博士生的日常“娱乐”活动之一就是读论文。收集的论文多了,就往往想进行论文管理。论文管理的目的之一,是希望快速找到自己整理过的、与某个研究问题高度相关的文献。有时候,我们也会借助Connected Papers之类的学术情报工具,给定一篇论文,找出并可视化与之相关的文献,实现对一个话题、甚至一个领域的快速了解。
于我而言,这类学术情报工具确实有适用的场合,但是有局限性。最主要的原因是,尽管已经过滤了很多无效信息,它们提供的信息还是太多了,尤其是在文献关系上。如下图所示,给定一篇论文,Connected Papers能直接给你生成一个包含很多文献的图谱:
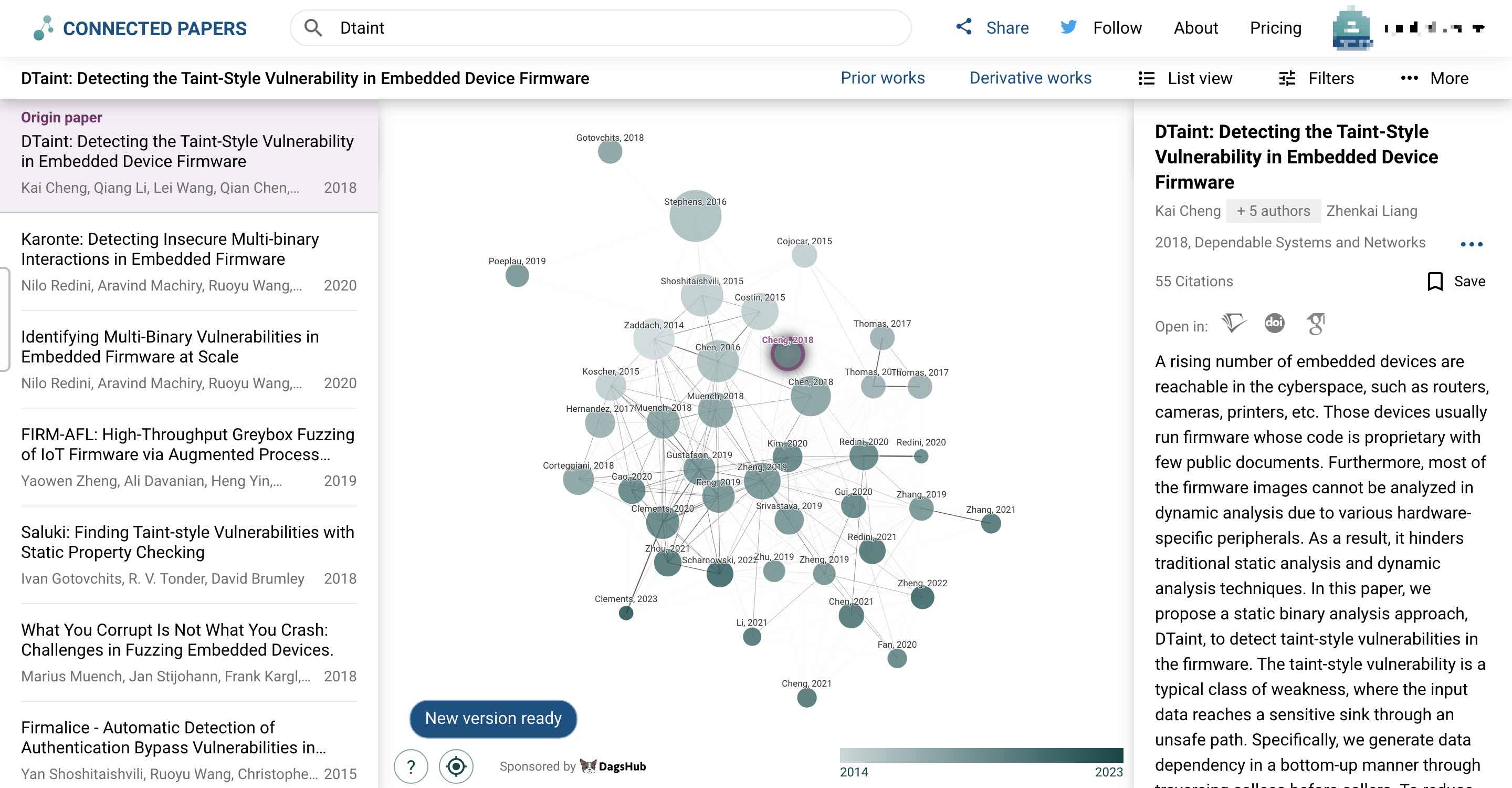
这个图谱对于领域探索很有帮助,但是它最终呈现的结果并不是我想作为个人知识长期维护的信息(当然,它的用途也并不在此)。那么,我为什么要提它呢?因为它很接近我想要的最终形态——有一个类似图谱的东西,能够在我阅读论文的过程中逐渐成长、丰富,允许我手动添加论文节点,能够很好地展示出我关注的研究问题的大概分类,体现出已有工作之间的基本关系,并能够给出一些涉足某个研究问题可能需要的技术,供我反省、规划、查缺补漏。它还必须是简洁的,或至少是按照我的思考逻辑生成的。一言蔽之,我希望维护一个自己关注的研究问题的图谱。
提炼了一下,我发现自己的需求其实比较简单:为读过的文献维护一个渐进式增长的图谱;图谱中的关系须是强相关关系,且只有两类,表示为有向边:
