1. Basic Information
| Meta | Info |
|---|---|
| Title | SLAKE: Facilitating Slab Manipulation for Exploiting Vulnerabilities in the Linux Kernel |
| Author(s) | Yueqi Chen, Xinyu Xing |
| Institution(s) | The Pennsylvania State University |
| Published in | 2019 ACM SIGSAC Conference on Computer and Communications Security (CCS) |
| Link | CCS'19 | Slides | GitHub Repo |
2. Introduction
To exploit a heap-based Linux kernel vulnerability, the exploit developer has to manipulate slab and craft exploits manually, which is usually a time-consuming and labor-intensive process.
Given a kernel vulnerability, an analyst must (1) learn about what kernel objects and syscalls are useful for this specific exploitation, and (2) how to manipulate the heap to get the desired slab layout.
Some studies have been conducted to facilitate the exploit development process. However, two challenges stymie these studies: (1) many useful kernel objects cannot be allocated through test cases regularly used; (2) the slab layout is very dynamic and non-deterministic because there are many routines in Linux kernel.
This paper proposes a new technique SLAKE (SLAb manipulation for Kernel Exploitation) to facilitate the exploit development work, which contains two parts:
- Perform static and dynamic analysis to identify the objects useful for kernel exploitation and the corresponding syscalls.
- Model commonly adopted kernel exploitation methods to help adjust slab layout and hijack the control flow.
SLAKE is implemented based on LLVM and Syzkaller. Researchers test SLAKE against 27 real-world kernel vulnerabilities (UAF, double free and OOB) and it finds more exploitation ways than those used in public exploits.
Problem Scope: This work focuses on exploitations against kernel vulnerabilities resulting in corruption of memory managed by SLAB/SLUB allocators. You can refer to another post of mine to learn about SLAB/SLUB allocators.
Assumptions: (1) This paper consider the capability of a vulnerability through a PoC program, which could cause kernel panic but not actual exploitation. (2) The capability to control program counter is seen as the exploitability of a vulnerability.
3. Common Kernel Exploitation Approaches
This paper summarizes common kernel exploitation approaches in the background part, making it easier for us to understand their work.
The kernel exploitation is a three-step procedure:
- The attacker figures out the type of the target vulnerability and the capability to manipulate memory given by this vulnerability.
- The attacker determines the specific exploitation approaches to obtain the ability to hijack the control flow.
- The attacker disables or bypasses potential mitigations and protections, and finally reach the goal, e.g., execution of payload or command.
Furthermore, there are four common exploitation approaches:
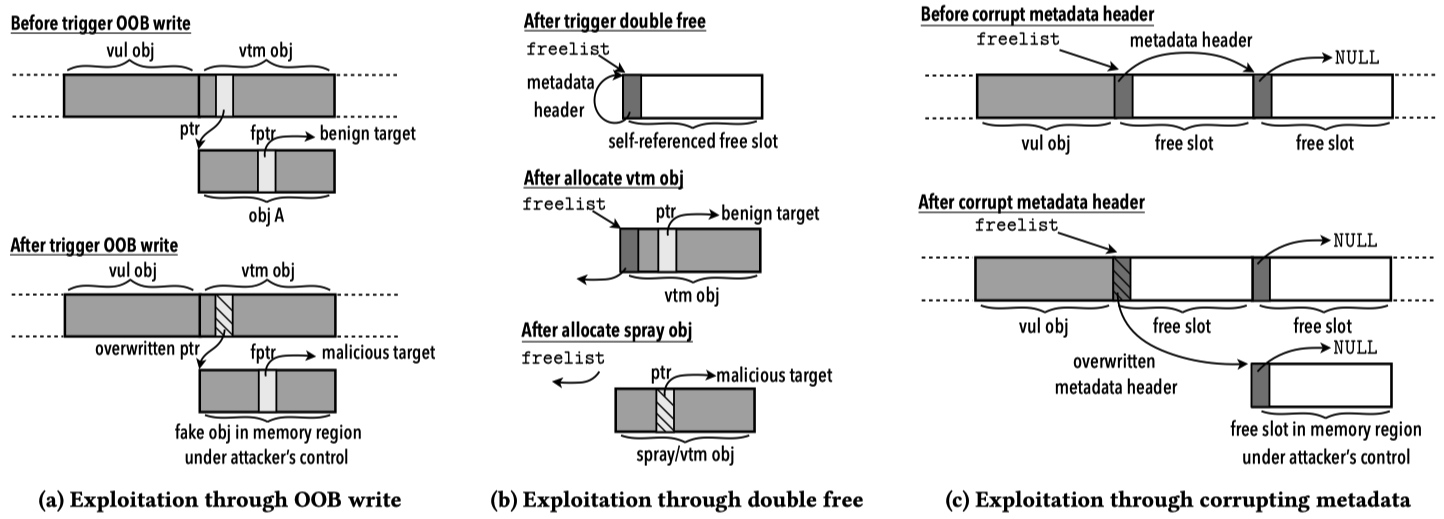
- Manipulation through OOB write. For example, overwrite a function pointer or a data pointer in the adjacent object, and dereference the function pointer or a function pointer within the object through the data pointer. [related post]
- Manipulation through UAF. The exploitation approach is to overlay a spray object on top of the vulnerable object, overwrite the critical data like function or data pointer, and dereference the pointer to trigger the hijacking of control flow. [related post]
- Manipulation through double free. When the double free vulnerability is triggered, the metadata header of a vulnerable object refers to itself. This approach can be divided into some steps. Firstly, select a vicitm object. Second, use the selected object to take over the freed slot via heap spray. Third, select a spray object and allocate one. After the allocation of victim object, the freelist references the victim object. , the attacker can use the spray object to overwrite the pointers within the victim object to hijack the control flow.
