Preface
Now I am continuing to learning Docker from the book Docker Pro by Huawei’s Docker group.
So Docker is a combination of varieties of old techniques, such as cgroup(2006), namespace and aufs(1993).
Architecture

Libcontainer is the actual docker engine. It uses clone() to create container, pivot_root to enter container and cgroupfs to manage resources.
Docker components:
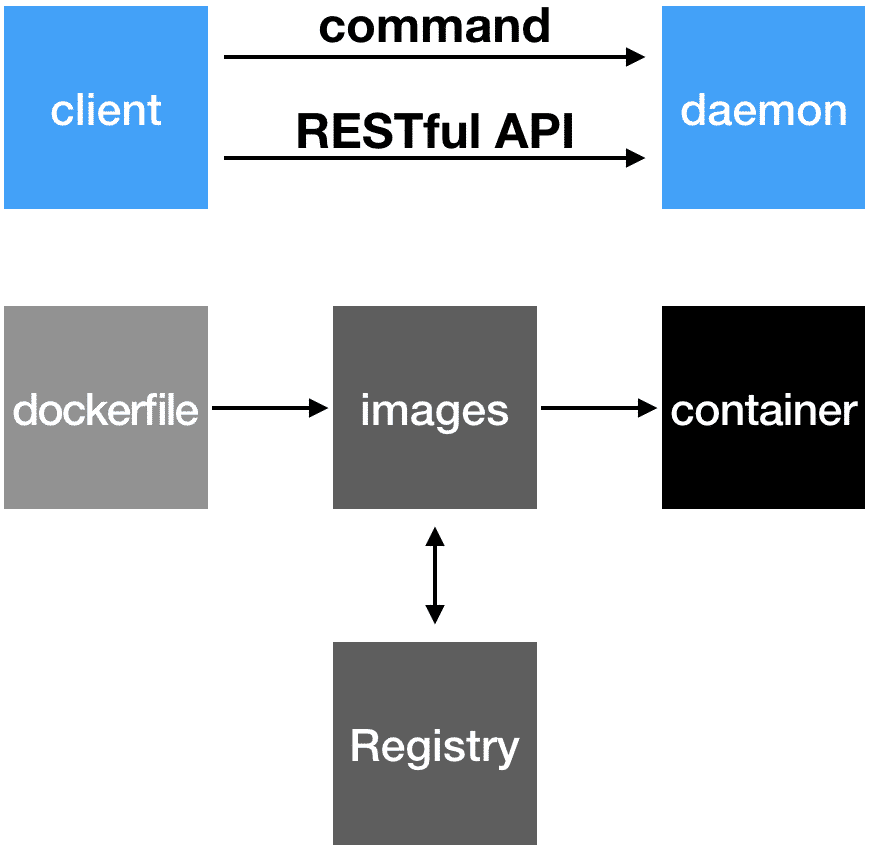
Container shares the same kernel with OS of host.
Construction of Container
container = cgroup + namespace + rootfs + engine
How can we construct a container? Let’s learn about the process step by step.
Firstly, create a new process, which has its own namespace, with the help of clone:
pid = clone(fun, stack, flags, clone_arg);
/*
flags: CLONE_NEWPID | CLONE_NEWNS | CLONE_NEWIPC | CLONE_NEWUTS | ...
*/
Second, insert PID of the process we created before into cgroup system, so it can be manipulated by cgroup:
echo $pid > /sys/fs/cgroup/cpu/tasks
echo $pid > /sys/fs/cgroup/cpuset/tasks
echo $pid > /sys/fs/cgroup/blkio/tasks
echo $pid > /sys/fs/cgroup/mempry/tasks
echo $pid > /sys/fs/cgroup/device/tasks
echo $pid > /sys/fs/cgroup/freezer/tasks
Third, let the process run func, which will invoke pivot_root to make itself into a new rootfs:
func()
{
// ...
pivot_root("path_of_rootfs/", path);
// ...
exec("/bin/bash");
}
Sure, func will give us a shell finally. Now let’s dive into details.