- 比较关系:论文A提出了一个新方法,与目前的SOTA或已有工作B、C、D对比。这个关系暗示这些工作可能是针对相同或相似的研究问题。如果我想要涉足这个领域,需要对这些工作都非常清楚。在图谱中,如果论文A、B、C都与D进行对比,那么D大概率是该领域发表比较早、且比较经典有代表性的工作。
- 依赖关系:论文A是对论文B提出的方法的扩展,或者是对论文C、D的方法的结合,或者是复用了论文E产出的工具。这个关系为有目的学习指明了方向。在图谱中,如果论文A、B、C都依赖了论文D产出的工具,那么D大概率是我们进入这个领域必须要掌握的。
比较关系往往可以从论文的“评估”部分总结;依赖关系往往来自论文的“实现”部分。我有意规避了“相关工作”和“参考文献””,因为其中非强相关的文献太多了。
Obsidian的双链可视化功能很好地实现了我的需求。操作很简单,我只需要将论文按照标题保存为Obsidian中的markdown文件,并为自己提炼的、与当前论文存在上述两类关系的研究同样按此方式建立markdown文件,最后使用Obsidian的双链索引将后者写入前者的文件中即可。借助可视化图谱,我们就能很方便地审视自己的研究范围、文献关系和常用技术了。
在使用过程中,有时我们会发现这样一个现象:好几篇某个领域(甚至跨领域)的论文都使用了某篇基础论文涉及到的框架。例如,几乎所有涉及到静态源码级C/C++程序分析的研究问题都使用了LLVM来生成IR或执行分析。