生产者-消费者模型
生产者-消费者问题是一个著名的进程通讯问题。
模型可以被描述为:在一个系统中有多个生产者和多个消费者,一块有限大小缓冲区。生产者按一定速度每次将一个数据送入缓冲区,消费者按一定速度每次从缓冲区取走一个数据。一旦缓冲区满,生产者将停止活动直到缓冲区有空隙;一旦缓冲区空,消费者将停止活动直到缓冲区有数据。另外,多个生产者之间要同步下一个放置数据的缓冲区位置,多个消费者之间要同步下一个取走数据的缓冲区位置。
模型可以用下图表示(假设有 4 个生产者和 4 个消费者):
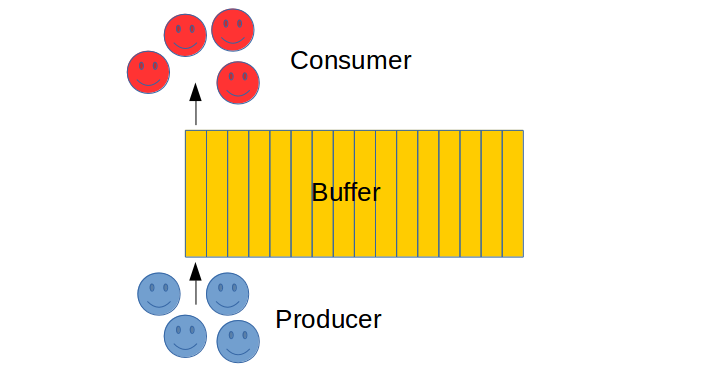
需要注意的是,生产者的生产速度可能不同,消费者消费速度可能不同,生产者和消费者之间的速度也没有关系。所以如果不加以控制,任由生产者消费者随意访问缓冲区,则会造成数据丢失、效率低下等问题。
问题抽象及解决方案
上述问题的解决方案就是同步和互斥。
后面,我们将使用两种 Linux 中的进程通讯机制来编程模拟生产者-消费者模型:
- POSIX 共享内存
- POSIX 信号量
为了突出重点,我们定义并将问题简化为如下几点:
- 环境中有 10 个生产者和 10 个消费者
- 生产者/消费者角色由进程表示
- 一个进程开两个线程,分别做生产者和消费者的工作
- 系统总共需要 10 个上述进程
- 所有生产者速度相同,所有消费者速度相同,速度可更改
- 生产者和消费者的速度可以不同
- 生产和消费的单位数据为一个结构体,具体内容在后面给出
- 缓冲区能容纳 100 个上述结构体
伪代码描述
这部分对生产者-消费者问题解决方案进行伪代码描述。
生产者伪代码:
while(1) {
// 生产一个数据
// 申请缓冲区空间,如若没有则挂起(同步)
// 检查是否有其他进程访问缓冲区,如有则挂起(互斥)
// 把数据放入缓冲区相应位置
// 把生产者指针向下移动一格(循环移动)
// 离开缓冲区,唤醒其他可能的等待进程(互斥)
// 唤醒可能在等待数据的消费者(同步)
}
消费者伪代码:
while(1) {
// 如果缓冲区有数据则继续,否则挂起(同步)
// 检查是否有其他进程访问缓冲区,如有则挂起(互斥)
// 从缓冲区相应位置取走数据
// 把消费者指针向下移动一格(循环移动)
// 离开缓冲区,唤醒其他可能的等待进程(互斥)
// 唤醒可能在等待缓冲区空间的生产者(同步)
}
编程实现
一些参数定义如下:
// 缓冲区容纳数据个数
#define CANDY_NUM 100
// 数据结构体
struct candy{
u_int ID;
pid_t PID;
time_t TIME;
};
// 生产者速度(每隔秒)
const pVelocity = 0.3;
// 消费者速度(每隔秒)
const cVelocity = 10;
从上面的分析我们可以发现,所有生产者和消费者共用缓冲区,所有生产者共用一个指向下一个空位的缓冲区指针,所有消费者共用一个指向下一个有数据位置的缓冲区指针。另外,需要三个信号量,分别用于互斥,告知缓冲区有空位,告知缓冲区有数据。
为了方便,我们为两个缓冲区指针和缓冲区整体申请一块共享内存:
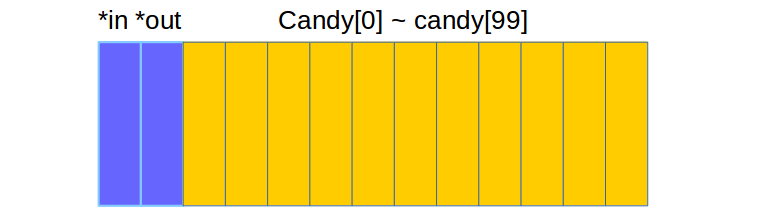
我们把共享相关的量放到一个结构体中:
struct SharedElements{
// 消费者用于以数据结构体形式引用共享内存的指针
struct Candy *candy;
// 共享内存的起始地址
char *sMemPtr;
// 共享内存中数据结构体数组的起始地址(去掉开头两个指针)
char *candyBegin;
// 上述生产者的指针
u_int *in;
// 上述消费者的指针
u_int *out;
// 互斥信号量
sem_t *mutex;
// 缓冲区有空位
sem_t *empty;
// 缓冲区有数据
sem_t *full;
}shares;
涉及共享内存和信号量的参数定义如下:
// 共享内存的名字
const char sharedMem[] = "/test001";
// 互斥信号量的名字
const char mutexName[] = "mutex001";
// “缓冲区有数据”信号量的名字
const char fullName[] = "full001";
// “缓冲区有空位”信号量的名字
const char emptyName[] = "empty001";
// 共享内存总长度(单位:字节)
const int sharedLen = sizeof(u_int) * 2 + sizeof(struct candy) * CANDY_NUM;
将信号量函数封装为 PV 操作:
void P(sem_t *sem)
{
sem_wait(sem);
}
void V(sem_t *sem)
{
sem_post(sem);
}
设置打印数据结构体的函数以便观察结果:
void ShowCandy(struct candy *myCandy, FILE *fp)
{
