前言
第五、六节课是关于数据流分析理论的知识,比较抽象难懂,但是能够帮助我们更好地理解之前学习过的数据流分析应用,也能够为未来更加复杂的数据流分析应用奠定基础。
事实上,在听完第五节课后,我并没有立即写笔记。一方面是想让潜意识消化一下知识,另一方面吧,是因为之前读过的一篇论文的阅读笔记还欠着,哈哈。所以我先写了那篇论文的笔记,然后才轮到这篇。有意思的是,写笔记时再看到论文中的“backward data flow analysis”时,我终于能够理解这个词的意思——毕竟之前在南大课程中学过的“存活变量分析”也是一种backward data flow analyais。好!继续学习吧。
再看迭代求解算法
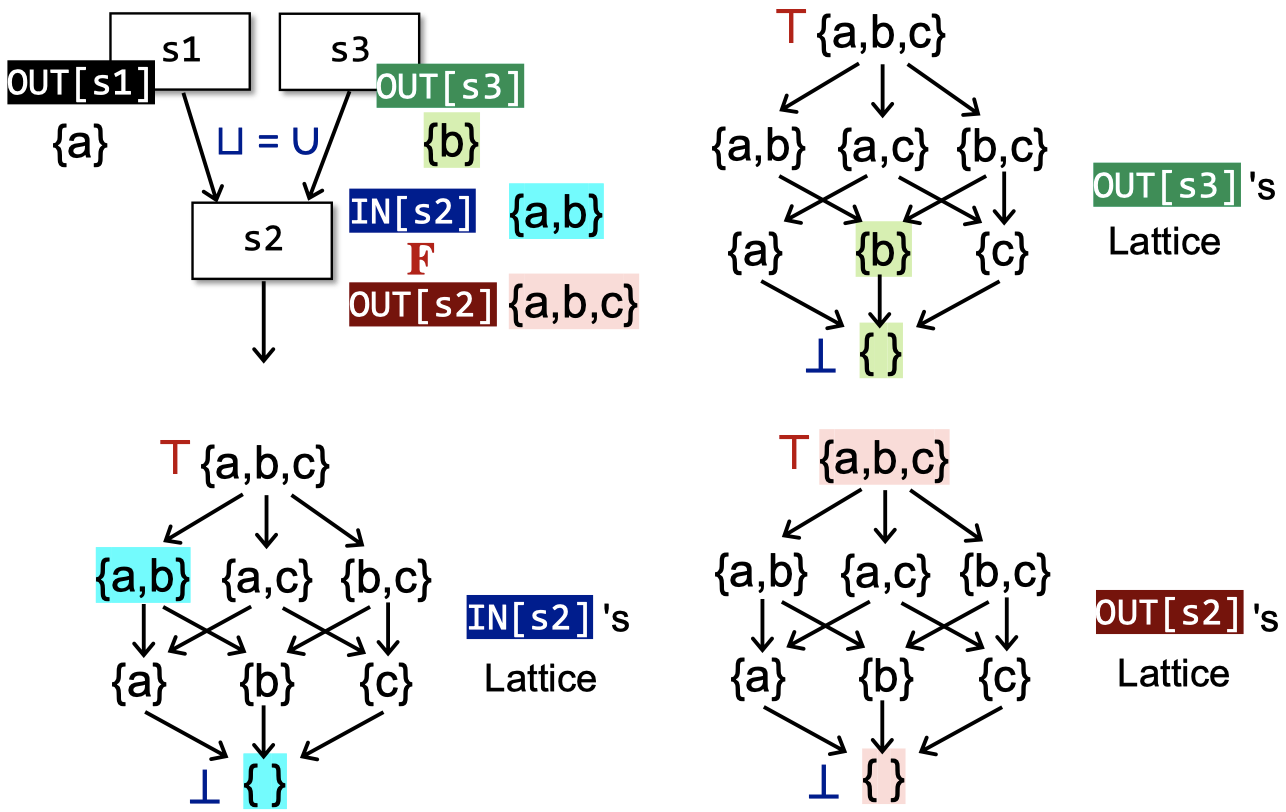
以may&forward analysis为例:

下面从另一种视角来看这个算法:
给定一个有$k$个节点的CFG,迭代算法在每轮迭代中更新每个节点$n$的$OUT[n]$。假设该数据流分析中的值域为$V$,我们可以定义一个k-tuple来表示每次迭代分析后的结果:
$$ (OUT[n_{1}],\ OUT[n_{2}],\ …\ ,\ OUT[n_{k}]) $$
它是集合$(V_{1} \times V_{2}\ …\ \times V_{k})$中的一个元素,这个集合记做$V^{k}$。
每轮迭代可以视作从$V^{k}$中的一个元素到另一个新元素的映射,映射过程就是transfer functions和control-flow handling,我们将这个映射过程抽象为一个函数$F: V^{k} \rightarrow V^{k}$。
在上述抽象的基础上,may&forward analysis算法可以视作不断输出一系列的k-tuple,直到某个k-tuple与上一个k-tuple相同:
$$ iter\ i:\ (v_{1}^{i}, v_{2}^{i},\ …\ , v_{k}^{i}) = X_{i} = F(X_{i-1}) $$
$$ iter\ i+1:\ (v_{1}^{i+1}, v_{2}^{i+1},\ …\ , v_{k}^{i+1}) = X_{i+1} = F(X_{i}) $$
在这时,我们可以得到以下关系:
$$ X_{i} = X_{i+1} = F(X_{i}) $$
我们称满足$X = F(X)$的$X$是一个不动点(fixed point),并称上述迭代算法到达了一个不动点。
对于这样一种算法,我们提出三个问题:
- 这个算法能够保证一定能终止(到达不动点/有解)吗?
- 如果上一个问题的答案是肯定的,那么只有一个解/不动点吗?如果有多个不动点,哪一个是最好的、或者说最精确的?
- 什么时候这个算法能够到达不动点呢?
对于第一个问题,我们曾在《南大软件分析课程笔记|03 数据流分析应用》中简单回答过。这节课和下节课的知识将从数学的角度回答这些问题。本节课我们不会直接回答这些问题,而是先补充一些数学知识。
偏序(Partial Order)
首先是“偏序”的概念。我们将偏序集poset定义为$(P, \preccurlyeq)$,其中符号$\preccurlyeq$在集合$P$上定义了一个名为“偏序”的二元关系,该关系有以下特性:
$$ \forall\ x \in P, x \preccurlyeq x\ \ \text{(Reflexivity)} $$
$$ \forall\ x,y \in P, x \preccurlyeq y \wedge y \preccurlyeq x \Longrightarrow x = y \ \ \text{(Antisymmetry)} $$