这个现象与我们的经验一致——LLVM确实对于这些研究问题非常重要,因此也非常值得学习。如果图谱上所有这些论文都向LLVM的论文伸出一条有向边,图的连通性将会大大提高,但这在分辨不同的研究问题时可能带来困扰。然而,像LLVM这样的节点的存在又能够不断提醒我们(尤其是初来乍到的博士生)在迷失方向、不知道该做什么时应该主动去掌握哪些内容。
对此,我的处理方法是,从Obsidian中删除LLVM论文对应的markdown文件,但是在所有其他论文的markdown文件中继续使用双链对其按需进行引用。Obsidian的图谱视图提供了选项,允许我们选择“只显示存在的文件”。借助这个选项,我们可以按需切换到不同的视图。在想要减少图的连通性、回顾自己读过的论文大概可以聚类到哪些研究问题时,打开这个选项;在想要查看不同论文依赖的超基础框架时,关闭这个选项。
下面是基于Obsidian进行上述文献关系可视化展示的示例:
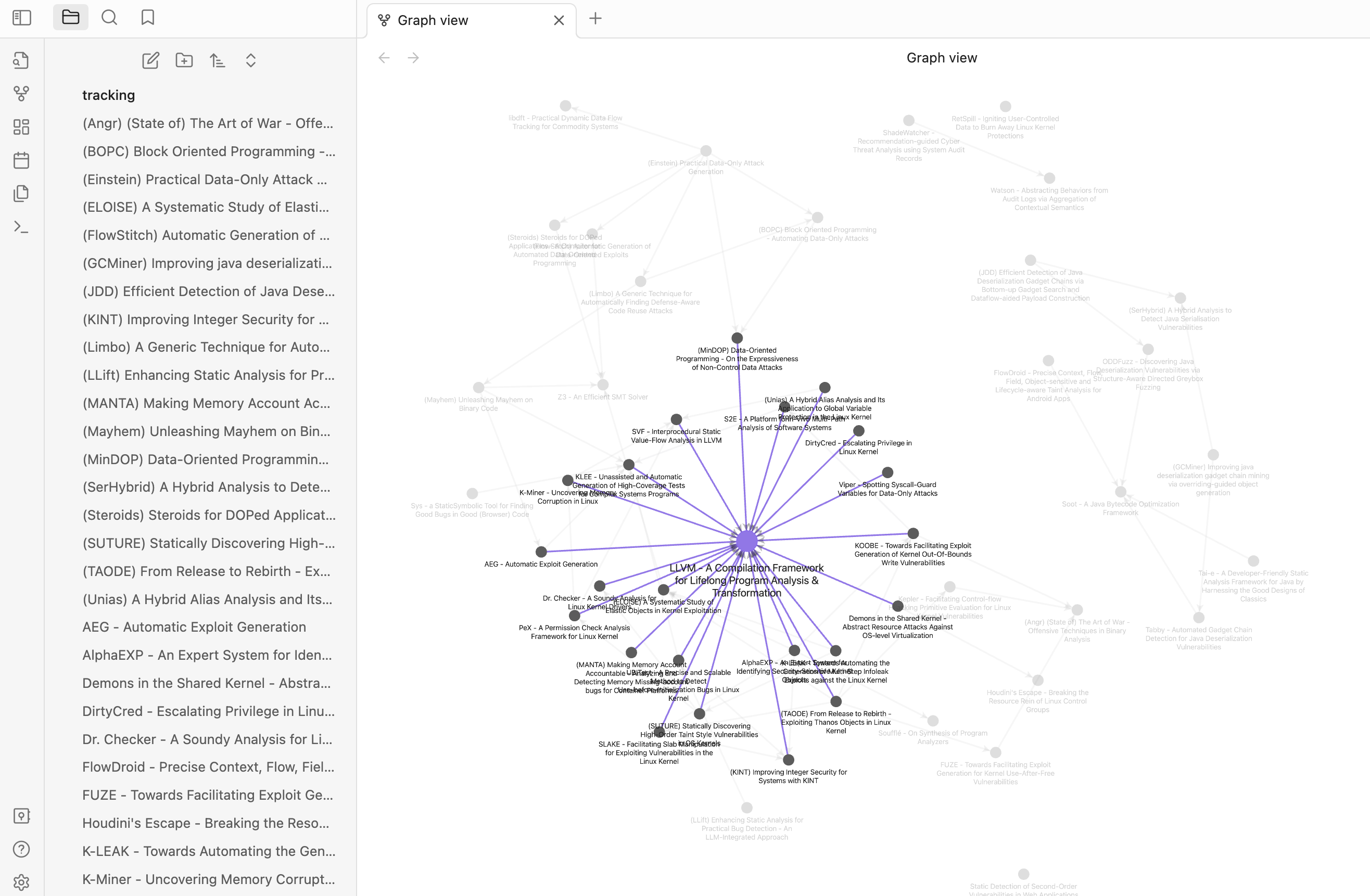
借助这个图谱,我发现了更多自己关注的文献之间的有趣联系,了解了大家做相关研究时常用的框架、工具。另外,Obsidian本身是一个笔记软件,这意味着你完全可以把每个文件当作论文笔记来使用,这大概是其他纯粹的图谱可视化工具不具备的。当然了,Obsidian也有局限性,比如我们无法区分“比较关系”和“依赖关系”。然而,这对我来说并不是必要的。少即是多,去粗存精。只要图谱上呈现的全是强相关关系,操作不至于那么复杂,就够了。