1. Basic Information
| Meta | Info |
|---|---|
| Title | Your Exploit is Mine: Automatic Shellcode Transplant for Remote Exploits |
| Author(s) | Tiffany Bao, Ruoyu Wang, Yan Shoshitaishvili, David Brumley |
| Institution(s) | Carnegie Mellon University & UC Santa Barbara |
| Published in | 2017 IEEE Symposium on Security and Privacy (IEEE S&P) |
| Link | IEEE Xplore |
Two years ago, I wrote an article about ForAllSecure and their Mayhem from RSAC Sandbox 2020. In December 2022, I read a paper about automated exploit migration (AEM, you can find my note here), which has much relationship with automated exploit generation (AEG) and automatic shellcode transplant talked in the paper I will talk about. All these things are related to automatic exploitation to some extent, which is a very attractive research field.
2. Introduction
Usually, development of a remote exploit is not an easy thing, while it is much easier to reuse an existing exploit with just necessary changes, e.g., replacement of the original shellcode, also named as shellcode transplant.
Shellcode transplant has lots of applications in different defensive and offensive scenarios, while current techniques require much analysis and debugging work of analysts. Researchers identified three main challenges of shellcode transplant problem:
- It is difficult to separate shellcode from the rest of an exploit because of no clear boundary.
- Shellcode is always constructed through non-trivial data transformations.
- Shellcode and the remainder of exploit can be interdependent.
Previous work tends to enumerate all possible offsets in every attacker-controlled buffer, which is insufficient, which would end in path explosion problem or limited by the inability of symbolic execution engine.
In this paper, researchers designed a system named ShellSwap, which utilizes symbolic tracing, with a combination of shellcode layout remediation and path kneading to achieve shellcode transplant. ShellSwap focuses on exploits against control-flow hijacking vulnerabilites.
By utilizing information from the original exploit and transforming the replacement shellcode, ShellSwap rarely degrades to a pure symbolic exploration, and is thus more efficient and effective compared to previous solutions. ShellSwap succeeded in generating 88 exploits among 100 test cases.
3. Overview
ShellSwap takes a vulnerable program, an existing exploit and a specified replacement shellcode as input, then generate a modified exploit targeting the same vulnerability but executing the new shellcode after exploitation.
A successful control flow hijacking exploit consists of two phases:
- Before the hijack, the program state is carefully set up to enable the hijack.
- After the hijack, the injected shellcode executes.
Researchers define the program state after the first phase as the exploitable state, and the instruction sequence executed by the program until the eploitable state as the exploit path. Following this definition, the new modified exploit would share the same exploit path with the original exploit in the first phase, but have new shellcode in the second phase.
The architecture of ShellSwap is shown as below:
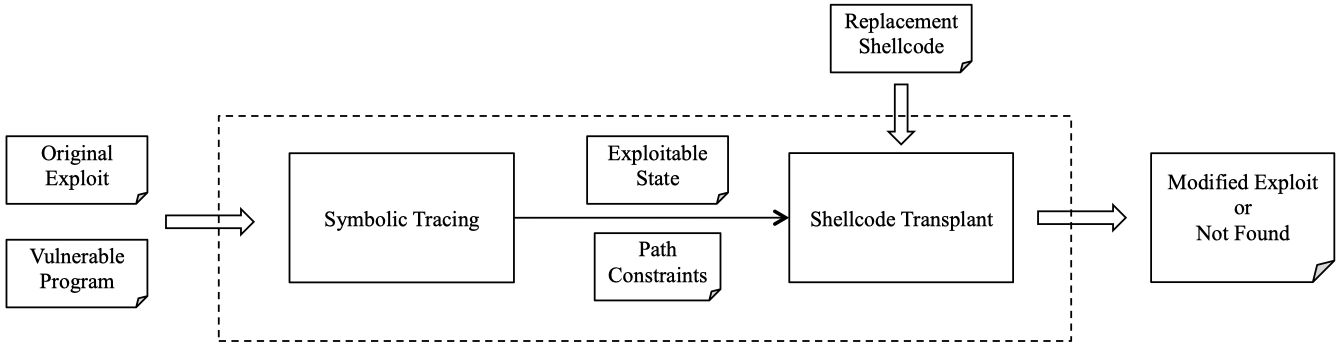
There are two steps in ShellSwap:
- Symbolic Tracing. The original exploit will be replayed and the executed instrucitons will be recorded as a sequence of instruction addresses. Then a tracer will set the input from the exploit as a symbolic value and starts symbolically executing the program. At every step of this execution, the tracer checks if the current program state violates a security policy. The path constraints introduced by the program on the exploit input in order to reach the exploitable state and the memory contents of the exploitable state itself will be recorded.
- Shellcode Transplant. This step taks the exploitable state, the path constraints and the replacement shellcode as input, then try to generate a modified exploit.