fprintf(fp, "ID: %u\n", myCandy->ID);
fprintf(fp, "PID: %d\n", myCandy->PID);
fprintf(fp, "Time: %s\n", ctime(&(myCandy->TIME)));
return;
}
将生产语义具体化为数据结构体的赋值:
int PackCandy(struct candy *new, u_int ID)
{
new->PID = getpid();
new->TIME = time(0);
new->ID = ID;
ShowCandy(new, stdout);
return 0;
}
将消费语义具体化为将数据结构体内容记录到日志:
const char logFile[] = "./candy.log";
int EatCandy(struct candy *mine)
{
FILE *fp;
if((fp = fopen(logFile, "a")) == NULL){
perror("fopen");
return -1;
}
ShowCandy(mine, fp);
fclose(fp);
return 0;
}
至此,辅助工作已经完成。下面将完成生产者和消费者线程:
生产者的流程:
void *Producer(void *vargp)
{
struct candy newCandy;
u_int ID = 0;
while(1){
PackCandy(&newCandy, ID);
ID++;
P(shares.empty);
P(shares.mutex);
printf("produce\n");
memcpy((shares.candyBegin + sizeof(struct candy) * (*(shares.in))), \
&newCandy, sizeof(struct candy));
*(shares.in) = (*(shares.in) + 1) % CANDY_NUM;
V(shares.mutex);
V(shares.full);
sleep(pVelocity);
}
return NULL;
}
消费者的流程:
void *Consumer(void *vargp)
{
while(1){
P(shares.full);
P(shares.mutex);
shares.candy = (struct Candy *)(shares.candyBegin + sizeof(struct candy) * (*(shares.out)));
printf("eat\n");
EatCandy(shares.candy);
*(shares.out) = (*(shares.out) + 1) % CANDY_NUM;
V(shares.mutex);
V(shares.empty);
sleep(cVelocity);
}
return NULL;
}
下面介绍main函数。为了能够统一共享内存和信号量的创建和删除以及使用,main函数的基本逻辑如下:
带一个参数时:
-c 创建共享内存/信号量
-u 删除共享内存/信号量
不带参数时:
开启生产者消费者线程
在每次实验之前,先./pc -c:

在每次实验结束后,要./pc -u:

下面是对参数的处理:
#define FILE_MODE S_IRUSR | S_IWUSR
#define PROT_MODE PROT_READ | PROT_WRITE
if(argc == 2){
if(strcmp(argv[1], "-c") == 0){
// create shared memory object
if((fd = shm_open(sharedMem, O_RDWR | O_CREAT, FILE_MODE)) == -1){
perror("shm_open");
return -1;
}
if(ftruncate(fd, sharedLen) == -1){
perror("ftruncate");
return -1;
}
shares.sMemPtr = mmap(NULL, sharedLen, PROT_MODE, MAP_SHARED, fd, 0);
close(fd);
printf("Shared memory created\n");
// create semaphore mutex
if((shares.mutex = sem_open(mutexName, O_CREAT | O_EXCL, FILE_MODE, 1)) == SEM_FAILED){
perror("sem_open");
return -1;
}
sem_close(shares.mutex);
printf("Mutex created\n");
// create semaphore empty
if((shares.empty = sem_open(emptyName, O_CREAT | O_EXCL, FILE_MODE, CANDY_NUM)) == SEM_FAILED){