Cgroup
Cgroup is QoS of resources, including CPU, memory, block I/O and bandwidth. It consists of different sub-systems:
- devices
- cpuset
- cpu,cpuacct
- blkio (block I/O)
- freezer
- memory
- net_cls, net_prio
- huge_tlb
- perf_event
- …
Like procfs or sysfs, cgroup is a virtual filesystem and must be mounted before you use it, though that has been done when Linux starts.
E.g. mount a sub-system
mount -t cgroup -o cpuset cpuset /sys/fs/cgroup/cpuset
E.g. files of cpuset sub-system
> ls
cgroup.clone_children cpuset.memory_pressure
cgroup.procs cpuset.memory_pressure_enabled
cgroup.sane_behavior cpuset.memory_spread_page
cpuset.cpu_exclusive cpuset.memory_spread_slab
cpuset.cpus cpuset.mems
cpuset.effective_cpus cpuset.sched_load_balance
cpuset.effective_mems cpuset.sched_relax_domain_level
cpuset.mem_exclusive notify_on_release
cpuset.mem_hardwall release_agent
cpuset.memory_migrate tasks
tasks records all the process controlled by it.
E.g. create a cgroup
mkdir /sys/fs/cgroup/cpuset/child
E.g. configure cgroup
echo 0 > /sys/fs/cgroup/cpuset/child/cpuset.cpus
echo 0 > /sys/fs/cgroup/cpuset/child/cpuset.mems
Then all the processes controlled by this cgroup can only run on No.0 CPU and allocate memory from No.0 memory.
E.g. add process to cgroup
echo $$ > /sys/fs/cgroup/cpuset/child/tasks
All the sub-processes will be automatically added to this cgroup.
Namespace
Namespace ensures that different namespaces can use the same resource simultaneously without troubles. There are 6 namespaces:
- IPC (isolates System V IPC and POSIX message queue)
- Network
- Mount
- PID
- UTS (isolates hostname and domain)
- User (isolates userid and groupid)
We can configure namespace with APIs clone, setns and unshare:
#include <sched.h>
// clone, __clone2 - create a child process
// new process into new namespace
int clone(int (*fn)(void *), void *child_stack,
int flags, void *arg, ...
/* pid_t *ptid, void *newtls, pid_t *ctid */ );
// unshare - disassociate parts of the process execution context
// existing process into new namespace
int unshare(int flags);
// setns - reassociate thread with a namespace
// existing process into existing namespace
int setns(int fd, int nstype);
But how can a process specify a namespace? It can open a virtual file of another process’s procfs and deliver this file-descriptor to setns:
ls -l /proc/$$/ns
total 0
lrwxrwxrwx 1 root root 0 Nov 16 21:49 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 root root 0 Nov 16 21:49 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx 1 root root 0 Nov 16 21:49 mnt -> 'mnt:[4026531840]'
lrwxrwxrwx 1 root root 0 Nov 16 21:49 net -> 'net:[4026531992]'
lrwxrwxrwx 1 root root 0 Nov 16 21:49 pid -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 Nov 16 21:49 pid_for_children -> 'pid:[4026531836]'
lrwxrwxrwx 1 root root 0 Nov 16 21:49 user -> 'user:[4026531837]'
lrwxrwxrwx 1 root root 0 Nov 16 21:49 uts -> 'uts:[4026531838]'
[exec] command in docker is based on setns
Let’s dirty our hand and have a try!