Researchers show a buffer overflow example in this paper to help demonstrate the challenges of shellcode transplant:
int example() {
int len = 0;
char string[20];
int i;
if (receive_delim(0, string, 50, '\n') != 0)
return -1;
if (string[0] == '^')
_terminate(0);
for (i = 0; string[i] != '\0'; i++)
len++;
return len;
}
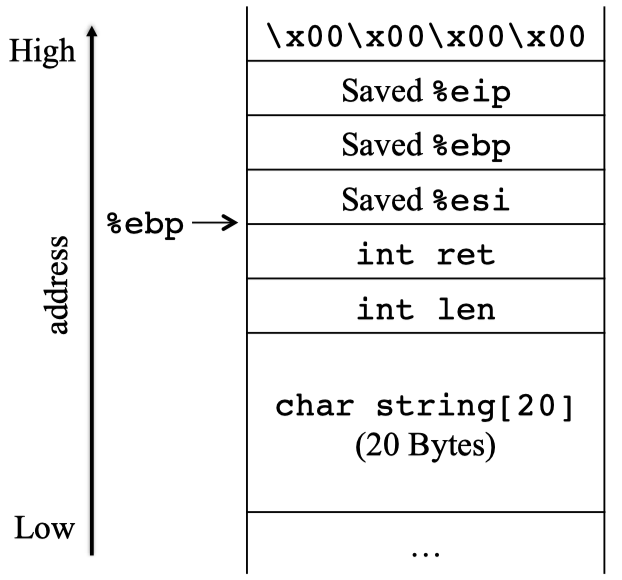
The stack layout of this function would be like:
The original exploit with shellcode is shown as below:
shellcode = "\x31\xc0\x40\x40\x89\x45\xdc"
exploit = shellcode + "\x90" * (36 - len(shellcode)) + "\x50\xaf\xaa\xba\n"
Based on this example, there are mainly two categories of challenges for shellcode transplanting:
- Memory conflicts. When dealing with fine-tuned exploits, there may be not enough symbolic data in the state to concretize to shellcode. As in the example above, the 20th through the 28th byte will be overwritten by the program after the shellcode is injected, and the 36th through 40th byte must be set to the address of the shellcode (to redirect control flow). This leaves three symbolic regions, none of which is enough to place the whole shellcode, causing a memory conflict.
- Path conflicts. To drive program execution to the exploited state, the content of the modified exploit must satisfy the path constraints recovered from the Symbolic Tracing step. However, by requiring the replacement shellcode to be in the memory of the exploitation state, new constraints (“shellcode constraints”) need to be added on the exploit input. These new conditions may be conflict with those generated along the path. As in the example above, the
forloop would stop if the replacement shellcode contains\0in the first 40 bytes, which violates the path constraints, as the loop of the original exploit will take 40 iterations.
4. Symbolic Tracing
In the symbolic tracing step, there are two main tasks:
- Determine when the control-flow hijack occurs. Researchers use taint-based enforceable security policy to do this: If the instruction directly is tainted by remote input, then the program state is deemed unsafe and the path is terminated.
- Determine how to perform the tracing. Researchers apply concolic execution to trace the exploit path. The tracing accuracy is ensured in two ways:
- Record a dynamic trace of exploit process.
- Pre-constrain the symbolic data to be equal to the original exploit.
5. Shellcode Transplant
After the exploitable state and the path constraints associated with it have been recovered, ShellSwap can attempt to reconstrain the shellcode to be equal to the replacement shellcode by adding shellcode constraints.
