前言
梁振凯教授多次建议我们要跟踪、阅读自己研究领域相关的前沿论文,而且要写论文总结。在之前的云安全研究工作中,我也阅读过一些论文,确实能够从优秀论文中学到很多知识、方法和相关领域的研究进展。然而,一个问题是,我很少写阅读总结,那些读过但短期内没有在工作中用上的论文就逐渐淡忘了。
进入master第二学期,我希望能够从此养成并保持阅读论文、写总结的习惯。“总结”不单是对知识和方法的概括,还应包括对其想法、实现方法的点评。后两者可能更难,它依赖于在一个领域中持续深耕所形成的领域熟悉度和洞察力。
另外,关注Blackhat、Defcon等信息安全工业界顶会的同学可能会注意到,近几年许多研究成果是横跨工业、学术界的,我们经常能在同年或前一年的USENIX Security、CCS、NDSS和IEEE S&P等学术界顶会上见到相同研究成果的论文,这是一个有意思的现象。
关于如何阅读论文,网络上已经有很多相关文章甚至书籍了。这里推荐一些前辈的经验与方法论:
- 加州大学钱志云教授的《如何在计算机应用领域寻找研究想法?》
- 剑桥大学S. Keshav教授的《How to Read a Paper》
关键还是在于持之以恒,不断思索和实践,反馈、迭代和优化。只有写,才会写;只有读,才会读。
1. 论文基本信息
| Meta | Info |
|---|---|
| Title | AEM: Facilitating Cross-Version Exploitability Assessment of Linux Kernel Vulnerabilities |
| Author(s) | Zheyue Jiang, Yuan Zhang et al. |
| Institution(s) | Fudan University & University of Utah |