- Manipulation through metadata corruption. Besides the metadata corruption in the aforementioned approaches, the attacker can also overwrite the metadata header to trick SLUB allocator into allocating a victim object to a memory region under the attacker’s control.
The OOB, double free and corrupting metadata approaches are demonstrated in the following figure:
4. Key Challenges
Despite the commonly-adopted approaches mentioned above, there are still three challenges:
- Which kernel objects are suitable for exploitation? The kernel object must contain funciton or object pointers, and can be allocated in the same slab of the vulnerable object.
- How to (de)allocate objects and dereference corresponding pointers? Given a target object, the attackers must figure out which syscalls and corresponding arguments can trigger the (de)allocation and dereference of the internal pointers. And the defenders also need the foregoing information to build intrusion signatures.
- How to systematically adjust system calls to obtain the desired slab layout? Even if the attackers know which syscalls and argument to use, it may still be difficult to get the desired slab layout, as the syscalls could have side effects and (de)allocate irrelevant kernel objects to affect the memory layout. Usually, the attackers have to adjust the memory layout manually.
5. Object & Syscall Identification
To tackle the first and second challenges, this paper proposes a new approach.
Firstly, identify types of objects of interest via static analysis. Then pinpoint the objects and sites of interest, where these objects are (de)allocated or corresponding pointers are dereferenced. In this process, record the type name, size and cache of the object, as well as the offest of function/object pointers in each object.
Secondly, SLAKE tracks down syscalls that can (de)allocate and dereference the objects of interest via kernel fuzzing under the guidance of a kernel call graph. To decrease the complexity, SLAKE performs reachability analysis over the call graph to filter out syscalls not able to reach the sites of interest.
5.1 Identify Objects & Sites of Interest
In this part, SLAKE has three tasks: to identify (1) kernel objects critical for exploitation, (2) sites where these objects are (de)allocated, and (3) sites where a function pointer can be dereferenced through an object of interest (the victim object).
1. Identify Critical Objects
Given a kernel vulnerability, two kinds of objects are critical for exploitation. One is the victim object typically used for OOB and double free cases. The other is the spray object used for UAF and double free cases.
A victim object usually contains a function pointer, or recursively contains a function pointer if it contains object pointers. Hence, SLAKE recursively track down each structure and union type in kernel code to find function pointers, except for the linked list fields, for the sake of terminability.
The spray object usually provides attackers with the ability to copy arbitrary data from userland to kernel slab. SLAKE track down spray objects by retriving dst argument of copy_from_user function and examining whether the dst pointer is a return value of slab allocation function like kmalloc and kmem_cache_alloc.
2. Identify (De)allocation Sites
Allocation. The type of return value of allocation functions like kmalloc is always void *, making it hard to know whether this allocation site ties to an object of interest or not. To solve this problem, SLAKE examines the def-use chain of the return value for each allocation function. Only the site of allocation will be taken into consideration where the return value is cast to the type identified.
Deallocation. SLAKE tracks down the deallocation sites tied to victim object by looking at the type of the object pointer passed to deallocation functions like kfree.