This step proceeds in several phases in a loop, shown as below:
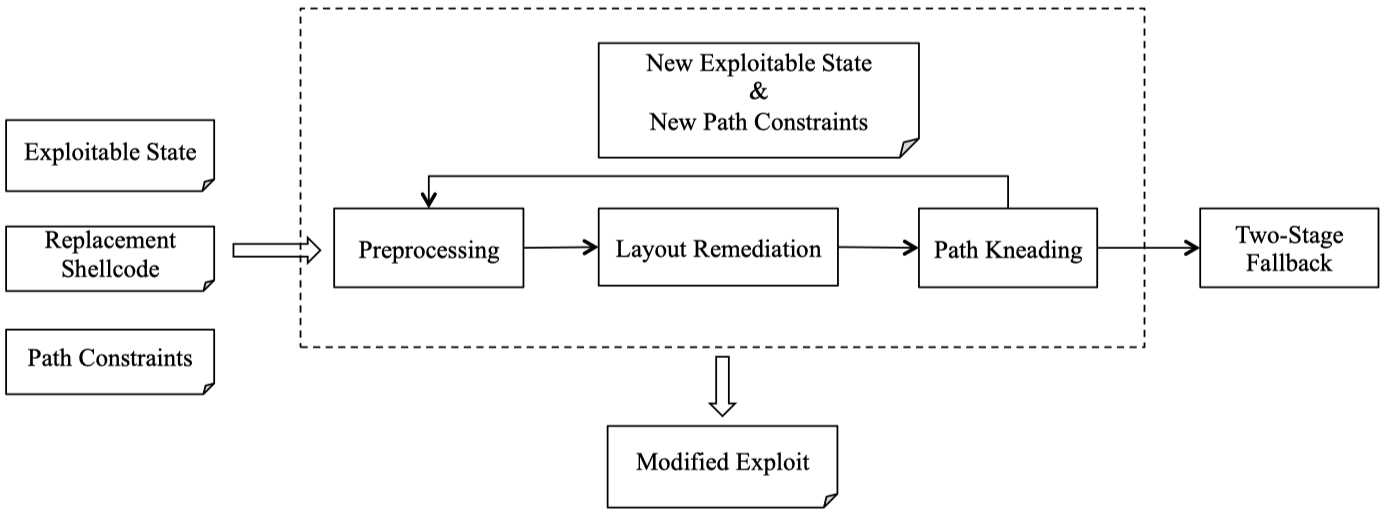
In the Preprocessing phase, ShellSwap identifies possible memory locations into which replacement shellcode (or pieces of it) can be placed.
Next, in the Layout Remediation phase, it attempts to remedy memory conflicts and fit the replacement shellcode into the identified memory locations, performing semantics-preserving modifications (such as code splitting) if necessary.
If this fails due to a resulting conflict with the path constraints, ShellSwap enters the Path Kneading phase and attempts to identify alternate paths that resolve these conflicts while still triggering the vulnerability. If such a path can be found, its constraints replace the path constraints, and the system repeats from the preprocessing phase.
If ShellSwap encounters a situation where neither the memory conflicts nor the path conflicts can be remedied, it triggers the Two-Stage Fallback and attempts to repeat the Shellcode Transplant stage with a fallback, two-stage shellcode.
5.1 Preprocessing
ShellSwap scans the memory in the exploitable state to identify symbolic buffers.
5.2 Layout Remediation
ShellSwap does not consider a piece of shellcode as an integrated memory chunk. Instead, the new shellcode is modeled as a sequence of instructions. It is not necessary to keep these instructions contiguous; jmp instructions will be inserted to “hop” from one shellcode instruction in one symbolic buffer to another instruction in another buffer.
Researchers design an algorithm to achieve this goal. The layout remediation process for the example program is shown as below:
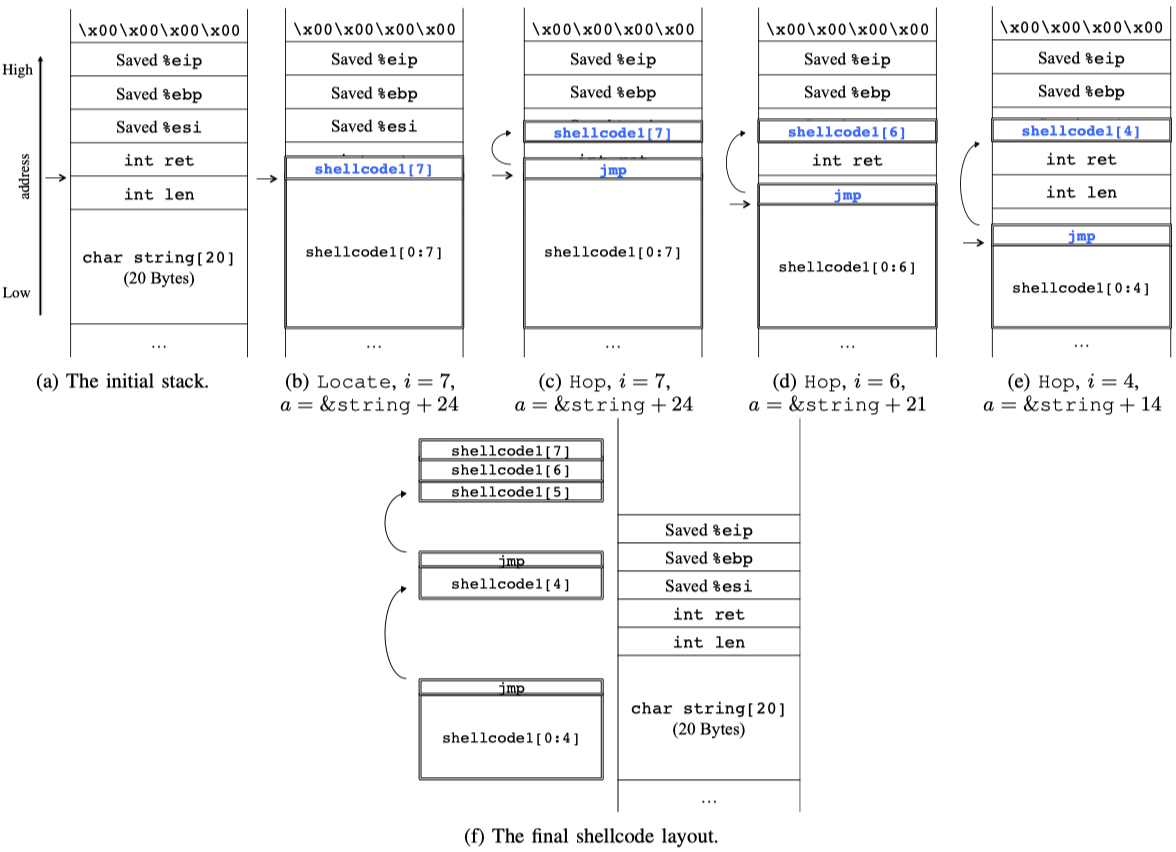
5.3 Path Kneading
To diagnose the cause of conflict, ShellSwap first identify the conflicting path constraints and then check which instructions generated them.