| Published in | 2023 IEEE Symposium on Security and Privacy (IEEE S&P) |
| Link | IEEE Computer Society |
2. 成果概述
漏洞的可利用性是评估其严重程度的标准之一。如今,针对可利用性的主流评估方法仍然是人工编写ExP并测试。然而,人工编写的ExP通常面向特定程序版本,人们无法确保这样的ExP在其他理论上可能受影响的版本上有效执行。
该论文希望回答这个问题:在拥有针对特定版本内核的某漏洞的有效ExP的情况下,如何评估该漏洞在其他内核版本上的可利用性?
论文研究了Linux内核漏洞跨版本利用的可行性评估问题,提出了名为Automated Exploit Migration(AEM,自动化漏洞利用迁移)的方法。在拥有针对特定版本内核的某漏洞的有效ExP的情况下,AEM能够自动修改该ExP,使之能够在其他同样受该漏洞影响的内核版本上完成漏洞利用。在67个有效测试用例中,AEM成功为56个测试用例实现了ExP迁移,成功率为83.5%。
注意,AEM的最终效果是确保迁移后的ExP能够在其他版本内核上实现漏洞利用原语,即控制流劫持或任意内存读写,不包括在实现漏洞利用原语之后的攻击步骤和载荷,如具体的ROP链等。但是,实现漏洞利用原语已经意味着该漏洞在目标内核上是可以被利用的。
与该论文主题相关的一个研究领域是Automatic Exploit Generation(AEG,自动化漏洞利用生成)。在拥有能够触发漏洞的PoC的情况下,AEG尝试通过扩展PoC来生成ExP。然而,当前的AEG技术通常会面临搜索空间过大带来的高复杂性等问题,不能很好地回答上述问题。
