1. 前言
近期做项目时,我了解了syzkaller1和syzbot2这两个Linux内核安全领域的明星项目;另外,master阶段的最后一门课程恰巧也有Fuzzing的内容和作业。因此,我打算通过写一篇实践笔记来记录自己的探索过程。本文分为上下两篇(转到下篇),主要内容是对《The Fuzzing Book》在线教程3(后文简称TFB)初级内容的学习实践总结(覆盖章节如图1所示),也会引用一些其他资料。
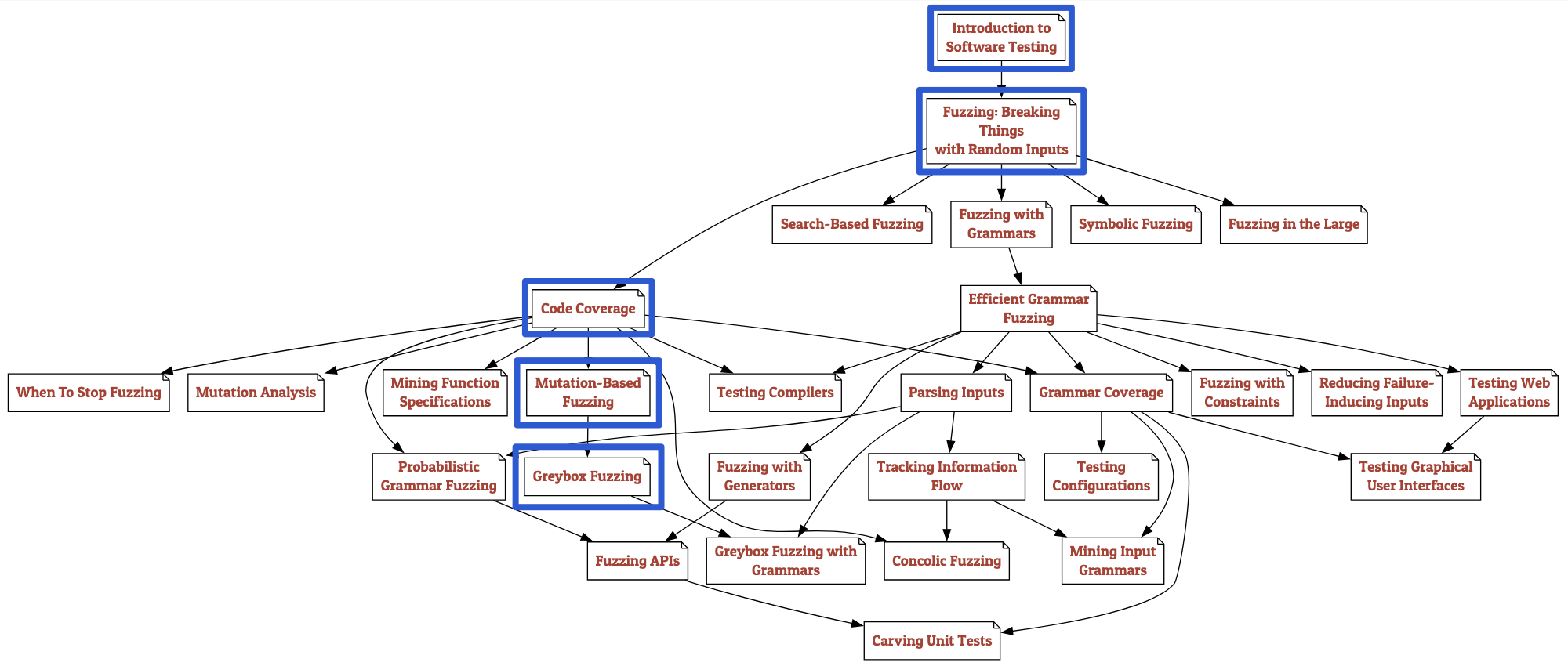 图1 - TFB学习路线及本笔记覆盖内容
图1 - TFB学习路线及本笔记覆盖内容
根据维基百科4,“Fuzz”这个词是由Barton Miller教授于1988年秋在威斯康星大学“高级操作系统”课程的一个课程项目中提出,该项目希望通过自动化生成随机输入来测试Unix命令行工具的稳定性。不过,在此之前,模糊测试的的思路和尝试却早已有之。简而言之,Fuzzing通过自动或半自动生成随机数据并输入到目标程序中,监视程序异常(如崩溃、断言失败等),从而发现bug,甚至是安全漏洞。
经过多年发展,Fuzzing已经不再是简单的随机输入实验了。从系统性(systematization)和全面性的角度来说,我们可以说Fuzzing处于“随机输入”和“程序分析”两者之间。
根据对目标程序的了解程度,Fuzzing可以被分为三种类型:
- Whitebox Fuzzing:在有目标程序的完整源代码或二进制代码的情况下进行,利用程序的结构信息来生成测试用例。其特点是更容易发现隐藏和深层的漏洞,但需要对代码或二进制进行深入分析,因此通常更为耗时。
- Greybox Fuzzing:介于Whitebox和Blackbox之间,具有部分程序内部知识。它结合了Blackbox的速度和Whitebox的深度;通常使用轻量级的代码覆盖率信息来指导测试。
- Blackbox Fuzzing:无需知道程序内部信息,只对程序的输入和输出进行测试,不依赖源代码或二进制分析。它速度更快,但可能错过一些深层次的漏洞。
根据测试数据的产生方式,Fuzzing可以被分为两种类型:
- Generation-based Fuzzing:即从零开始,根据某种预定义的规范或模型生成测试数据。
- Mutation-based Fuzzing:从现有的合法输入数据开始,通过应用一系列随机或半随机变化来产生新的测试用例。
以上分类知识来自ChatGPT(GPT-4)。另外,也可以根据目标测试对象分类,如网络协议、文件格式处理程序、API等,不再赘述。
值得一提的是,近期Ruijie5等研究者(来自NUS的Abhik教授6团队)提出了LLM导向的协议Fuzzing——ChatAFL7,该工作已经被NDSS 2024接收。以LLM为代表的AI领域突破正在为经典安全研究领域注入更多活力。
2. 从Flanker博客学到的…
Flanker曾经写过两篇关于Fuzzing的非常精彩的文章89,我将其中的要点总结如下:
随着软件复杂度的爆炸式增加,随机生成测试数据已经远不能满足需求。一种主流方案是用动态符号执行(concolic execution)辅助Fuzzing,实现上可以采用KLEE10(一个有趣的例子是用KLEE解决迷宫问题11)、Z3 Solver12和LLVM13等技术,自动解析条件代码语句生成输入。此外,Flanker提到的模版流派的Peach项目14则已经停止维护。
后来,基于编译器插桩的coverage feedback driven Fuzzing开始受到关注,神器AFL15横空出世(如今已停止维护,社区维护的版本是AFL++16)。后继者有LLVM的libfuzzer17、内核领域的syzkaller等,统称为Coverage-based Greybox Fuzzing(CGF)。Abhik团队发表在CCS'16上的工作18将AFL通过马尔可夫链(Markov Chain)19理论化,并提出了AFLFast来改进AFL(能量调度算法和搜索策略),收效显著。Wen Xu等在CCS'17上的工作20进一步提高了AFL的性能。同一场会议上,Abhik团队也发了第一篇Directed Greybox Fuzzing(DGF)的文章21,提出AFLGo。后来,Abhik团队在TSE'19上又发布了AFLSmart22。与此同时,Fuzzing基础设施的开发也在进行。例如,Google相继发布了OSS-Fuzz23和ClusterFuzz24项目,微软则在2016年发布了Project Springfield服务25。
