前言
学了这么久的程序分析,终于到了安全相关的部分。由于课程本身是程序分析,这节课也并没有非常深入地探讨安全领域的应用,主要是结合简单的例子对污点分析进行了介绍。不过,谭添老师讲得很好,无论是前面的引导过程还是后面的污点分析算法,一如既往,十分易懂。打好基础,后面就是“修行在个人”了。
对于安全领域的同学来说,本节课前半部分很简单,但是胜在旁征博引,在介绍各概念时给出的文献非常值得深入研读,从而了解信息安全在学术界的发展历史。
在主要内容之前,结合OWASP Top 10和NIST NVD漏洞库数据,谭老师介绍,2013-2019年间两个漏洞根因值得重视:注入错误(injection errors)和信息泄露(information leaks)。
信息流(Information Flow)安全
Dorothy E. Denning于1976年在论文A Lattice Model of Secure Information Flow提出,一个系统需要访问(access)和流(flow)控制来满足所有安全要求。
访问控制(access control)用来确保程序有权限访问特定信息,主要关心信息是如何被访问的。
信息流安全则是一种端到端的思路,通过追踪信息流通过一个程序的过程,确保该程序能够安全地处理信息,主要关心信息是如何被传播的。
Dorothy E. Denning与Peter J. Denning夫妇二人1977年的论文Certification of Programs for Secure Information Flow对信息流做了如下解释:如果变量$x$中的信息被传送到变量$y$,它们之间就建立了一条信息流$x \rightarrow y$。这看起来与我们前面学过的指针分析十分相似。
一种将信息流和安全联系起来的思路是,将不同类型的变量划分到不同的安全等级(security levels),在这些等级之间建立允许的流,从而形成信息流策略。不同实际场景下的安全等级千差万别,可以很复杂也可以很简单。考虑最简单的情况:只有H(高)和L(低)两个安全等级,下面两行代码就分别对应了这两个等级:
h = getPassword(); // h is high security
broadcast(l); // l is low security
另外,我们也可以在格(lattice)上对安全等级进行建模(来自前面提到的第一篇论文):$L \leq H$。
所谓“信息流策略”,用来限制信息流在不同安全等级之间的流动。例如,J. A. Goguen和J. Meseguer于1982年在论文Security Policies and Security Models中提出了一个信息流策略——不干涉策略(noninterference policy),它要求高安全等级的变量中的信息不应对低安全等级的变量中的信息有任何影响。因此,你也不应该能通过观察低安全等级的变量来获得任何高安全等级的信息。对应到代码上,形如$x_{L} = y_{H}$这样的语句就违背了这一信息流策略。
在格的视角下,上述策略可以表达为,应确保信息在安全等级的格中向上流动。
机密性(Confidentiality)和完整性(Integrity)
众所周知,信息安全三要素包括机密性(confidentiality)、完整性(integrity)和可用性(availability)。本节课讨论的是信息流,因此重点关注前两个要素。