AEM则基于这样一个观察:针对某个特定版本内核开发的有效ExP所采用的利用策略通常也能够一般性地应用在其他受同一漏洞影响的内核版本上。因此,AEM并没有尝试像AEG一样在PoC的基础上从零构建一个ExP的其余部分,而是以原ExP在能够利用成功的内核版本上的执行流为参考,调整ExP,使之在其他版本内核上的执行流与在参考版本上一致(align),从而实现跨版本生成有效ExP。
3. ExP无法跨版本通用的原因
论文认为ExP跨版本利用失败的原因主要有两个:
- 代码变动。即使不是为了修复漏洞,不同版本的内核中某一区域的代码也可能发生变动。如果漏洞利用过程会涉及到这部分代码(不是漏洞点,只是涉及到),那么这些变动将可能会导致漏洞利用失败。
- 数据变动。同一数据结构在不同版本的内核中可能并不完全一样。例如,某一结构体中成员的变化可能会导致漏洞利用依赖的特定成员在结构体中的偏移发生改变,从而导致漏洞利用失败。
作者以CVE-2017-11176漏洞的ExP为例示范了上述两种原因。鉴于这两种原因比较直观,这里不再列出作者的例子。
4. 问题范围定义
作者强调AEM虽然擅长于跨版本漏洞利用可行性评估,但是并非银弹,并对应用范围进行了界定。
4.1 漏洞利用原语与漏洞利用策略
论文定义了“漏洞利用原语”和“漏洞利用策略”,前者指一种符合攻击者预期的提供了额外能力的程序状态(如控制流劫持),后者指从开始利用漏洞到获取“漏洞利用原语”的一般性过程。
4.2 可迁移与不可迁移的ExP
如果一个ExP的漏洞利用策略在某个目标内核版本上是可复现的,这个ExP对于该目标内核版本来说就是可迁移的。反之,如果目标内核版本与ExP最初适用的内核版本之间的某些实现差异(代码、数据变动)导致ExP的漏洞利用策略无法在目标内核版本上生效,那么这个ExP对于该目标内核版本来说就是不可迁移的。
AEM只关注可迁移的ExP。
4.3 前提假设