3. Identify Dummy Dereference Sites
It is challenging to identify dereference sites in kernel source code through a static interprocedural data flow analysis. So SLAKE first defines and identifies dummy dereferences sites in kernel source code. Then, it tracks down the true dereference sites along with the corresponding system calls via fuzzing and dynamic data flow analysis.
For function dereference through RCU mechanism, the RCU free statements (e.g., kfree_call_rcu and call_rcu_sched) are seen as dummy dereference sites; for non-RCU-related dereference, the dereference of enclosed pointer is seen as dummy dereference sites.
5.2 Finding Syscalls
In this part, SLAKE utilizes an under-context fuzzing approach to identify syscalls and corresponding arguments.
Panic Anchors Setup
Firstly, SLAKE instruments kernel source code to insert panic anchors right behind each site of interest to determine whether a syscall triggers this site of interest during fuzzing. With the help of anchors, addresses of objects allocated, syscalls and their arguments can be recorded as well.
However, as Linux kernel is a highly complex system, there may be some false positives. To address this issue, inside each panic anchor, the kernel variable system_state will be examined, and one termination will be performed only if this value is SYSTEM_RUNNING, which means the kernel is processing a syscall request from userland. The comm field of task_struct is also checked to filter irrelevant processes.
Syscall Identification
To identify syscalls, SLAKE firstly builds a kernel call graph and performs reachability analysis from target (de)allocation and dereference sites. Only the syscalls which do not require the administrative privilege are preserved. Then, SLAKE performs fuzzing against kernel by using a syscall sequence produced from these identified syscalls based on dependency information for object (de)allocation and pointer dereference.
Syscalls for allocation. The specific syscall and related information will be recorded if a test case triggers an anchor site tied to object allocation.
Syscalls for deallocation. The specific syscall and related information will be recorded if a test case triggers an anchor site tied to object deallocation, and the address of deallocation object matches the one logged previously in the allocation stage.
Syscalls for dereference. SLAKE firstly allocated a target object via the syscalls identified. Under this context, it performs kernel fuzzing and explore syscalls which can reach the corresponding dummy dereference site. When a test case triggers the dummy dereference site, SLAKE continues kernel execution and record each of the statements executed until kernel execution exits the current function. Using the execution trace, SLAKE build a use-define chain on which it identifies all the function pointer dereferences, traces back through the chain and examines whether the dereference comes through the allocated victim object.
6. Layout Manipulation
The foregoing steps build a database providing useful informaiton to identify syscalls tied to the (de)allocation and dereference of kernel objects and corresponding pointers. To systematically adjust syscalls and obtain the desired memory layout, SLAKE firstly matches vulnerability capability with corresponding objects, and then uses a layout adjustment approach to manipulate slab for each vulnerability and object pair.
6.1 Matching Vulnerability Capability
To select the proper kernel object for exploitation, the authors first model the capability of a vulnerability and the property of a datat object.
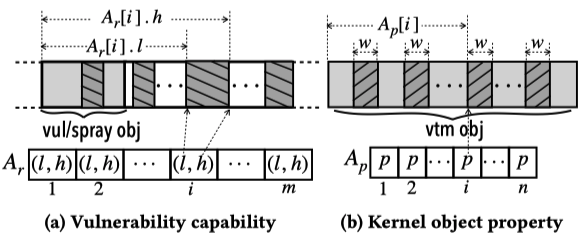
Modeling Vulnerability and Object
Given a vulnerability, the capability of that vulnerability is defined as an array $A_{r}[m]$, which contains $m$ elements, each specifying a memory region under an attacker’s control. Each element contains a pair $(l, h)$ to indicate the start and end offsets corresponding to the base address of a victim or spray object. In between the offsets, an attacker could overwrite data freely.
The property of a kernel object is defined as an array $A_{p}[n]$, which contains $n$ elements, each specifying a memory region where critical data (e.g., pointers and metadata) are located.
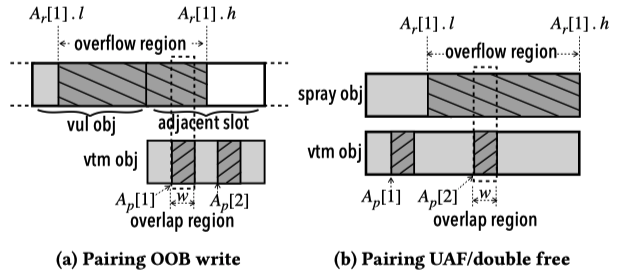
Pairing Vulnerability with Object
Given a vulnerability with an OOB write capability, there are two approaches to performing slab manipulation. One is to overwrite the metadata of a freed object and then allocate a victim object to a memory region under the attacker’s control. The other is to place a victim object adjacent to the vulnerable object and overwrite critical data residing in the victim object. The object selection is based on two criteria: (1) the object must be capable of being allocated in the cache same as the vulnerable object, and (2) a memory region in $A_{p}[n]$ must be within one of the $A_{r}[m]$ region.
