Introduction
As large language models (LLMs) have shown their efficacy in lots of language-related fields, researchers in the field of information security are eager to employ this power to solve security problems (e.g., vulnerability detection and reverse engineering) as well. To learn about how LLM helps in vulnerability detection and how far we are, in this report, we collect, categorize, and briefly summarize 18 studies on LLM for vulnerability detection available on the Internet, from not only conferences and journals, but also arXiv.
The studies are categorized into three topics: LLM-powered vulnerability detection, LLM-assisted fuzzing and LLM-assisted program analysis, which provide a systemic view of LLM’s promising application in vulnerability detection.
| Topic | Research |
|---|---|
| LLM-powered Vulnerability Detection |
GPTScan [4], Zhou et al. [7], Zhang et al. [9], LLM4Vuln [10], David et al. [11], Chan et al. [16], Chen et al. [12], VulBench [13], Khare et al. [14], GPTLens [8] |
| LLM-assisted Fuzzing |
ChatAFL [1], Fuzz4All [2], FuzzGPT [3], TitanFuzz [5], KernelGPT [15], ChatFuzz [18] |
| LLM-assisted Program Analysis | LLift [6], LATTE [17] |
The targets in these studies span various objects, including Linux kernel, smart contracts, deep-learning libraries, compilers, firmwares, and protocols.
Topic 1: LLM-powered Vulnerability Detection
10 out of 18 studies aim to detect vulnerabilities by directly sending the source code and other information to LLM for auditing.
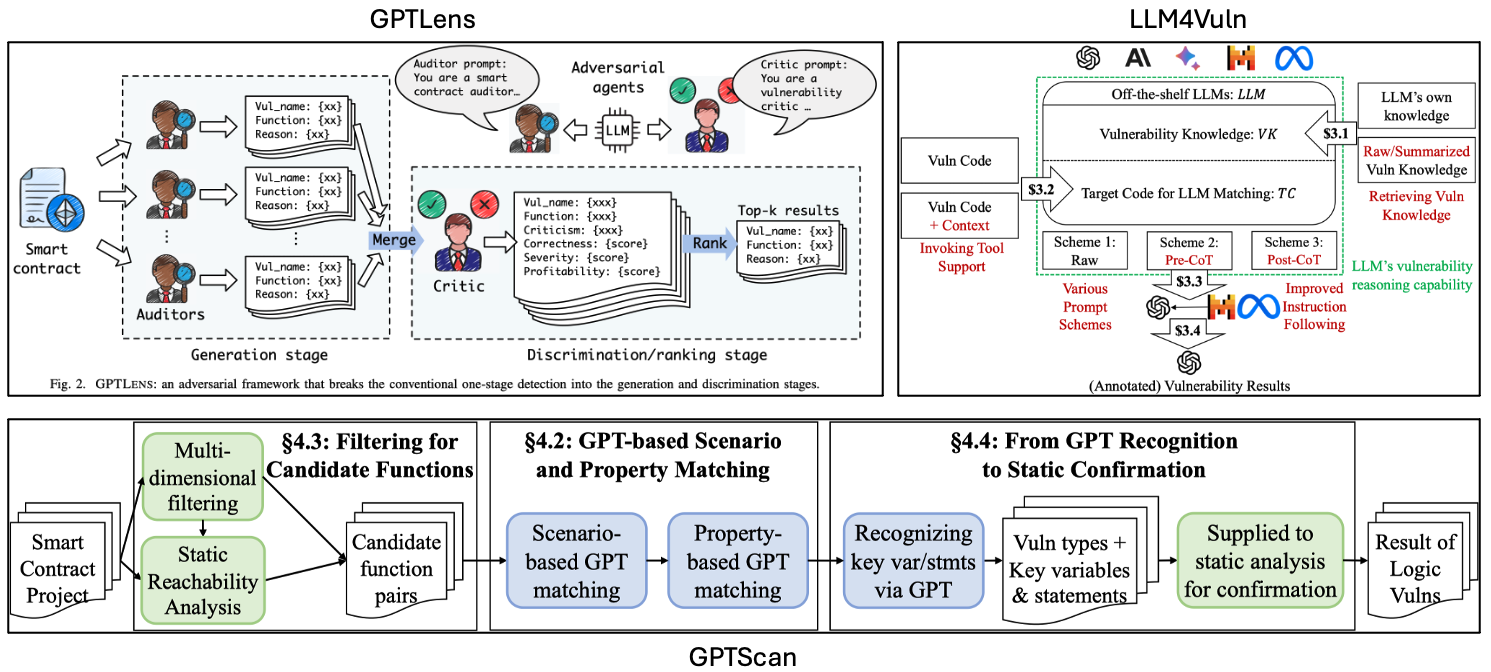
GPTScan [4] is a tool combining GPT with static analysis for smart contract logic vulnerability detection. Firstly, the authors break down ten common logic vulnerability types into scenarios and properties. Then GPTScan invokes GPT to match candidate functions with these scenarios and properties. Lastly, static analysis is used to validate the detection results of GPT.