AEM依赖于一个在特定内核版本上针对指定漏洞能够实现有效利用的ExP,这样的ExP需要包含三个环节:触发漏洞、实现漏洞利用原语,执行后续攻击行为(如任意代码执行、绕过缓解机制等)。
在上述假设的基础上,该ExP需要能够在目标内核版本上触发漏洞(即至少实现PoC功能)。
AEM关注的范围是Linux内核的内存破坏问题,对于具体的漏洞类型(堆、栈溢出,UAF,逻辑漏洞等)则不做要求。
最常见的两类漏洞利用原语是控制流劫持和可控内存访问,AEM的目标是实现这两类漏洞利用原语的迁移,不包括在实现漏洞利用原语之后的攻击步骤和载荷,如具体的ROP链等。但是,实现漏洞利用原语已经意味着该漏洞在目标内核上是可以被利用的。
5. 实现方法
5.1 两大技术挑战
AEM的调整对象是ExP中的系统调用及其参数,面临两大挑战:
- 调整哪些系统调用?一个ExP可能涉及大量系统调用,一些富功能系统调用(如ioctl)的参数对应数据结构可能十分复杂,搜索空间过大,复杂度过高。
- 如何调整系统调用?内核漏洞利用依赖于精确的内存布局和代码执行上下文,盲目测试显然不可行。
论文认为,漏洞利用原语的实现是一系列内存操作的累加结果。为了克服这两个挑战,AEM以原ExP在能够利用成功的内核版本上的内存操作为参考,调整ExP,使之在目标版本内核上的内存操作与在参考版本上一致(align),从而实现跨版本生成有效ExP。其调整策略可以概括为“以原语为中心,以对齐为导向”。
对于第一个挑战来说,作者观察到并非ExP中使用的所有内存操作都对最终漏洞利用原语的实现有影响;另外,有些内核内存操作是无法受到用户空间影响的,从而无法在用户空间施加调整。因此,需要研究的是如何识别出这些内存操作并忽略它们。
对于第二个挑战来说,不同版本内核的实现差异决定了精确对齐(完全相同的地址和值)是不奏效的。应该根据执行上下文来进行两个内存操作的对齐——确保这两个内存操作在两个不同版本的内核中是相同的。论文采用了代码上下文(源代码定位)和数据上下文(访问的数据类型)两类执行上下文来实现内存操作对齐。