Flanker第二篇则介绍了Fuzzing相关的二进制重写(rewriting)技术和动态追踪(dynamic tracing)技术。细节不再展开。这两篇文章内容文笔俱佳,高屋建瓴又能随时深入浅出,文字充满哲思和人文情怀,十分推荐阅读。
3. TFB:软件测试入门
本节内容主要基于TFB相关章节26完成。注意,后文中如果用到TFG提供的模块,需要先import bookutils。
3.1 assert断言
假设我们基于牛顿法27实现了一个求平方根的函数my_sqrt:
def my_sqrt(x):
approx = None
guess = x / 2
while approx != guess:
approx = guess
guess = (approx + x / approx) / 2
return approx
# >>> my_sqrt(2) * my_sqrt(2)
# 1.9999999999999996
在Python等编程语言中,我们可以在程序中加入assert断言,判断执行至此某个条件是否真,为假则终止程序并抛出异常。这是一种基础的测试方法。让我们基于assert来为小数比较大小设计一个函数assertEquals:
def assertEquals(x, y, epsilon=1e-8): assert abs(x - y) < epsilon
3.2 Timer与timeout
TFB提供了Timer模块来帮助我们记录测试的运行时间:
from Timer import Timer
with Timer() as t:
for i in range(10000):
x = 1 + random.random() * 1000000
assertEquals(my_sqrt(x) * my_sqrt(x), x)
print(t.elapsed_time())
# 0.18018318619579077
我们通常不希望目标程序运行很久,甚至是死循环。对此,可以引入timeout机制,例如:
from ExpectError import ExpectTimeout
def sqrt_program(arg: str) -> None: # type: ignore
x = int(arg)
print('The root of', x, 'is', my_sqrt(x))
with ExpectTimeout(1): sqrt_program("-1")
# Traceback (most recent call last):
# ...
# raise TimeoutError()
# TimeoutError (expected)
4. TFB:Fuzzing入门实践
本节内容主要基于TFB相关章节28完成。
4.1 随机字符串测试
最简单的Fuzzing是随机生成数据,输入到目标程序中,观察是否导致异常结果。这个过程的核心是随机数据的生成。下面是一个简单的随机字符串生成器:
def fuzzer(max_length: int = 100, char_start: int = 32, char_range: int = 32) -> str:
string_length = random.randrange(0, max_length + 1)
out = ""
for i in range(0, string_length):
out += chr(random.randrange(char_start, char_start + char_range))
return out
# >>> fuzzer(50, ord('A'), 26)
# 'FPRBKYKNRRVHHIZKAGSARFQFUUCEZJREMIGWBQMJGKCB'
有时为了生成测试文件,我们可以将随机数据保存到临时文件中(借助tempfile模块);如果要测试外部程序,可以使用subprocess模块。将这些串联起来,我们可以得到一个简单的自动化Fuzzing流程(与神经网络的训练过程有相似性):
trials = 100
program = "bc"
runs = []
for i in range(trials):
data = fuzzer()
with open(FILE, "w") as f: f.write(data)
result = subprocess.run([program, FILE],
stdin=subprocess.DEVNULL,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
universal_newlines=True)