GPTLens [8] breaks the common one-stage detection for smart contract vulnerabilities into two stages: generation and discrimination. For generation, GPTLens uses one or more GPT-4 auditor agents to generate multiple auditing reports for source code of previous vulnerabilities. For discrimination, GPTLens use one GPT-4 critic agent to select effective auditing reports from the generation stage. However, the authors only evaluate their approach against 13 CVEs in 2018 and 2019, which may have been potentially covered by the training data of GPT-4, making the result less persuadable.
LLM4Vuln [10] proposes an evaluation framework, which separates LLMs’ vulnerability reasoning from other capabilities (knowledge retrieval, tool invocation, prompt schemes, and instruction following) and evaluates how LLMs’ vulnerability reasoning could be enhanced when combined with the enhancement of other capabilities. Experiments on smart contract vulnerabilities confirm the effectivenss of LLM4Vuln, which also identifies 9 zero-day vulnerabilities in two bug bounty programs.
VulBench [13] proposes a comprehensive vulnerability benchmark dataset composed of CTF challenges and real-world vulnerabilities, which also conducts an extensive evaluation of LLMs in vulnerability detection.
David et al. [11] focuses on the optimization of prompt engineering for enhanced security analysis, which is evaluated with smart contract vulnerabilities. The evaluation results show that GPT-4 and Claude achieve a hit rate of 40%, as well as demonstrating a high false positive rate.
Chen et al. [12] evaluates ChatGPT’s effectiveness in smart contract vulnerability detection and discusses the root causes for the false positives generated by ChatGPT.
Zhou et al. [7] explores how LLMs (GPT-3.5 and GPT-4) perform on vulnerability detection with various prompts.
Zhang et al. [9] launches a study on the performance of Java and C/C++ software vulnerability detection using ChatGPT with different prompt designs.
Similar to Zhang et al. [9], Khare et al. [14] evaluates the effectiveness of GPT-4 and GPT-3.5 on Java and C/C++ vulnerability datasets, showing promising results.
Chan et al. [16] from Microsoft presents a practical system that leverages deep learning (code-davinci-002, text-davinci-003 and CodeBERT) on a large-scale data set (Javascript, Python, Go, Java, C/C++, C# and Ruby) of vulnerable code patterns to learn complex manifestation of more than 250 vulnerability types and detect vulnerable code patterns at EditTime.
Update 1: Security'23 Poster
Poster: Step-by-Step Vulnerability Detection using Large Language Models

Topic 2: LLM-assisted Fuzzing
Besides direct vulnerability detection using LLM, researchers try to integrate LLM into mainstream vulnerability detection approaches, including program analysis and fuzzing. Leveraging LLM’s comprehension capability of natural languages and code, the performance of traditional approaches could be effectively improved.
In this section, we introduce studies on LLM-assisted fuzzing.
ChatAFL [1] is a LLM-guided protocol implementation fuzzing engine, which constructs grammars for each message type in a protocol, and then mutates messages or predicts the next messages in a message sequence via interactions with LLMs. The evaluation results show that ChatAFL outperforms SOTA fuzzers (AFLNet and NSFuzz) with more state transitions, states and code.