5.2 关键技术
构成AEM的两大关键技术分别是:
- 以原语为中心的内存抽象:在参考版本内核上收集ExP引发的内存操作,去除前文提到的漏洞利用原语无关的和无法在用户空间施加调整的内存操作,将剩下的内存操作构建成一个EXPGRAPH(漏洞利用图)结构。其中,每个结点代表一个具体的内存操作(及其上下文信息);每条边代表不同内存操作之间的依赖关系。
- 以对齐为导向的ExP调整:基于EXPGRAPH,在目标版本内核上重放ExP并再一次收集内存操作。遍历这些内存操作,根据上下文信息来识别那些已经与EXPGRAPH中拓扑排序后的结点对齐的操作,找到第一个未对齐的结点作为“迁移目标”,然后尝试调整ExP来实现对齐。具体来说,在目标版本内核上将ExP执行到EXPGRAPH中最后一个对齐的结点,然后从这里开始应用符号执行,直到一个新的内存操作对齐,或发现对齐无法完成。如果结果是前者,则不不断重复这个过程直到在目标版本内核上实现漏洞利用原语;如果结果是后者,则中止流程。
AEM的整个工作流分为两个阶段,如下图所示:
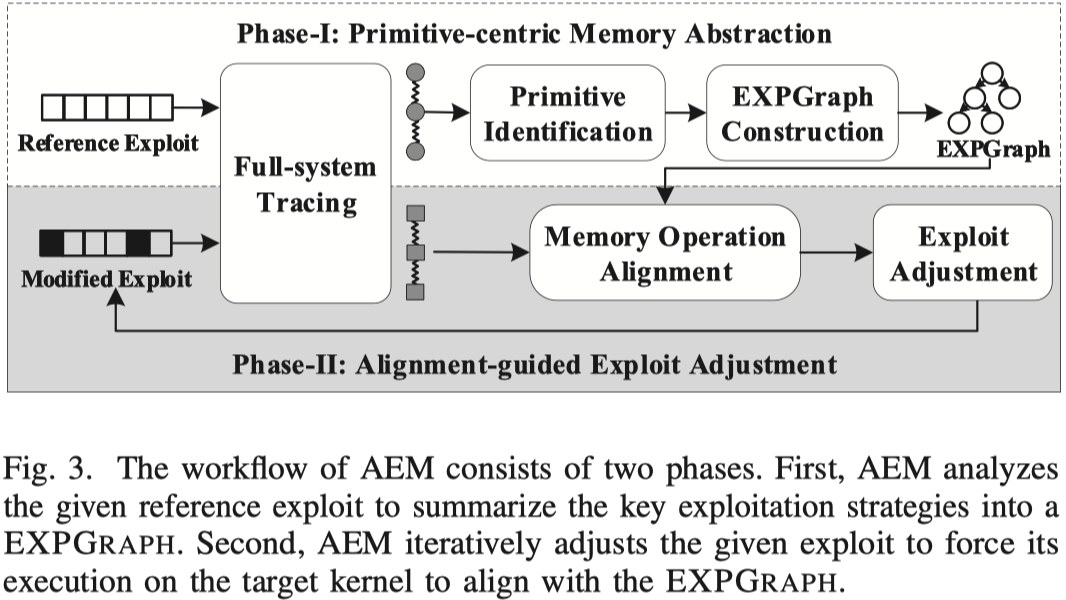
对于阶段1来说,“漏洞利用原语识别”过程对“控制流劫持”和“可控内存访问”两类原语进行识别。前者的特征是通常发生在间接控制流转移指令处;后者包括任意地址读(AAR)和任意地址写(AAW),特征是原始数据类型(来自源码中定义)和运行时数据类型的不一致。AEM基于这两类特征进行识别。
接下来,AEM从终止于漏洞利用原语的指令流中提取内存操作来生成EXPGRAPH。结点与结点之间的依赖关系可以分为数据依赖和地址依赖。在生成初始的EXPGRAPH后按照应对第一个挑战的思路进行剪枝。下面是一个最终的EXPGRAPH的示例:
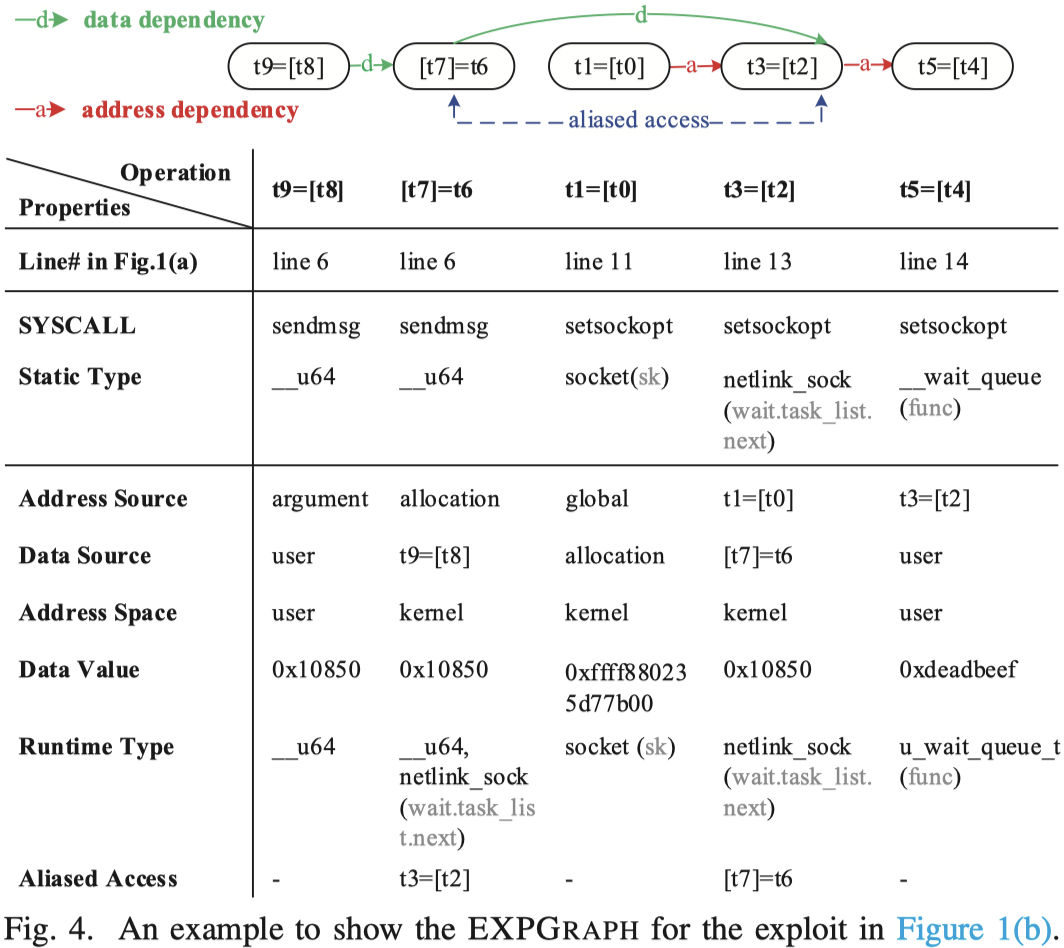
对于阶段2来说,核心点在于找到EXPGRAPH中拓扑排序后的首个未对齐的结点,从这里应用符号执行技术调整参数来使之对齐。
(Memory Operation Alignment)如何为EXPGRAPH中的结点寻找目标版本内核上已对齐的内存操作呢?论文的方案是从上一个已对齐的结点开始访问内存操作,判断当前操作是否满足四个约束条件:
- 内存操作和对应结点处于同一个系统调用中。
- 内存操作和对应结点拥有相同的访问类型(读或写)。
- 内存操作与对应结点的关联数据的静态类型和运行时类型一致。
- 内存操作与对应结点的地址来源和数据来源一致。
(Exploit Adjustment)对于无法在目标内核版本上找到对齐点的EXPGRAPH中的结点,AEM将分析对齐失败的原因,通常有两种:
- 内存操作在参考版本和目标版本中相同,但数据属性改变。
- 目标版本中未执行该内存操作。
如果仅仅是约束条件3中的运行时类型不一致,AEM将失败原因判定为原因1,否则判定为原因2。
原因1的调整方案分为两个阶段:首先反向递归找到影响目标版本上对应内存操作的系统调用及其参数;然后开展符号执行,将参考版本上的对应内存操作作为约束条件应用在目标版本上,进行约束求解,尝试使之对齐。
原因2的调整方案分为三个阶段:首先找到目标版本上与参考版本相似(关于如何定义相似的细节请参考原论文,其中源码相似度比对部分用到了编辑距离的概念)的对应内存操作;对所有候选内存操作,在目标版本上开展符号执行,尝试将ExP执行到该候选内存操作前的已对齐节点,在这个过程中修正相关系统调用及其参数;如果其中一条路径能够抵达候选内存操作,则停止符号执行。此时问题转化为原因1,继而按照原因1的调整方案执行。