确保机密性,通俗意义上就是阻止敏感信息泄露;确保完整性,就是避免不受信的信息污染了受信(重要)的信息(这一说法来自Ken Biba于1977年发表的论文Integrity Considerations for Secure Computer Systems)。常见的各种注入问题就是损害了完整性。
有意思的是,结合前面讨论的安全等级相关的知识来看,机密性和完整性恰好是对称的:确保机密性,就是要避免高安全等级的秘密信息流向低安全等级的公开区域,属于读保护;确保完整性,就是要避免低安全等级的不可信信息流向高安全等级的可信区域,属于写保护。
另外,完整性本身也是一个覆盖广泛的概念。它可以包括数据的正确性(correctness)、完全性(completeness)和一致性(consistency)。
显式流(Explicit Flows)和隐蔽信道(Covert Channels)
我们继续来讨论信息流。“信息”本身是一个抽象的概念,它并不等同于数据。信息可能会有两种不同的传播方式:显式流和隐式流(implicit flow)。
前者很简单,例如,$x_{L} = y_{H}$这个语句就是通过直接复制/赋值的方式实现信息传递,也就是显式流。隐式流则不那么直观,基于此途径的敏感信息泄露也相对而言不那么好防御。现实中已经有许多这样的例子。例如,在下面的代码片段中,根据$publik_{L}$的结果,我们将能够推断$secret_{H}$的正负性:
secret_H = getSecret();
if (secret_H < 0) publik_L = 1;
else publik_L = 0;
敏感信息虽然没有直接传播,但是它影响了控制流,这可能会被低安全等级的观察者观察到。
通过计算系统传递信息的机制被称作信道(channels)。在此基础上,Butler W.Lampson于1973年发表的文章A Note on the Confinement Problem将那些利用本非用于信息传递的机制的信道称为隐蔽信道。一些常见的隐蔽信道包括:
- 隐式流,通过程序控制结构传递信息。
- 终止(termination)信道,通过程序的(不)可终止性差异传递信息。
- 时间(timing)信道,通过计算时间的差异传递信息。
- 异常(exceptions),通过异常来传递信息。
尽管隐蔽信道比较难识别和防御,它能够传递的信息通常也比显式流少得多。因此,本课程主要关注显式流。一个问题是,如何检测和避免非预期的信息流呢?接下来将要讨论的污点分析是有效的解决方案之一。
污点分析(Taint Analysis)
污点分析是最常见的信息流分析技术之一。它将程序数据分为两类:
- 感兴趣的数据,带有某些标签,也叫做污点数据。
- 其他数据,或者叫无污点数据。
污点数据的源头称为sources。实际场景中,污点数据通常来自某些方法的返回值。污点分析技术将追踪污点数据在程序中的流动过程,观察它们是否流到我们感兴趣的地方(locations of interest),这些地方又称作sinks。实际场景中,sinks通常是一些敏感方法。Source和sink是污点分析中非常重要的两个概念。
前面我们提到过损害机密性的敏感数据泄露威胁和损害完整性的注入威胁,事实上,污点分析能够用来发现这两类威胁。对于前者来说,source是敏感数据的来源,sink是泄露点;对于后者来说,source是不受信数据的来源,sink是重要的计算语句(如eval函数)。下面的两段代码分别展示了这两个场景:
// information leak
x = getPassword(); // source
y = x;
log(y); // sink