runs.append((data, result))
4.2 报告异常
我们可以用Python模拟缓冲区溢出等经典bug,例如:
def crash_if_too_long(s):
buffer = "Thursday"
if len(s) > len(buffer): raise ValueError
TFB提供的ExpectError模块可以报告异常但同时确保流程继续执行:
from ExpectError import ExpectError
trials = 100
with ExpectError():
for i in range(trials):
s = fuzzer()
crash_if_too_long(s)
# Traceback (most recent call last):
# File "/tmp/ipykernel_41/292568387.py", line 5, in <module>
# crash_if_too_long(s)
# File "/tmp/ipykernel_41/2784561514.py", line 4, in crash_if_too_long
# raise ValueError
# ValueError (expected)
4.3 检测与识别错误
Sanitizers是检测内存访问错误的利器。Linux内核中有包含KASAN29在内的一众sanitizers。用户态也有类似的工具,如LLVM AddressSanitizer30。我们可以采用如下方式启用该sanitizer:
clang -fsanitize=address -g -o program program.c
如此一来,program程序执行过程中的越界内存访问操作将被报告。在C语言编译的二进制程序的Fuzzing中,sanitizers是很好的错误发生指示器。还有一类内存问题是“未初始化”导致的内存信息泄露,一种检测思路是判断输出数据中是否有预设的标记。总体而言,在Fuzzing时,我们应该开启尽可能多的sanitizers。
除了sanitizers,程序开发时编写的assert断言和静态代码检查工具也能够用来(如MyPy31)检测错误。
4.4 Fuzzing基础架构
本小节介绍的Fuzzing架构会在后面用到。整体而言,该架构包含两个类:Runner类,作为表示被测程序的基类;Fuzzer类,作为各种fuzzer的基类。
Runner类负责用给定输入运行被测程序,作为基类,它的实现非常简单:
class Runner:
# Test outcomes
PASS = "PASS"
FAIL = "FAIL"
UNRESOLVED = "UNRESOLVED"
def __init__(self) -> None: pass
def run(self, inp: str) -> Any: return (inp, Runner.UNRESOLVED)
我们将在它的子类中实现不同场景下具体的执行逻辑。例如,可以在run方法中添加一个打印语句实现PrintRunner。下面是一个用给定输入执行外部程序的ProgramRunner:
class ProgramRunner(Runner):
def __init__(self, program: Union[str, List[str]]) -> None:
self.program = program
def run_process(self, inp: str = "") -> subprocess.CompletedProcess:
return subprocess.run(self.program,
input=inp,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
universal_newlines=True)
def run(self, inp: str = "") -> Tuple[subprocess.CompletedProcess, Outcome]:
result = self.run_process(inp)
if result.returncode == 0: outcome = self.PASS
elif result.returncode < 0: outcome = self.FAIL
else: outcome = self.UNRESOLVED
return (result, outcome)
如果输入数据是非可见ASCII,可以将inp替换为inp.encode()。
Fuzzer类负责生成测试数据(fuzz方法)及启动Runner进行测试(run和runs方法):