最终,作者基于开源二进制分析平台Angr和开源符号执行平台S2E实现了AEM。
6. 效果评估
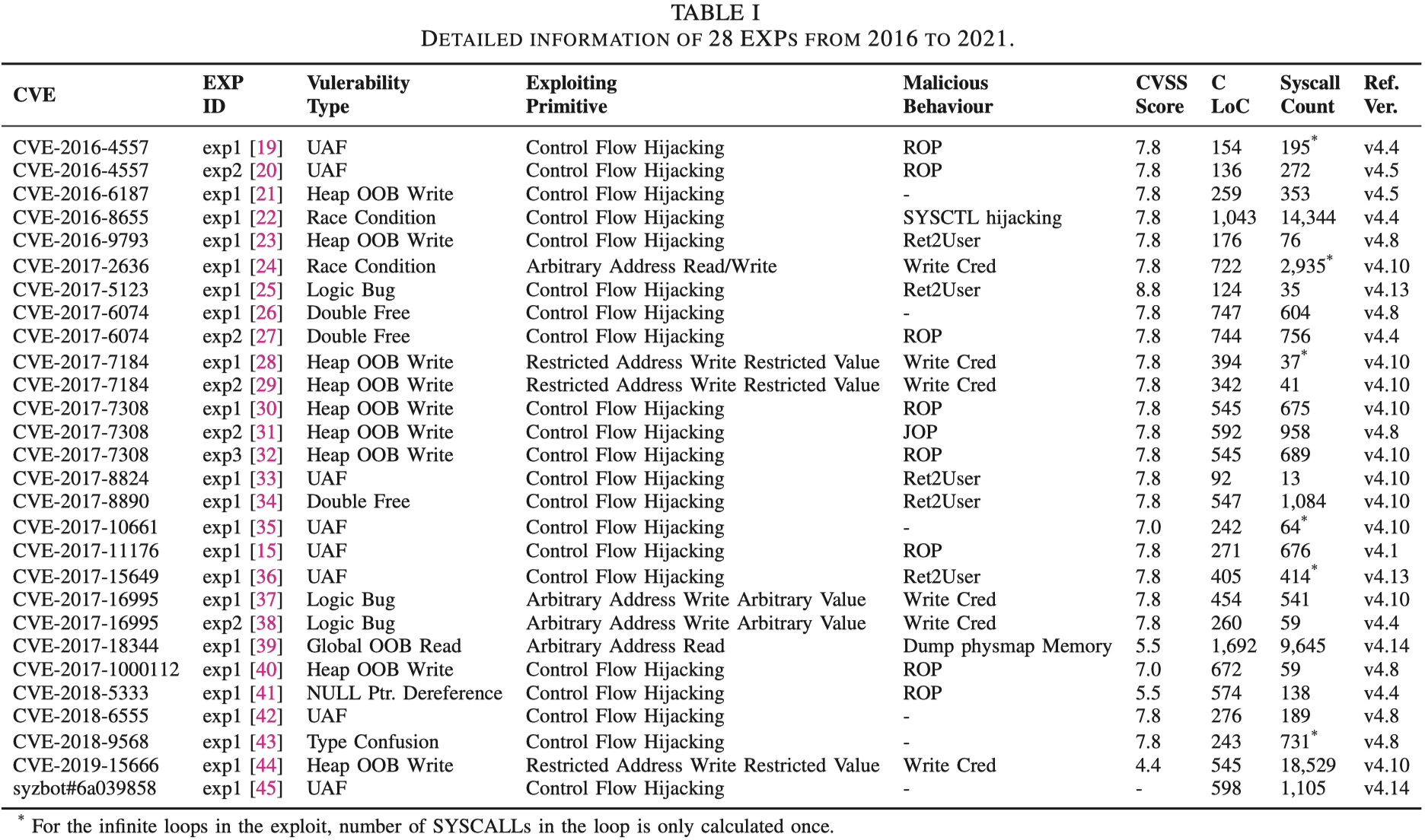
作者选取了2016年到2021年的22个内核漏洞与相对应的28个ExP,具体细节如下:
AEM有效性的最终测试结果如下表中下半部分所示(上半部分涉及的ExP无需迁移即可跨版本生效):
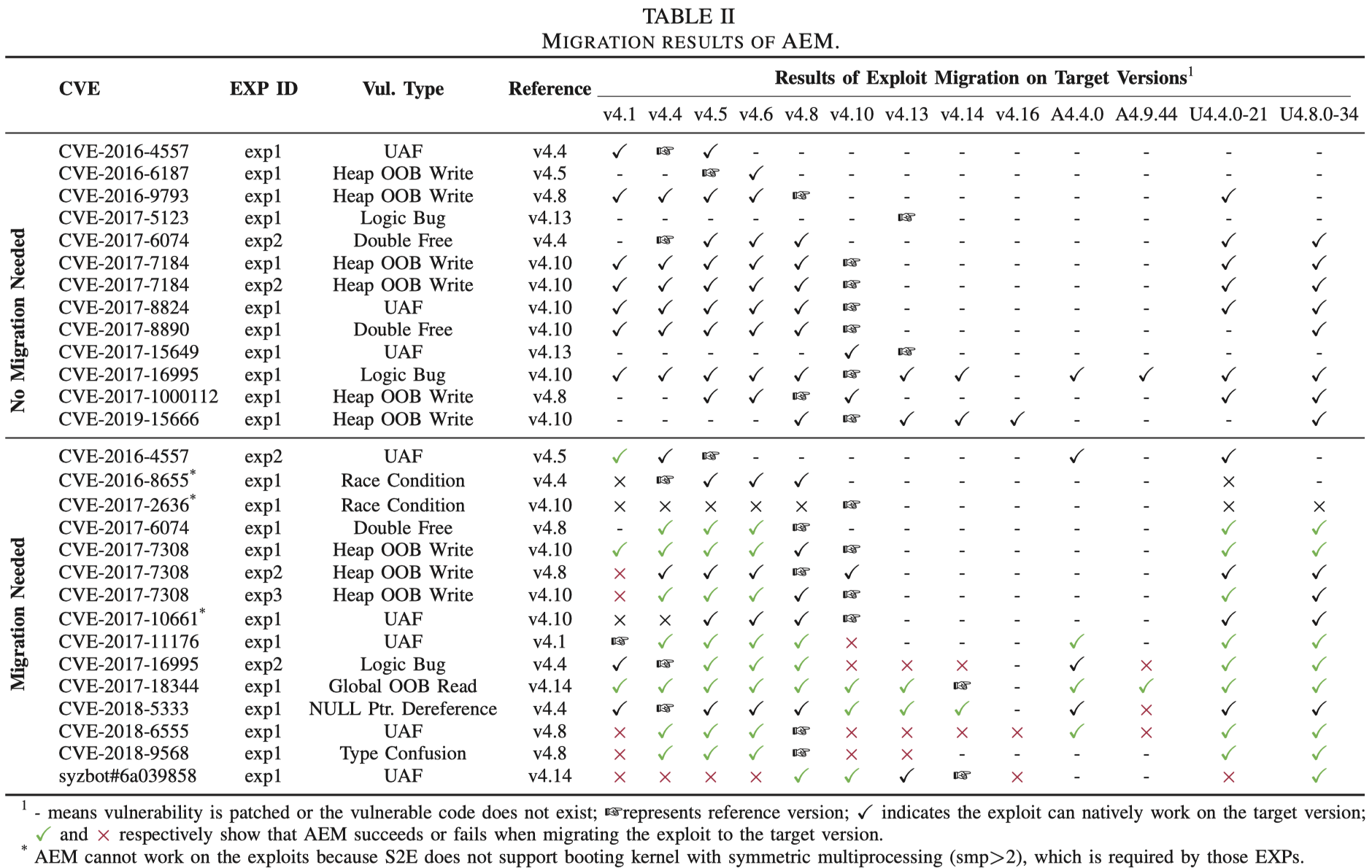
其中,ExP迁移失败的原因主要有两个:一是部分ExP需要在多处理器上运行,而S2E不支持多处理器模式启动内核;二是部分ExP本身属于前文定义的“不可迁移”类型。
作者也统计了AEM的耗时情况,如下表所示:
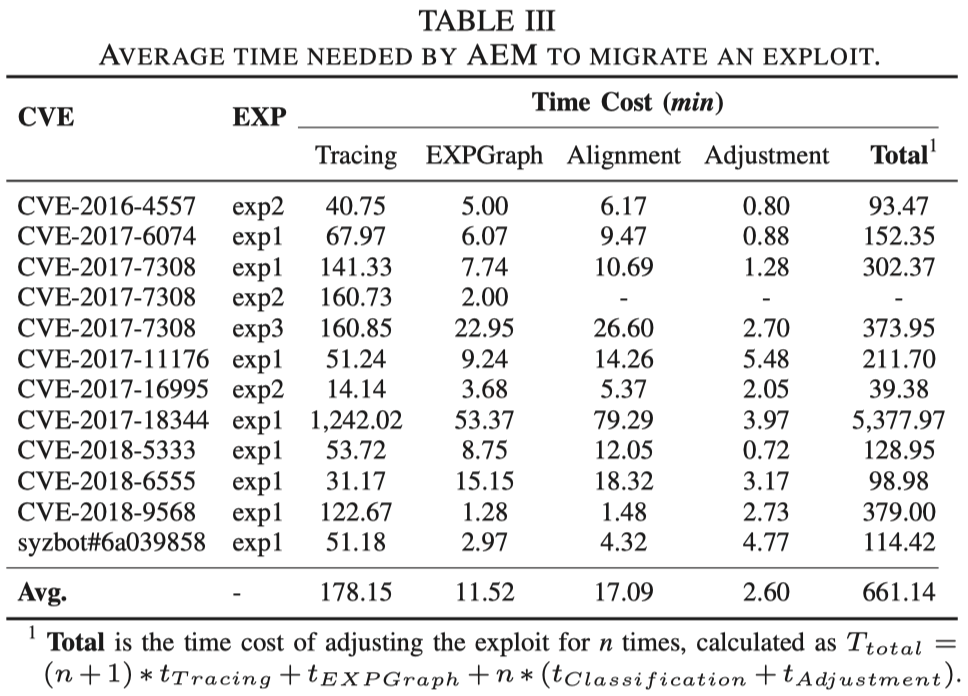
可以看到,迁移一个ExP的平均时间是661分钟,超过10个小时。作者认为这一时间相对来说还是比较长的,与人工分析耗时相当。其中超过84%的时间消耗来源于S2E的执行流追踪。
另外,论文也尝试使用现存的AEG方案(FUZE和KOOBE)完成上述测试,发现效果远差于AEM。
总结
作为首个面向Linux内核跨版本漏洞利用可行性评估的方案,AEM能够以较高的成功率达成目标。其设计与实现相当“硬核”,但非常直观。耗时较长的问题有待进一步优化,但虽然时间成本较高,AEM实现的自动化方案显著降低了技术门槛与专家成本。
另外,AEM目前实现的是漏洞利用原语迁移,不包括后续的攻击意图实现部分。如果想要跨版本自动化迁移一个可用的ExP,还需要考虑实现漏洞利用原语后的迁移工作,如ROP gadgets的迁移等,这部分工作涉及到具体的内核二进制文件中的指令偏移和如何应对诸如KASLR之类的漏洞缓解机制。