The condition for UAF and double free vulnerability is similar to OOB.
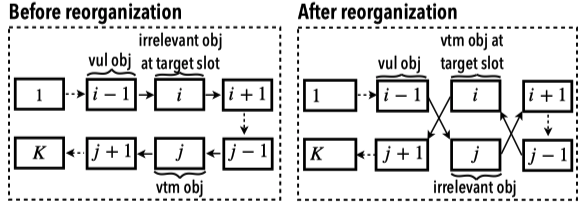
6.2 Adjusting Slab Layout
The authors developed a systematic approach to adjust the slab layout and eliminate the side effects introduced by syscalls, which is composed of two parts: adjusting unoccupied slots and reorganizing occupied slots.
7. Implementation, Experiment and Evaluation
Implementation
The static analysis part of SLAKE is based on LLVM IR. The first LLVM pass is built for identifying the objects and the sites of the interest. The second LLVM pass is the extension of an existing tool KINT, which is used to construct kernel call graph.
For the dynamic analysis part, the authors wrote a GCC plugin to implant panic anchors into Linux kernel. And they extended the Linux kernel fuzzing tool Syzkaller with the integration of Moonshine to perform fuzz testing against the instrumented Linux kernel.
The authors also developed a GDB python script, which runs a Linux kernel on QEMU and sets breakpoints on the dereference anchors, so as to truly pinpoint a function pointer dereference and ensure the dereference of that pointer is through a victim object.
Experiment and Evaluation
The objects of interest SLAKE identified are shown as below:

The exploitation status of 27 kernel vulnerabilities is shown as below:
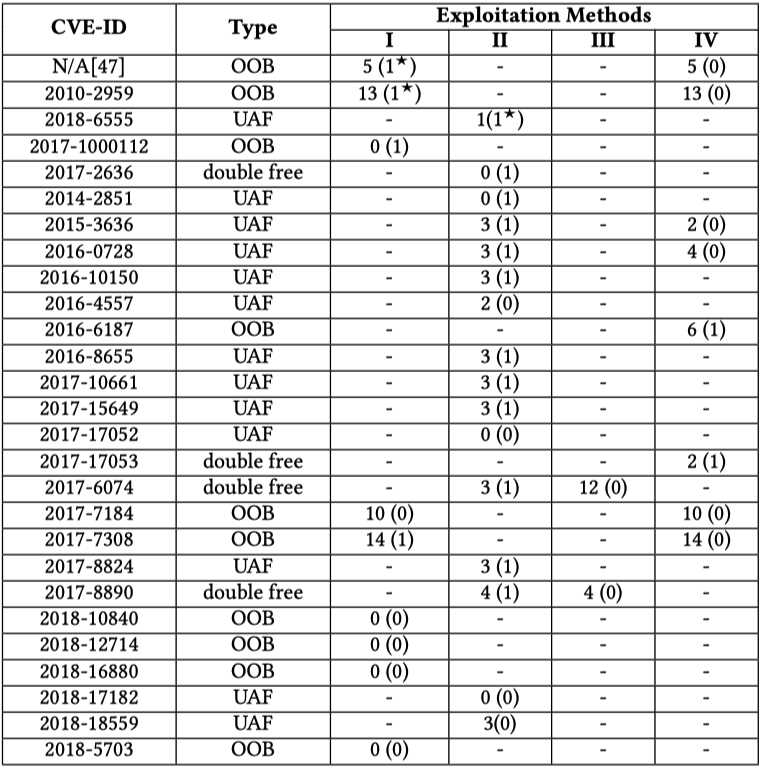
The numbers within parentheses indicate the total amount of exploits publicly available and those out of parentheses represent the amount of exploits generated through SLAKE.
8. Summary
As the authors say, SLAKE and its ideas can be applied against other operating systems, allocators, exploitation methods and vulnerability capabilities.
For me, I will try to apply the results of this paper in real-world kernel vulnerability exploitations. It is great to know that there are lots of useful kernel objects and learn how to use them from the GitHub Repo.