class Fuzzer:
def __init__(self) -> None: pass
def fuzz(self) -> str: return ""
def run(self, runner: Runner = Runner()) \
-> Tuple[subprocess.CompletedProcess, Outcome]:
return runner.run(self.fuzz())
def runs(self, runner: Runner = PrintRunner(), trials: int = 10) \
-> List[Tuple[subprocess.CompletedProcess, Outcome]]:
return [self.run(runner) for i in range(trials)]
我们可以在前面介绍的fuzzer函数基础上实现一个RandomFuzzer:
class RandomFuzzer(Fuzzer):
def __init__(self, min_length: int = 10, max_length: int = 100,
char_start: int = 32, char_range: int = 32) -> None:
self.min_length = min_length
self.max_length = max_length
self.char_start = char_start
self.char_range = char_range
def fuzz(self) -> str:
string_length = random.randrange(self.min_length, self.max_length + 1)
out = ""
for i in range(0, string_length):
out += chr(random.randrange(self.char_start,
self.char_start + self.char_range))
return out
5. TFB:Code Coverage
本节内容主要基于TFB相关章节32完成。
5.1 Python中的Coverage统计
如Flanker博客文章所言,code coverage对于现代Fuzzing来说至关重要。Blackbox testing中,由于不能获得源码(implementation)信息,测试用例主要来自规范(specification),所谓coverage也主要是针对规范而言;Whitebox testing中,常用的code coverage有statement coverage和branch coverage,后者粒度更粗。Whitebox testing需要对被测程序进行插桩(instrumentation),这在不同的编程语言环境下有不同的实现方式。例如,Python允许我们通过sys.settrace(f)33的方式插桩——函数f将在每一行执行时被调用,它能够访问当前函数的上下文信息。本节以cgi_decode函数34为例,介绍coverage相关知识。
首先编写一个实际的函数f:
def traceit(frame, event, arg):
if event == 'line':
global coverage
function_name = frame.f_code.co_name
lineno = frame.f_lineno
coverage.append(lineno)
return traceit
接着编写并执行一个用来追踪cgi_decode函数调用过程的函数:
coverage = []
def cgi_decode_traced(s: str) -> None:
global coverage
coverage = []
sys.settrace(traceit) # Turn on
cgi_decode(s)
sys.settrace(None) # Turn off
cgi_decode_trace("a+b")
执行后,coverage列表将记录cgi_decode(s)执行过程中涉及到的所有行(statement)。我们可以使用inspect.getsource(cgi_decode)获得cgi_decode函数的源代码字符串,然后结合coverage得到具体的执行代码。TFB实现了一个Coverage类35,方便我们统计coverage,使用方法如下(如果直接打印cov会得到带有行编号的函数源代码,其中执行到的行前面会有#标识):