UTS
#include <sys/utsname.h>
#include <sched.h>
#include <stdio.h>
#define STACK_SIZE (1024 * 1024)
static char stack[STACK_SIZE];
static char *const child_args[] = {"/bin/bash", NULL};
static int child(void *arg)
{
execv("/bin/bash", child_args);
return 0;
}
int main(int argc, char **argv)
{
pid_t pid;
pid = clone(child, stack + STACK_SIZE, SIGCHLD | CLONE_NEWUTS, NULL);
waitpid(pid, NULL, 0);
return 0;
}
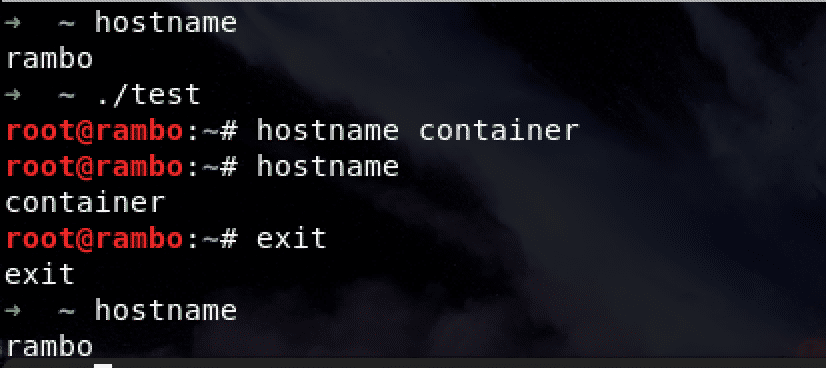
IPC
