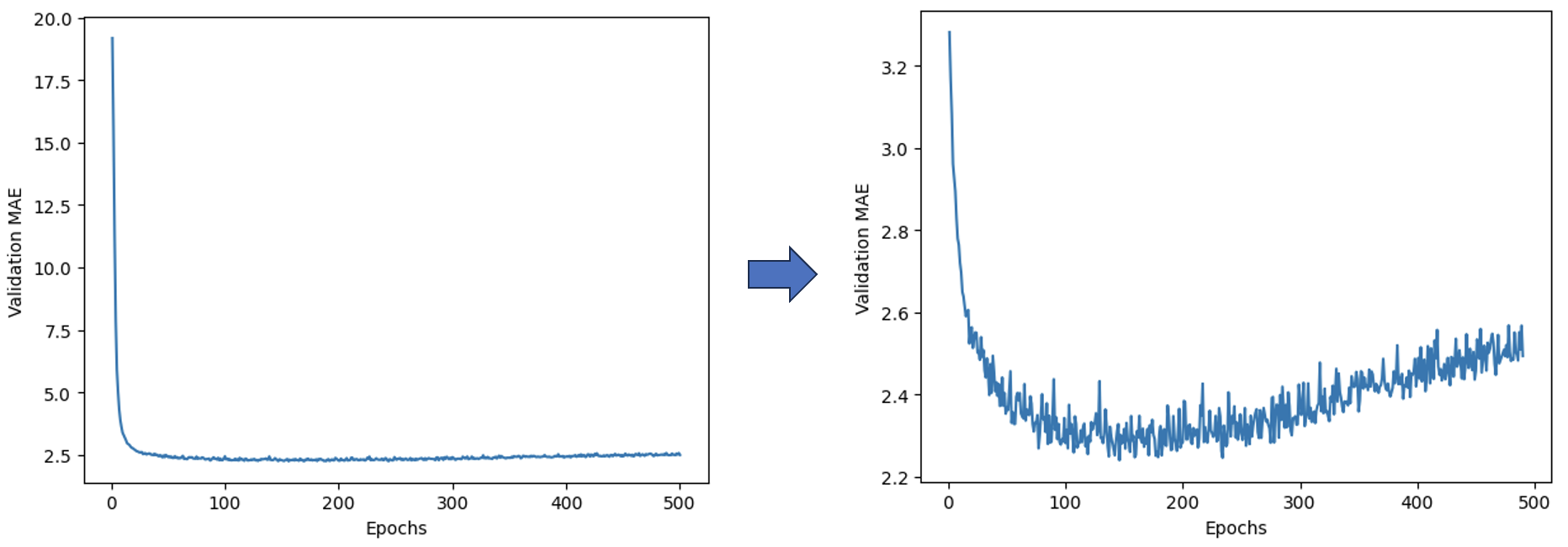
可以看到,模型大约在100~130轮过拟合。
4. 总结与思考
本文是原书第三、四章的笔记。我们学习了如何使用TensorFlow和Keras去处理简单的二分类、多分类和回归学习任务。这些例子很有意思。另外,从这些实践中,我学习到的一个重要经验是,先让训练出现过拟合现象,然后通过观察训练过程找到最佳的训练轮数,再次从头训练模型,从而得到最好的表现。