// injection error
x = readInput(); // source
cmd = "..." + x;
execute(cmd); // sink
污点分析要回答的问题是,某个特定的污点数据能否流到某个sink处,或者从另一个角度来看,在一个sink处某个指针能够指向哪些污点数据。
Neville Grech和Yannis Smaragdakis于2017年发表的论文P/Taint: Unified Points-to and Taint Analysis指出,污点分析可以基于指针分析进行,因为两者非常相似——前者考察的是污点数据如何在程序中流动,后者考察的是抽象对象如何在程序中流动。我们只需要将污点数据当作一种特殊的“人造”对象,将sources当作污点数据的allocation sites,然后应用指针分析来传播污点数据即可。
事实上,上节课学习的上下文敏感的指针分析也可以用于污点分析,从而提高分析精度。不过,谭老师后面并没有给出上下文敏感的分析案例,而是用一个简单的上下文不敏感分析来讲解。
污点分析的域和记法与指针分析基本相同,除了新增的污点数据部分:
- Variables: $x, y \in V$
- Fields: $f, g \in F$
- Objects: $o_{i}, o_{j} \in O$
- Tainted data: $t_{i}, t_{j} \in T \subset O$
- Instance fields: $o_{i}.f, o_{j}.g \in O \times F$
- Pointers: $\text{Pointer} = V \cup (O \times F)$
- Points-to relations: $pt: \text{Pointer} \rightarrow P(O)$
其中,$t_{i}$表示该污点数据来自call site $i$,$P(O)$表示$O$的幂集,$pt(p)$表示$p$的指向集合。
污点分析的输入如下:
- Sources:由source方法(被调用后返回污点数据的方法)组成的集合。
- Sinks:由携带敏感实参的sink方法(污点数据流向这些方法的实参,违背了安全策略)组成的集合。
污点分析的输出是TaintFlows,它是由“source和sink方法调用构成的元组”组成的集合。
污点分析的规则与指针分析基本相同,除了新增的两条处理sources和sinks的规则:
| 种类 | 语句 | 规则 |
|---|---|---|
| Call | l: r = x.k(a1, ..., an) |
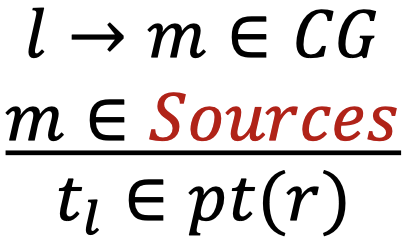 |
| Call | l: r = x.k(a1, ..., an) |
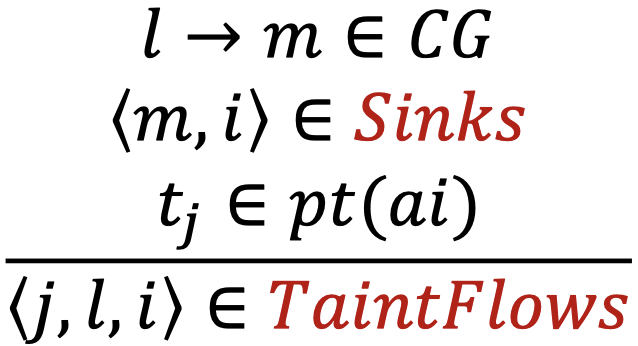 |
下面是一个污点分析的案例:
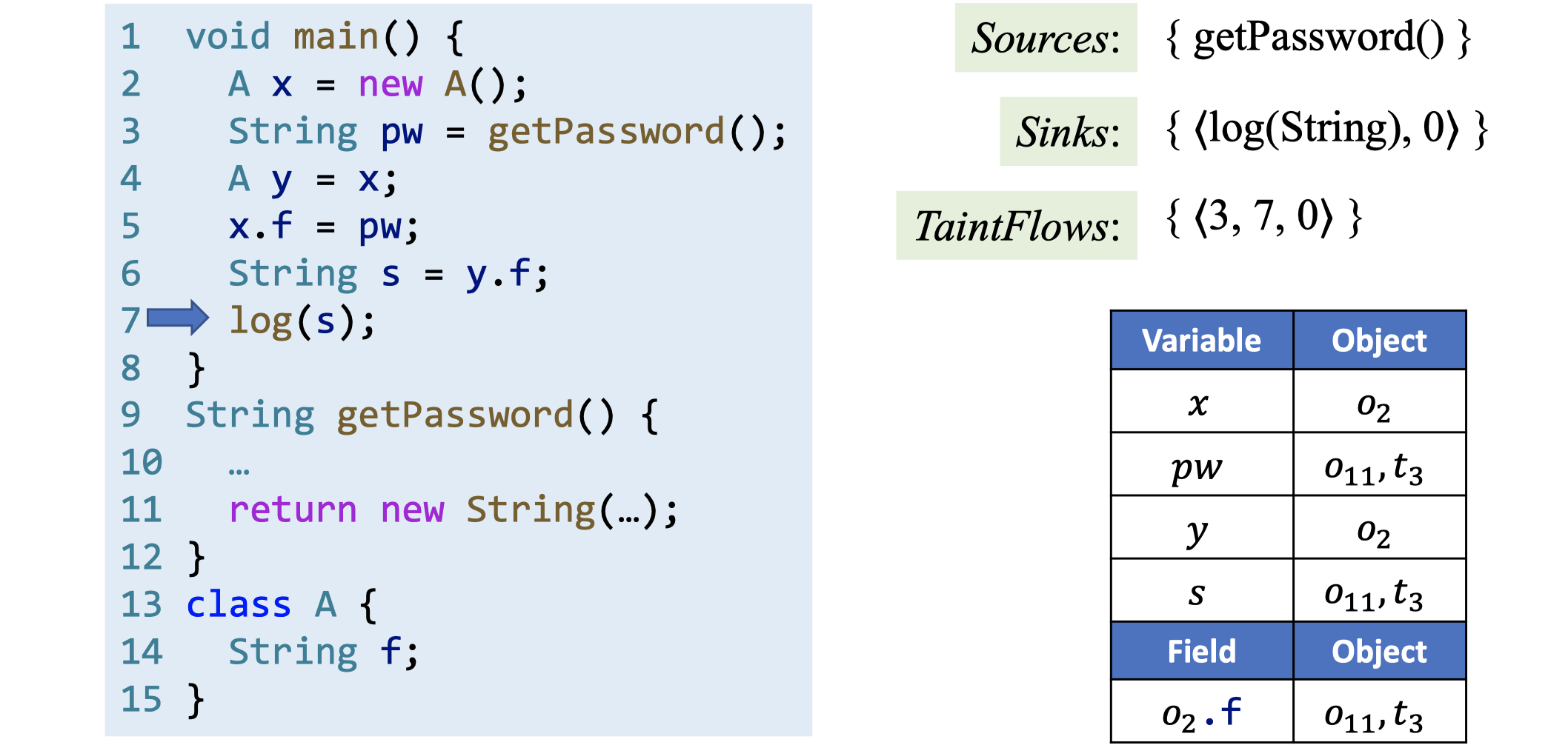
从该案例可以看出,污点分析是伴随指针分析进行的。最终的输出TaintFlows中的<3, 7, 0>表示第3行处的敏感方法getPassword的返回值传播到了第7行的危险方法log的第0个参数,说明该程序可能存在信息泄露漏洞。
总结与思考
本节课我们学习了信息流安全、机密性及其威胁、完整性及其威胁、显式流与隐蔽信道、污点分析等知识和技术,这些内容很有意思。不过,更有意思的还在后面。课程结束后,我们将把学到的技术应用到真实的安全研究中。