We can change the macro CLONE_NEWUTS to CLONE_NEWIPC and test it:
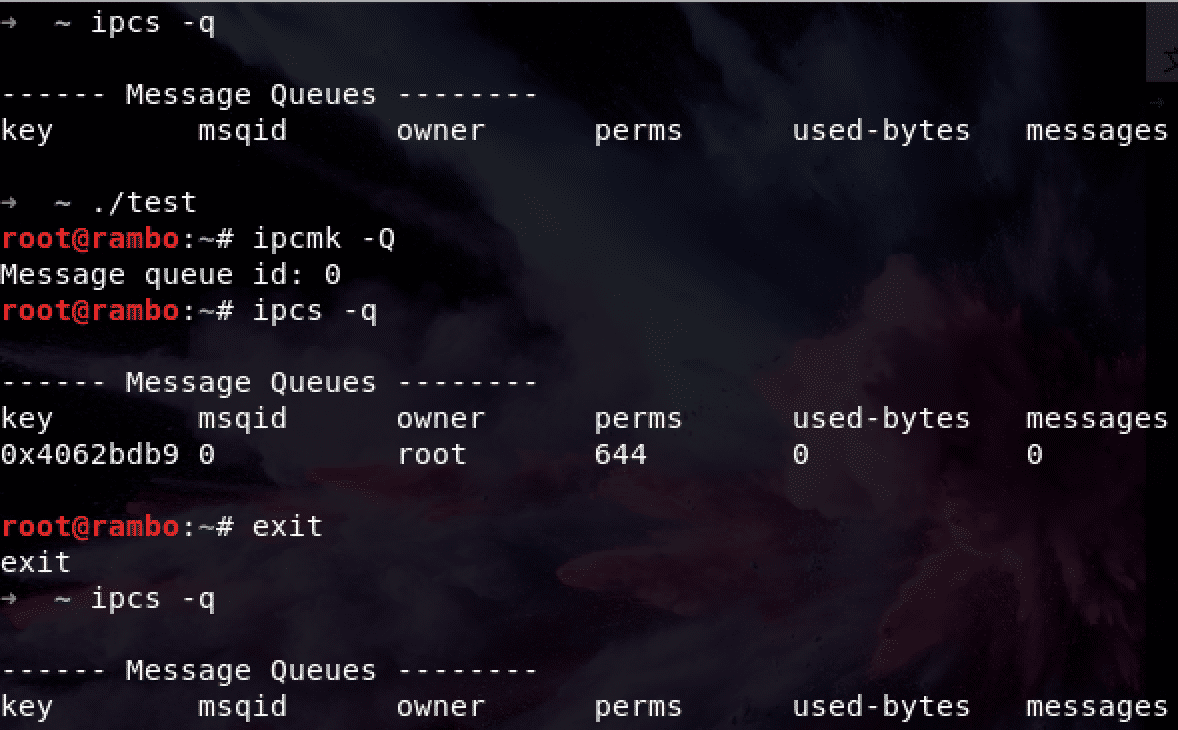
Network
CLONE_NEWNET
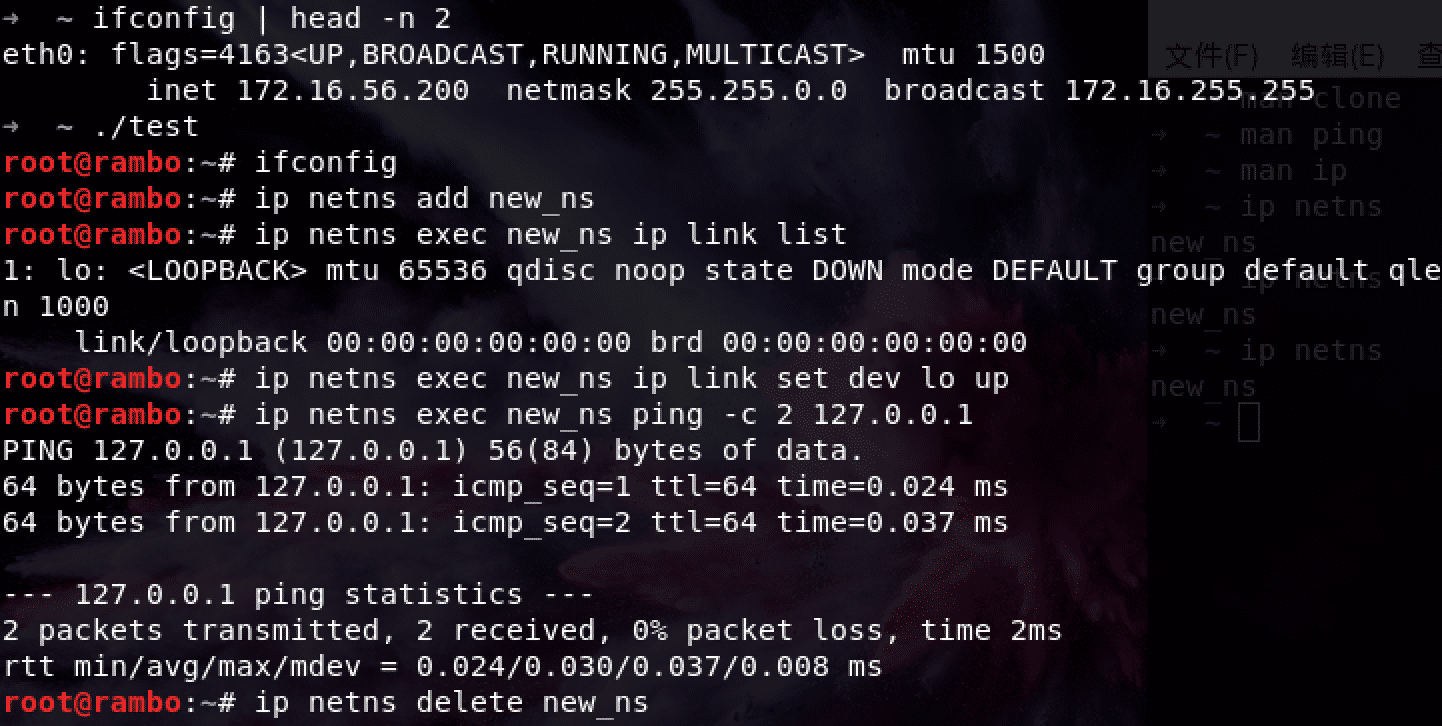
PID
CLONE_NEWPID
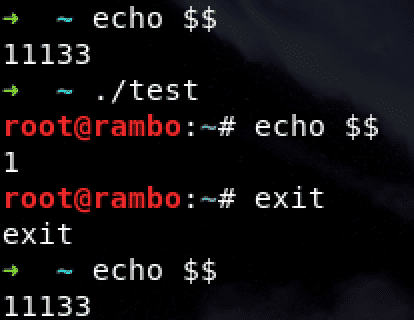
User
CLONE_NEWUSER

That’s good. But why is it 65534? Can we change it to 0, just as what we see in a docker container? We can use /proc/PID/uid_map to realise it. Referring to Docker基础技术:Linux Namespace(下), we should modify the code.