$$ \forall\ x,y,z \in P, x \preccurlyeq y \wedge y \preccurlyeq z \Longrightarrow x \preccurlyeq z \ \ \text{(Transitivity)} $$
下面是一些poset的例子:
- 若$S$表示一个由整数组成的集合,$\preccurlyeq$表示“小于或等于”,那么$(S, \preccurlyeq)$就是一个poset。
- $S$表示一个由英文单词组成的集合,$\preccurlyeq$表示子串关系。
- $S$表示$\lbrace a, b, c \rbrace$的幂集(power set),$\preccurlyeq$表示子集关系。
第三个集合的例子可以表示如下,后面我们会多次使用这种图形:
其实,关于“偏序关系”的理解,个人认为知乎上的一个回答讲得不错:
- 集合的包含关系是一种偏序。
- 在整数集中定义偏序:若a能整除b,我们就记为a≺b。
显然它满足序公理。但整数集中,不是任何两个数都存在整除关系,这个关系是局部的(partial),太“偏颇”,于是被称为偏序。
所谓“偏序”,有可能是翻译的问题(未求证)。Partial还有“局部的”之义——如果取这个意思,那就容易理解多了。或者说,偏序集中的元素是部分可比较的,不一定是所有元素都可以互相比较。
上界和下界(Upper/Lower Bounds)
了解完偏序的概念,接下来是在偏序集上定义的上界和下界的概念。
给定一个偏序集$(P, \preccurlyeq)$和它的子集$S$($S \subseteq P$),我们说$u \in P$是$S$的一个上界,当且仅当$\forall\ x \in S,\ x \preccurlyeq u$;类似地,$l \in P$是$S$的一个下界,当且仅当$\forall\ x \in S,\ l \preccurlyeq x$。
若$S$是由下图中绿色部分组成的集合,那么$\lbrace a, b, c \rbrace$就是$S$的上界,$\lbrace\ \rbrace$是$S$的下界:
在此基础上,我们定义最小上界(叫做lub或join),记为$\lfloor \rfloor S$,对于$S$的每一个上界$u$,有$\lfloor \rfloor S \preccurlyeq u$;类似地,定义最大下界(叫做glb或meet),记为$\lceil \rceil S$,对于$S$的每一个下界$l$,有$l \preccurlyeq \lceil \rceil S$。
还是以集合为例,若$S$是由下图中绿色部分组成的集合,则$\lbrace a, b, c \rbrace$和$\lbrace a, b \rbrace$都是它的上界,后者还是最小上界;$\lbrace\ \rbrace$则是$S$的唯一下界,因此也是最大下界:
若$S$只包含两个元素$a$和$b$,我们也可以将$\lfloor \rfloor S$写为$a \lfloor \rfloor b$,将$\lceil \rceil S$写为$a \lceil \rceil b$。
下面是关于上下界的两个特性:
- 不是所有的poset都有lub或glb。
- 如果一个poset有lub或glb,它一定是唯一的。这一点可以借助偏序关系的antisymmetry特点证明。
Lattice, Semilattice, Complete and Product Lattice
终于到格(lattice)的概念了!先说两句题外话:我发现写作时中英混用确实是比较舒服的,有的东西用中文表达会更加简洁清晰,有的东西用英文表达则会比较好,因为对应的中文翻译不一定能完全表达原词的意思。毕竟是写博客,比较自由,我也就不拘束于特定的表达了。