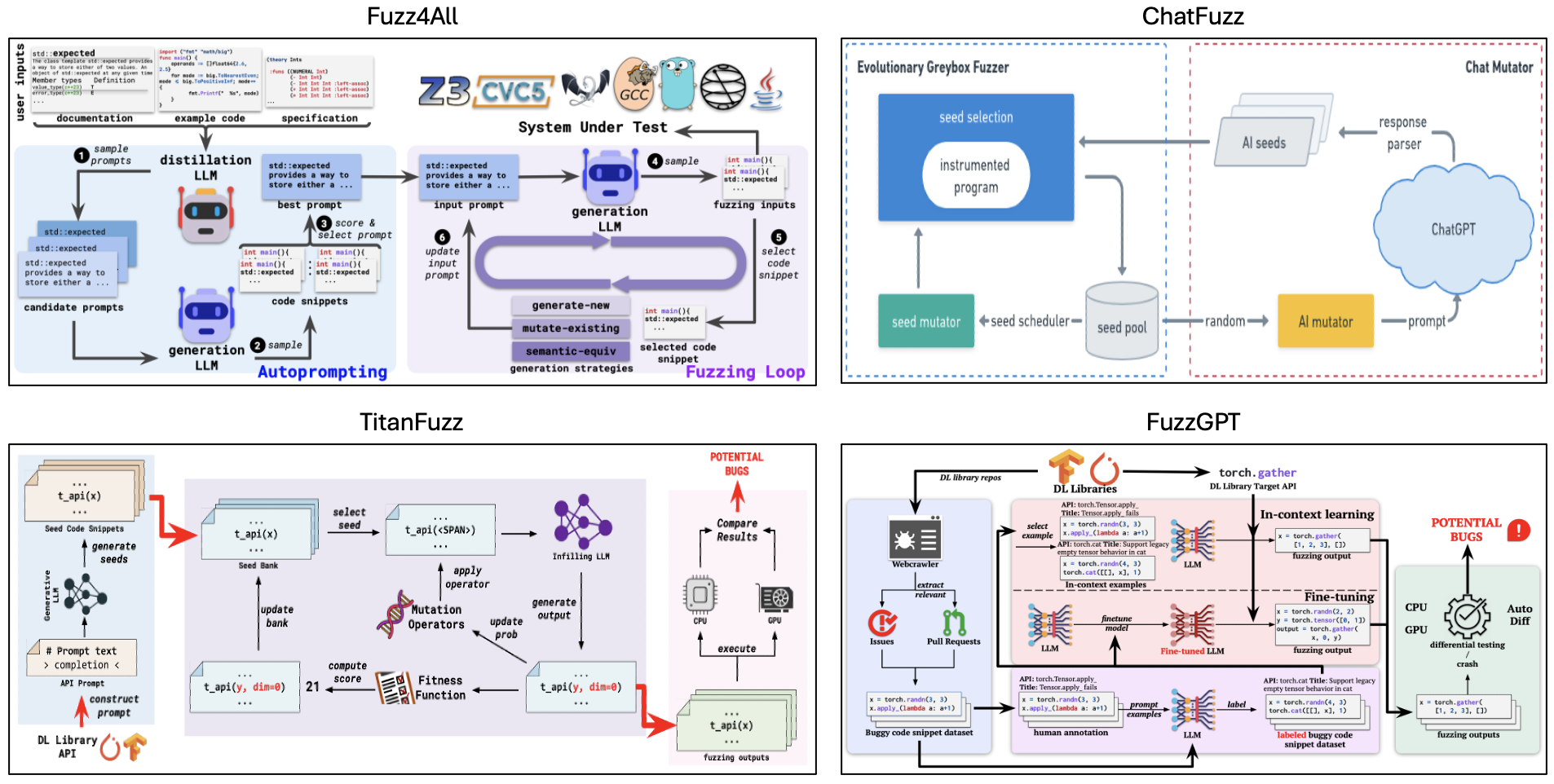
Fuzz4All [2] is the first fuzzer that targets many different input languages and many different features of these languages. The key idea behind Fuzz4All is to leverage LLMs as an input generation and mutation engine. The evaluation shows, across all six languages, this approach achieves higher coverage than existing language-specific fuzzers.
ChatFuzz [18] is a LLM-assisted greybox fuzzer, which mutates seeds by prompting ChatGPT. The experiment results show that this approach improves the edge coverage by 12.77% over the SOTA greybox fuzer (AFL++).
TitanFuzz [5] is the first approach to directly leveraging LLMs to generate input programs for fuzzing deep learning (DL) libraries. The key insight is that modern LLMs can also include numerous code snippets invoking DL library APIs in training corpora, and thus can implicitly learn both language syntax/semantics and intricate DL API constraints for valid DL program generation.