// ... some headers
#define STACK_SIZE (1024 * 1024)
static char container_stack[STACK_SIZE];
char* const container_args[] = {
"/bin/bash",
NULL
};
int pipefd[2];
void set_map(char* file, int inside_id, int outside_id, int len) {
FILE* mapfd = fopen(file, "w");
if (NULL == mapfd) {
perror("open file error");
return;
}
fprintf(mapfd, "%d %d %d", inside_id, outside_id, len);
fclose(mapfd);
}
void set_uid_map(pid_t pid, int inside_id, int outside_id, int len) {
char file[256];
sprintf(file, "/proc/%d/uid_map", pid);
set_map(file, inside_id, outside_id, len);
}
void set_gid_map(pid_t pid, int inside_id, int outside_id, int len) {
char file[256];
sprintf(file, "/proc/%d/gid_map", pid);
set_map(file, inside_id, outside_id, len);
}
int container_main(void* arg)
{
printf("Container [%5d] - inside the container!\n", getpid());
printf("Container: eUID = %ld; eGID = %ld, UID=%ld, GID=%ld\n",
(long) geteuid(), (long) getegid(), (long) getuid(), (long) getgid());
/* wait for parent-process */
char ch;
close(pipefd[1]);
read(pipefd[0], &ch, 1);
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
int main()
{
const int gid=getgid(), uid=getuid();
printf("Parent: eUID = %ld; eGID = %ld, UID=%ld, GID=%ld\n",
(long) geteuid(), (long) getegid(), (long) getuid(), (long) getgid());
pipe(pipefd);
printf("Parent [%5d] - start a container!\n", getpid());
int container_pid = clone(container_main, container_stack+STACK_SIZE,
CLONE_NEWUSER | SIGCHLD, NULL);
printf("Parent [%5d] - Container [%5d]!\n", getpid(), container_pid);
set_uid_map(container_pid, 0, uid, 1);
set_gid_map(container_pid, 0, gid, 1);
printf("Parent [%5d] - user/group mapping done!\n", getpid());
/* inform sub-process */
close(pipefd[1]);
waitpid(container_pid, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
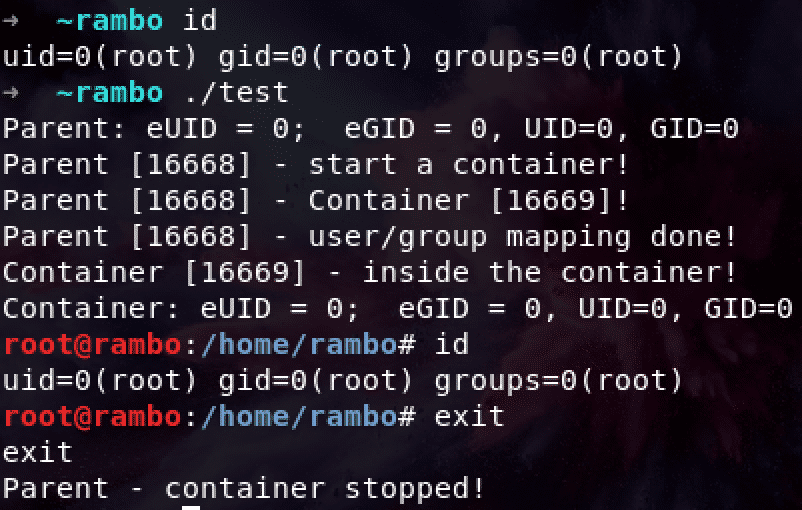
If you combine all the things together, you will get something really similar to a docker container!