首先看一下格的定义:给定一个偏序集$(P, \preccurlyeq)$,$\forall\ a,b \in P$,如果$a \lfloor \rfloor b$和$a \lceil \rceil b$均存在,那么$(P, \preccurlyeq)$称为格。换句话说,一个偏序集是格,当且仅当其所有“元素对”构成的子集的最小上界和最大下界都存在。
接下来是半格(semilattice),它放宽了格的概念:如果$a \lfloor \rfloor b$存在,该偏序集就是一个join semilattice;如果$a \lceil \rceil b$存在,它就是一个meet semilattice。不必同时满足两个约束。
完全格(complete lattice)则在格的定义上加强了约束:对于给定偏序集$(P, \preccurlyeq)$,它的任意子集$S$的最小上界和最大下界都存在,则$(P, \preccurlyeq)$才能被称为完全格。幂集就是一种完全格。事实上,所有有限格(finite lattice,即$P$是有限集合)都是完全格。
每个完全格$(P, \preccurlyeq)$都有一个最大元素$\top = \lfloor \rfloor P$,称作top,一个最小元素$\bot = \lceil \rceil P$,称作bottom。
乘积格(Product Lattice)稍微复杂一些:给定一系列格$L_{1} = (P_{1}, \preccurlyeq_{1}), L_{2} = (P_{2}, \preccurlyeq_{2}),\ …\ , L_{n} = (P_{n}, \preccurlyeq_{n})$,如果对于所有$i$,$(P_{i}, \preccurlyeq_{i})$都有$\lfloor \rfloor _{i}$和$\lceil \rceil _{i}$,那么我们可以定义一个乘积格$L^{n} = (P, \preccurlyeq)$如下:
$$ P = P_{1} \times\ …\ \times P_{n} $$
$$ (x_{1},\ …\ , x_{n}) \preccurlyeq (y_{1},\ …\ , y_{n}) \Leftarrow \Rightarrow (x_{1} \preccurlyeq y_{1}) \wedge \ …\ \wedge (x_{n} \preccurlyeq y_{n}) $$
$$ (x_{1},\ …\ , x_{n})\ \lfloor \rfloor\ (y_{1},\ …\ , y_{n}) \Leftarrow \Rightarrow (x_{1} \lfloor \rfloor_{1} y_{1},\ …\ , x_{n} \lfloor \rfloor_{n} y_{n}) $$
$$ (x_{1},\ …\ , x_{n})\ \lceil \rceil\ (y_{1},\ …\ , y_{n}) \Leftarrow \Rightarrow (x_{1} \lceil \rceil_{1} y_{1},\ …\ , x_{n} \lceil \rceil_{n} y_{n}) $$
很容易证明,乘积格也是格,完全格构成的乘积格也是完全格。
基于格的数据流分析框架
现在,我们再次回到数据流分析上,定义一个基于格的数据流分析框架$(D, L, F)$:其中$D$指的是数据流的方向,包括前向和后向;$L$指的是由值域$V$和一个meet或join操作符构成的格;$F$指的是从$V$到$V$的一系列transfer functions。
实际上,数据流分析可以视作在格上不断迭代应用transfer functions和meet/join操作:
单调性(Monotonicity)和不动点(Fixed Point)定理
在本课的最后一部分,我们来学习单调性和不动点定理。老规矩,首先看一下定义吧:
单调性
函数$f: L \rightarrow L$($L$是格)是单调的,当且仅当$\forall\ x,y \in L$,$x \preccurlyeq y \Longrightarrow f(x) \preccurlyeq f(y)$。
不动点定理
给定一个完全格$(L, \preccurlyeq)$,如果$f: L \rightarrow L$是单调的且$L$是有限的,那么:
- $f$的最小不动点可以通过以下方式得到:不断迭代计算$f(\bot), f(f(\bot)),\ …\ , f^{k}(\bot))$,直到到达一个不动点。
- $f$的最大不动点可以通过类似的方式得到:不断迭代计算$f(\top), f(f(\top)),\ …\ , f^{k}(\top))$,直到到达一个不动点。
如何证明不动点定理呢?我们可以分两步走:首先证明不动点的存在,继而证明按照前述方式找到的不动点是最小不动点。最小和最大不动点的证明是类似的,我们来看一下最小不动点的证明过程。
1. 证明不动点的存在
前面我们提到,最小元素$\bot = \lceil \rceil L$是格上的最小元素,且$f$是单调的,因此我们可以得到:
$$ \bot \preccurlyeq f(\bot) \preccurlyeq f^{2}(\bot) \preccurlyeq\ …\ f^{H}(\bot) $$
而$L$又是有限的,假设其高度为$H$,则上述数列的上限就是$f^{H}(\bot)$。当$i>H$时,根据鸽笼原理,存在$k$和$j$使得$f^{k}(\bot) = f^{j}(\bot)$,假设$k < j \leq H + 1$。结合$f$是单调的,又有$f^{k}(\bot) \preccurlyeq\ …\ \preccurlyeq f^{j}(\bot)$,因此可得$f^{Fix} = f^{k}(\bot) =\ …\ = f^{j}(\bot)$。故不动点存在。
注:格的高度的概念出现在下一节,指的是在格上从top到bottom的最长路径。
2. 证明该不动点是最小不动点
这里我们使用归纳法证明:
- 假设还有一个不动点$x$,使得$x = f(x)$。由于$\bot$是最小元素,结合函数单调性,可得$f(\bot) \preccurlyeq f(x)$。
- 假设$f^{i}(\bot) \preccurlyeq f^{i}(x)$,那么结合函数单调性,我们有$f^{i+1}(\bot) \preccurlyeq f^{i+1}(x)$。
- 因此,我们得证$f^{i}(\bot) \preccurlyeq f^{i}(x)$。又因为$x$是不动点,故$f^{i}(\bot) \preccurlyeq f^{i}(x) = x$。
- 最终有$f^{Fix} = f^{k}(\bot) \preccurlyeq f^{k}(x) = x$,证毕。
总结与思考
本节课,我们学习了偏序、格、格上的函数单调性和不动点定理等重要知识。关于数据流分析的迭代算法,我们提出了三个问题,但是本节课并未直接回答这三个问题,因为我们尚未将数据流分析算法和不动点定理关联起来,这些将是下节课的内容。
学习之余,我还看了李樾老师在南大的一堂SICP课的后半节课的视频,主题是“大学除了专业知识,还应该学些什么?”。李樾老师讲得非常好,可以看出是一位拥有人文情怀的老师。
今天连续输出了两篇文章,另一篇ELOISE论文笔记算是填之前留下的坑,但是这些东西真的很有意思。好,那么就继续探索吧。