FuzzGPT [3] is the first technique to prime LLMs to synthesize unusual programs for fuzzing deep learning (DL) libraries. The key insight is that historical bug-triggering programs may include rare/valuable code ingredients important for bug finding.
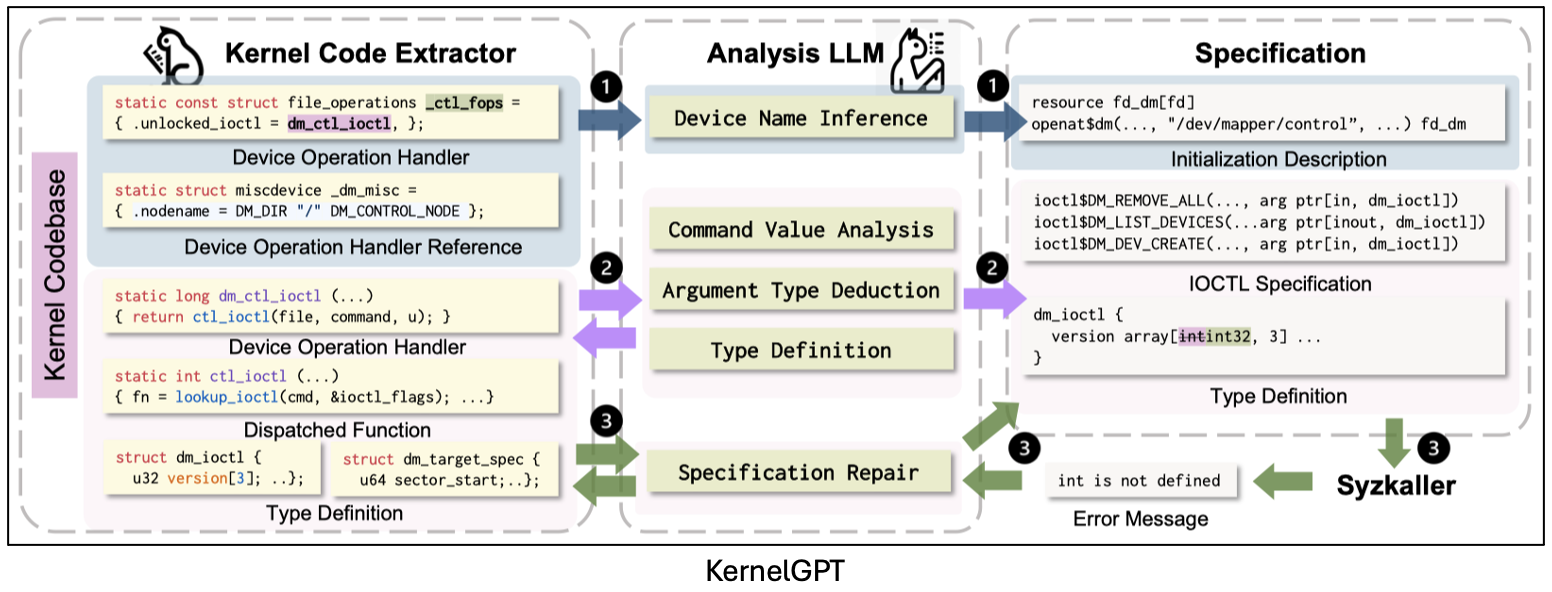
KernelGPT [15] is the first approach to automatically inferring Syzkaller specifications via LLMs for enhanced kernel fuzzing. The insight is that LLMs have seen massive kernel code, documentation, and use cases during pre-training, and thus can automatically distill the necessary information for making valid syscalls. The evaluation results demonstrate that KernelGPT can help Syzkaller achieve higher coverage and find unknown bugs.
Topic 3: LLM-assisted Program Analysis
In our collected papers, only two studies concentrate on LLM-assisted program analysis.