After finding the conflict subset, ShellSwap identifies the source of each constraint in this subset by checking the execution history for when it was introduced. If the conflicting constraint was introduced by condition branch, ShellSwap will tweak the path to avoid the path constraints in the conflict subset. If the shellcode constraint contradicts a path constraint, then the shellcode constraint does not contradict the negation of that path constraint.
Then, ShellSwap will try to generate a new path:

If there is no such path to rejoin the original path, or that the problem reduces to symbolic exploration (if the divergence is too big), ShellSwap falls back on the Two-Stage Fallback.
5.4 Two-Stage Fallback
If ShellSwap is unable to overcome the memory and path conflicts and fit the replacement shellcode into the exploitable state, then it falls back on pre-defined a two-stage shellcode instead of the provided replacement shellcode.
Researchers implemented a stack-based shellcode-loading first-stage payload that reads a second-stage payload onto the stack and jumps into it. This payload is special as there is no \0.
6. Implementation and Evaluation
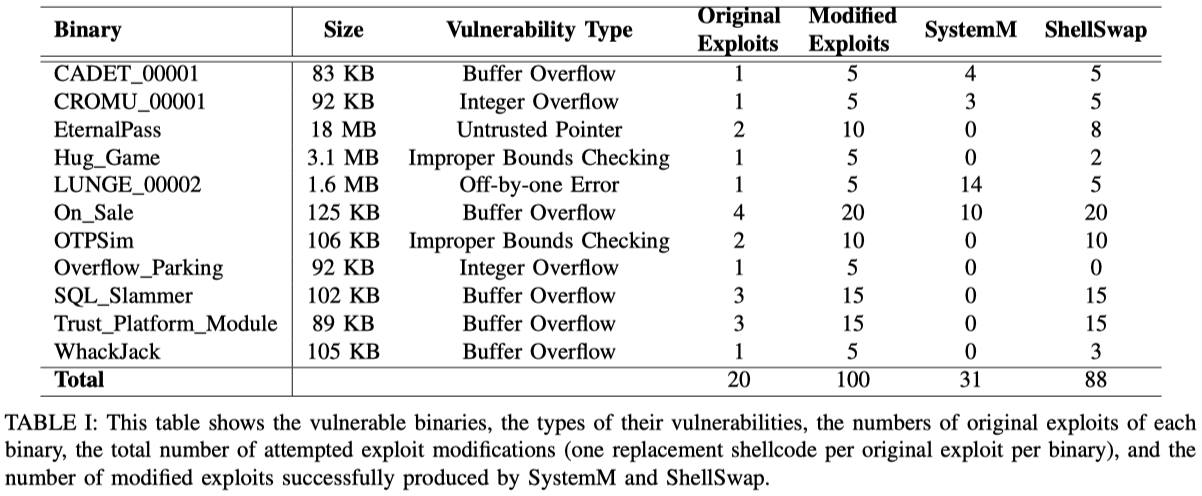
ShellSwap is implemented on top of angr. The date set is gathered from DARPA Cyber Grand Challenge.
As a result, ShellSwap generated 57 exploits using only Layout Remediation and 31 more by leveraging Path Kneading. Only 57% of all cases are successfully replaced with new shellcode without Path Kneading, which demonstrates the importance of conflict identification and kneading of the exploit path during shellcode replacement.
The experiment’s statistics:
7. Summary
This is an interesting research. Automation of exploit is gradually becoming one of the important topics in cyber security, as it can reduce the threshold of exploit development.
BTW, I am still learning how to read papers and write reading notes by reading and writing. Gradually, I find that the easiest way to organize your note for a specific paper is to follow the architecture of the target paper. Follow the same architecture, but shorten and summarize it :-)