with Coverage() as cov: function_to_be_traced()
c = cov.coverage() # Tuple[str, int]
cov.coverage()是一个集合,因此我们可以很方便地对不同的coverage做集合运算,从而进行coverage比较。
5.2 基础Fuzzing的Coverage
结合Fuzzer,我们可以为Fuzzing过程计算并保存coverage的变化过程,例如:
trials = 100
def population_coverage(population: List[str], function: Callable) \
-> Tuple[Set[Location], List[int]]:
cumulative_coverage: List[int] = []
all_coverage: Set[Location] = set()
for s in population:
with Coverage() as cov:
try: function(s)
except: pass
all_coverage |= cov.coverage()
cumulative_coverage.append(len(all_coverage))
return all_coverage, cumulative_coverage
def hundred_inputs() -> List[str]:
population = []
for i in range(trials): population.append(fuzzer())
return population
all_coverage, cumulative_coverage = \
population_coverage(hundred_inputs(), cgi_decode)
# all_coverage: {('cgi_decode', 9), ('cgi_decode', 12), ...}
# cumulative_coverage: [18, 19, 19, 19, ...]
如有需要,我们可以借助matploitlib模块作图分析输入次数与line coverage之间的关系。
5.3 外部程序的Coverage统计
对于C语言编写的程序来说,我们可以在编译时添加--coverage选项来进行编译器插桩,然后借助gcov获得coverage。gcov将生成.gcov格式的文件,记录了行的执行次数(-代表是不可执行行,#####代表执行次数为0)。下面是cgi_decode.c36的执行案例:
gcc --coverage -o cgi_decode cgi_decode.c
./cgi_decode 'my+email+is+rambo%40wohin.me'
gcov cgi_decode.c
# Lines executed:91.43% of 35
# Creating 'cgi_decode.c.gcov'
5.4 Branch Coverage
目前为止,TFB对branch coverage的模拟非常简单,以至于我一开始并不理解这和branch coverage有什么关系——以实现的branch_coverage函数为例,它仅仅是将cov.trace()列表中的相邻语句拼接起来返回:
def branch_coverage(trace):
coverage = set()
past_line = None
for line in trace:
if past_line is not None: coverage.add((past_line, line))
past_line = line
return coverage
# (('cgi_decode', 15), ('cgi_decode', 16)),
# (('cgi_decode', 16), ('cgi_decode', 17)),
# ...
ChatGPT进一步解答了我的疑问:通过记录并拼接连续执行的两条语句,我们可以得知程序的执行流程如何在各个语句间转移。在一个包含分支结构(如if-else、switch-case)的程序中,根据不同的输入或状态,代码可能会走不同的分支。因此,跟踪连续执行的语句可以帮助我们了解哪些分支被执行了,哪些没有。
然而,从“语句执行对”到branch coverage本身还有不止一步之遥。简单来说,我们还需要分析源代码确定所有分支,确定分支出口点(包括分支内的第一条语句和分支结尾后的第一条语句),再结合“语句执行对”数据确定哪些分支在trace中被执行了及执行顺序。