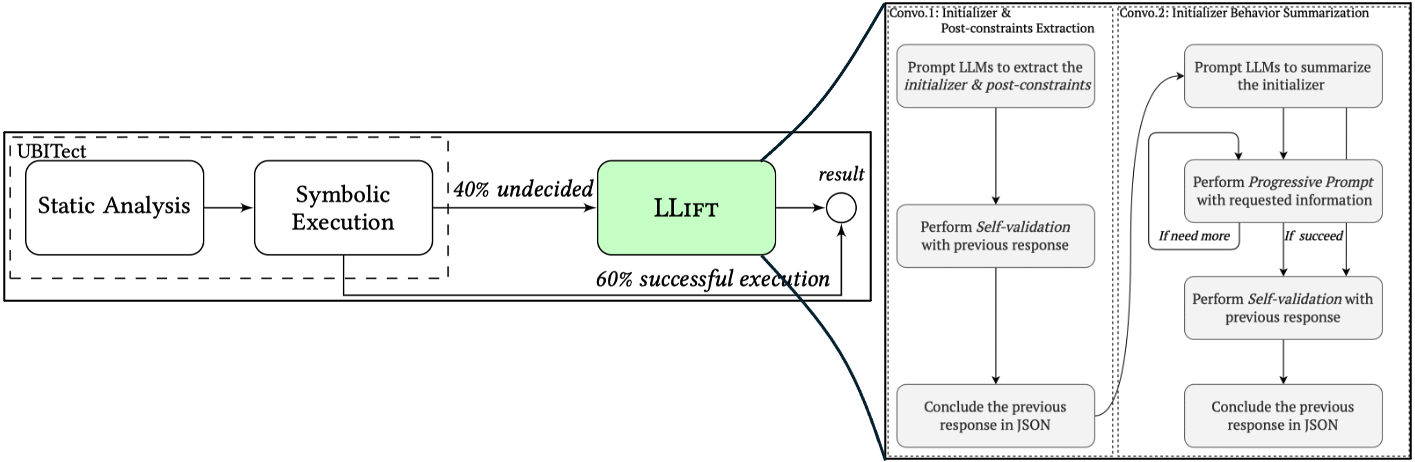
LLift [6] is a fully automated framework that interfaces with both a static analysis tool and an LLM, which tries to overcome a number of challenges, including bug-specific modeling, the large problem scope, the non-deterministic nature of LLMs, etc. Tested in a real-world scenario analyzing nearly a thousand potential use-before-initialization (UBI) bugs produced by static analysis, LLift showcases a precision of 50% and appears to have no missing bug, as well as identifying 13 previously unknown UBI bugs in the Linux kernel.
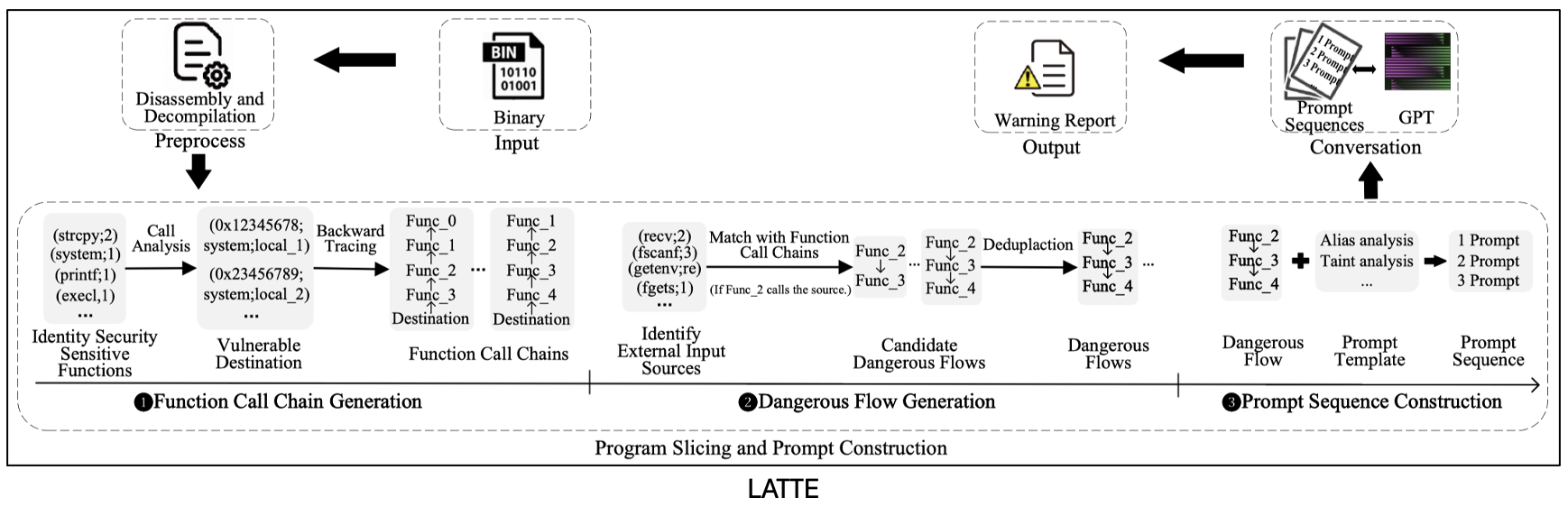
LATTE [17] is the first static binary taint analysis powered by LLM (GPT-4) that superior to SOTA approaches in three aspects. First, LATTE is fully automated while SOTA approaches (Emtaint, Arbiter and Karonte) rely on human expertise to manually customize taint propagation rules and vulnerability inspection rules. Second, LATTE outperforms SOTA approaches on vulnerability detection tasks. Third, LATTE incurs low engineering cost.