perror("sem_open");
return -1;
}
sem_close(shares.empty);
printf("Empty created\n");
// create semaphore full
if((shares.full = sem_open(fullName, O_CREAT | O_EXCL, FILE_MODE, 0)) == SEM_FAILED){
perror("sem_open");
return -1;
}
sem_close(shares.full);
printf("Full created\n");
}
else if(strcmp(argv[1], "-u") == 0){
// unlink shared memory object
if(shm_unlink(sharedMem) == -1){
perror("shm_unlink");
return -1;
}
printf("Shared memory unlinked\n");
if(sem_unlink(mutexName) == -1){
perror("sem_unlink");
return -1;
}
printf("Mutex unlinked\n");
if(sem_unlink(emptyName) == -1){
perror("sem_unlink");
return -1;
}
printf("Empty unlinked\n");
if(sem_unlink(fullName) == -1){
perror("sem_unlink");
return -1;
}
printf("Full unlinked\n");
}
return 0;
}
下面是不带参数的实验流程:
// open shared memory object
if((fd = shm_open(sharedMem, O_RDWR, FILE_MODE)) == -1){
perror("shm_open");
return -1;
}
shares.sMemPtr = mmap(NULL, sharedLen, PROT_MODE, MAP_SHARED, fd, 0);
shares.in = (u_int *)shares.sMemPtr;
shares.out = (u_int *)(shares.sMemPtr + sizeof(u_int));
shares.candyBegin = (shares.sMemPtr + sizeof(u_int) * 2);
close(fd);
if((shares.mutex = sem_open(mutexName, 0)) == SEM_FAILED){
perror("sem_open");
close(fd);
return -1;
}
if((shares.full = sem_open(fullName, 0)) == SEM_FAILED){
perror("sem_open");
close(fd);
return -1;
}
if((shares.empty = sem_open(emptyName, 0)) == SEM_FAILED){
perror("sem_open");
close(fd);
return -1;
}
pthread_t ptid, ctid;
pthread_create(&ptid, NULL, Producer, NULL);
pthread_create(&ctid, NULL, Consumer, NULL);
pthread_join(ptid, NULL);
pthread_join(ctid, NULL);
sem_close(shares.mutex);
sem_close(shares.empty);
sem_close(shares.full);
注意,在编译时要加上-pthread -lrt选项。
下面是最后一点准备工作:
- 模拟十个进程的 bash 脚本:
#!/bin/bash
./pc &
./pc &
./pc &
./pc &
./pc &
./pc &
./pc &
./pc &
./pc &
./pc &
- 杀死所有测试进程的 bash 脚本:
#!/bin/bash
ps -ef | grep './pc' | head -n 10 | cut -d' ' -f 2 | xargs kill -15
对于candy.log日志文件,可以用tail -f ./candy.log动态查看其内容。
测试结果
在生产者生产速度明显快于消费者消费速度时(pVelocity=0.3, cVelocity=10):
可以看到生产者刚开始一下生产很多,后面的速度依赖于消费者。
这是一个动态的过程,故不再放截图。大家可以自行测试。
借助 Linux IPC,我们较好地解决了生产者-消费者问题。
参考资料
- 深入理解计算机系统 第三版
- Unix Network Programming Volume 2 (2 edition)