References
NDSS'24
- [ChatAFL] Meng, Ruijie, et al. “Large language model guided protocol fuzzing.” Proceedings of the 31st Annual Network and Distributed System Security Symposium (NDSS). 2024.
ICSE'24
-
[Fuzz4All] Xia, Chunqiu Steven, et al. “Fuzz4all: Universal fuzzing with large language models.” Proc. IEEE/ACM ICSE (2024).
-
[FuzzGPT] Deng, Yinlin, et al. “Large language models are edge-case generators: Crafting unusual programs for fuzzing deep learning libraries.” Proceedings of the 46th IEEE/ACM International Conference on Software Engineering. 2024.
-
[GPTScan] Sun, Yuqiang, et al. “When gpt meets program analysis: Towards intelligent detection of smart contract logic vulnerabilities in gptscan.” arXiv preprint arXiv:2308.03314 (2023).
ISSTA'23
- [TitanFuzz] Deng, Yinlin, et al. “Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models.” Proceedings of the 32nd ACM SIGSOFT international symposium on software testing and analysis. 2023.
OOPSLA'24
- [LLift] Li, Haonan, et al. “The Hitchhiker’s Guide to Program Analysis: A Journey with Large Language Models.” arXiv preprint arXiv:2308.00245 (2023).
ICSE-NIER'24
- Zhou, Xin, Ting Zhang, and David Lo. “Large Language Model for Vulnerability Detection: Emerging Results and Future Directions.” arXiv preprint arXiv:2401.15468 (2024).
TPS-ISA'23
- [GPTLens] Hu, Sihao, et al. “Large language model-powered smart contract vulnerability detection: New perspectives.” arXiv preprint arXiv:2310.01152 (2023).
arXiv
- Zhang, Chenyuan, et al. “Prompt-enhanced software vulnerability detection using chatgpt.” arXiv preprint arXiv:2308.12697 (2023).
- [LLM4Vuln] Sun, Yuqiang, et al. “LLM4Vuln: A Unified Evaluation Framework for Decoupling and Enhancing LLMs’ Vulnerability Reasoning.” arXiv preprint arXiv:2401.16185 (2024).
- David, Isaac, et al. “Do you still need a manual smart contract audit?.” arXiv preprint arXiv:2306.12338 (2023).
- Chen, Chong, et al. “When chatgpt meets smart contract vulnerability detection: How far are we?.” arXiv preprint arXiv:2309.05520 (2023).
- [VulBench] Gao, Zeyu, et al. “How Far Have We Gone in Vulnerability Detection Using Large Language Models.” arXiv preprint arXiv:2311.12420 (2023).
- Khare, Avishree, et al. “Understanding the Effectiveness of Large Language Models in Detecting Security Vulnerabilities.” arXiv preprint arXiv:2311.16169 (2023).
- [KernelGPT] Yang, Chenyuan, Zijie Zhao, and Lingming Zhang. “KernelGPT: Enhanced Kernel Fuzzing via Large Language Models.” arXiv preprint arXiv:2401.00563 (2023).
- Chan, Aaron, et al. “Transformer-based vulnerability detection in code at EditTime: Zero-shot, few-shot, or fine-tuning?.” arXiv preprint arXiv:2306.01754 (2023).
- [LATTE] Liu, Puzhuo, et al. “Harnessing the power of llm to support binary taint analysis.” arXiv preprint arXiv:2310.08275 (2023).
- [ChatFuzz] Hu, Jie, Qian Zhang, and Heng Yin. “Augmenting greybox fuzzing with generative ai.” arXiv preprint arXiv:2306.06782 (2023).